 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQingguo Chen
The Solution for the CVPR2024 NICE Image Captioning Challenge
Apr 19, 2024

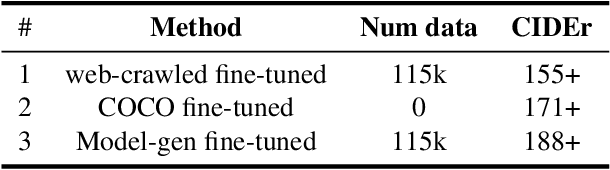
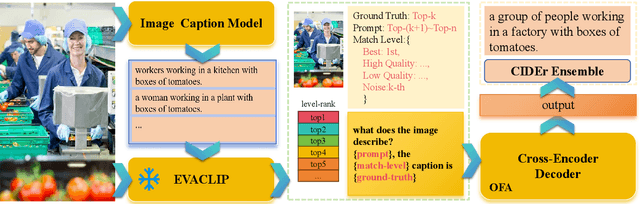
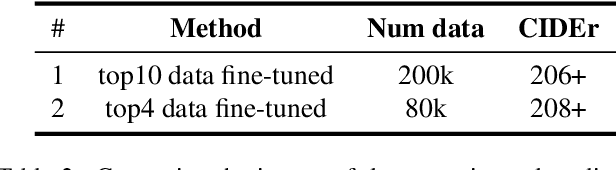
This report introduces a solution to the Topic 1 Zero-shot Image Captioning of 2024 NICE : New frontiers for zero-shot Image Captioning Evaluation. In contrast to NICE 2023 datasets, this challenge involves new annotations by humans with significant differences in caption style and content. Therefore, we enhance image captions effectively through retrieval augmentation and caption grading methods. At the data level, we utilize high-quality captions generated by image caption models as training data to address the gap in text styles. At the model level, we employ OFA (a large-scale visual-language pre-training model based on handcrafted templates) to perform the image captioning task. Subsequently, we propose caption-level strategy for the high-quality caption data generated by the image caption models and integrate them with retrieval augmentation strategy into the template to compel the model to generate higher quality, more matching, and semantically enriched captions based on the retrieval augmentation prompts. Our approach ranks first on the leaderboard, achieving a CIDEr score of 234.11 and 1st in all other metrics.
Better Fit: Accommodate Variations in Clothing Types for Virtual Try-on
Mar 13, 2024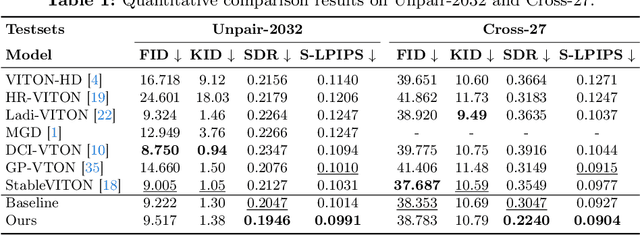
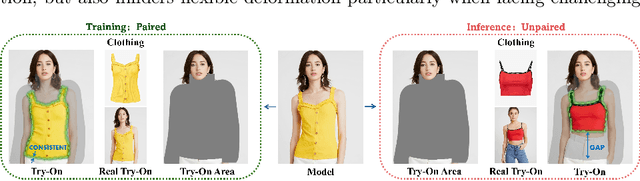
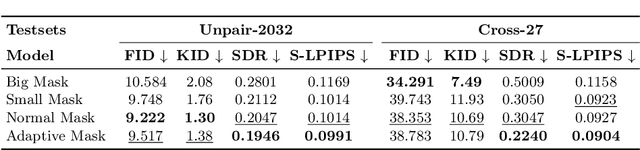
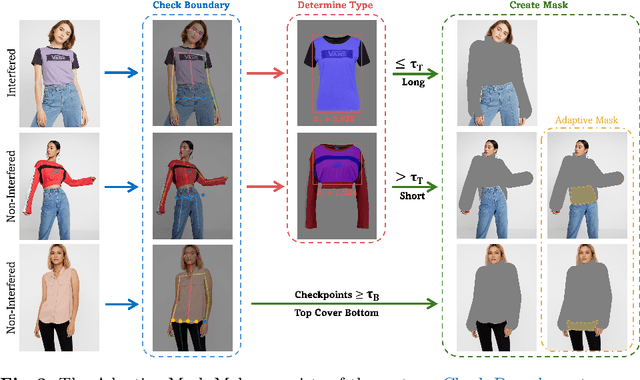
Image-based virtual try-on aims to transfer target in-shop clothing to a dressed model image, the objectives of which are totally taking off original clothing while preserving the contents outside of the try-on area, naturally wearing target clothing and correctly inpainting the gap between target clothing and original clothing. Tremendous efforts have been made to facilitate this popular research area, but cannot keep the type of target clothing with the try-on area affected by original clothing. In this paper, we focus on the unpaired virtual try-on situation where target clothing and original clothing on the model are different, i.e., the practical scenario. To break the correlation between the try-on area and the original clothing and make the model learn the correct information to inpaint, we propose an adaptive mask training paradigm that dynamically adjusts training masks. It not only improves the alignment and fit of clothing but also significantly enhances the fidelity of virtual try-on experience. Furthermore, we for the first time propose two metrics for unpaired try-on evaluation, the Semantic-Densepose-Ratio (SDR) and Skeleton-LPIPS (S-LPIPS), to evaluate the correctness of clothing type and the accuracy of clothing texture. For unpaired try-on validation, we construct a comprehensive cross-try-on benchmark (Cross-27) with distinctive clothing items and model physiques, covering a broad try-on scenarios. Experiments demonstrate the effectiveness of the proposed methods, contributing to the advancement of virtual try-on technology and offering new insights and tools for future research in the field. The code, model and benchmark will be publicly released.
Solution for SMART-101 Challenge of ICCV Multi-modal Algorithmic Reasoning Task 2023
Oct 10, 2023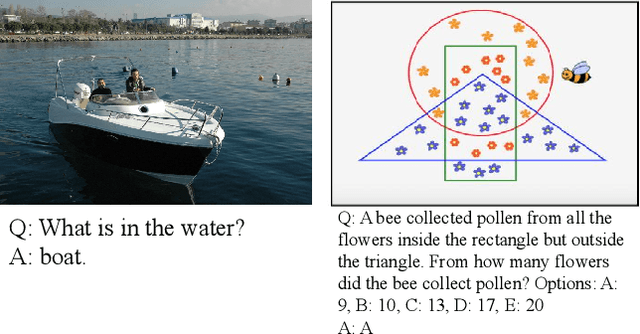
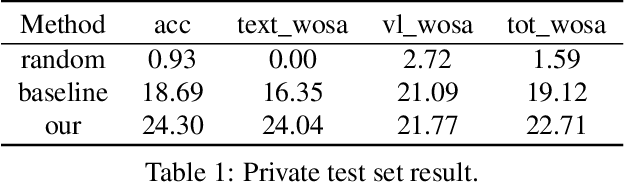
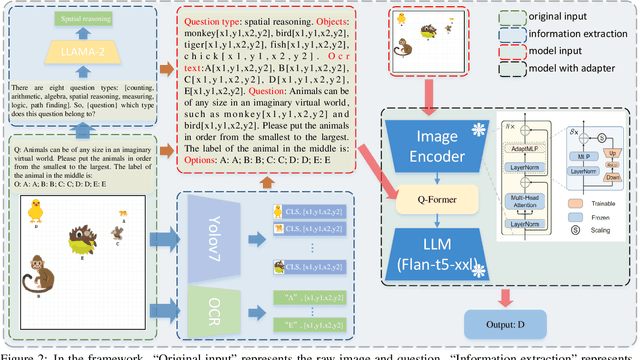
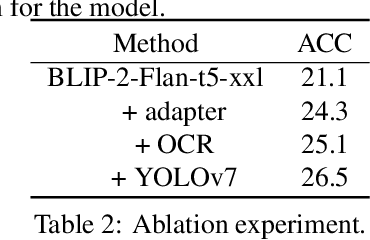
In this paper, we present our solution to a Multi-modal Algorithmic Reasoning Task: SMART-101 Challenge. Different from the traditional visual question-answering datasets, this challenge evaluates the abstraction, deduction, and generalization abilities of neural networks in solving visuolinguistic puzzles designed specifically for children in the 6-8 age group. We employed a divide-and-conquer approach. At the data level, inspired by the challenge paper, we categorized the whole questions into eight types and utilized the llama-2-chat model to directly generate the type for each question in a zero-shot manner. Additionally, we trained a yolov7 model on the icon45 dataset for object detection and combined it with the OCR method to recognize and locate objects and text within the images. At the model level, we utilized the BLIP-2 model and added eight adapters to the image encoder VIT-G to adaptively extract visual features for different question types. We fed the pre-constructed question templates as input and generated answers using the flan-t5-xxl decoder. Under the puzzle splits configuration, we achieved an accuracy score of 26.5 on the validation set and 24.30 on the private test set.