 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHailiang Zhang
The Solution for the CVPR2023 NICE Image Captioning Challenge
Oct 10, 2023


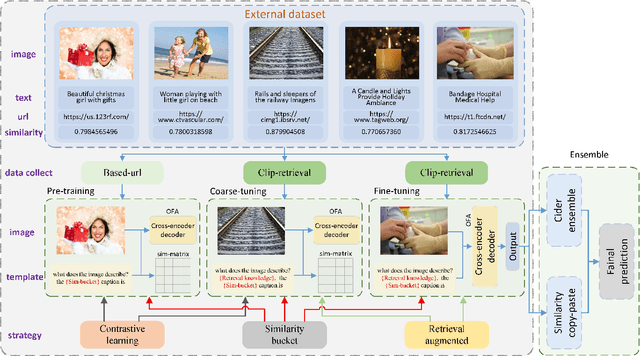
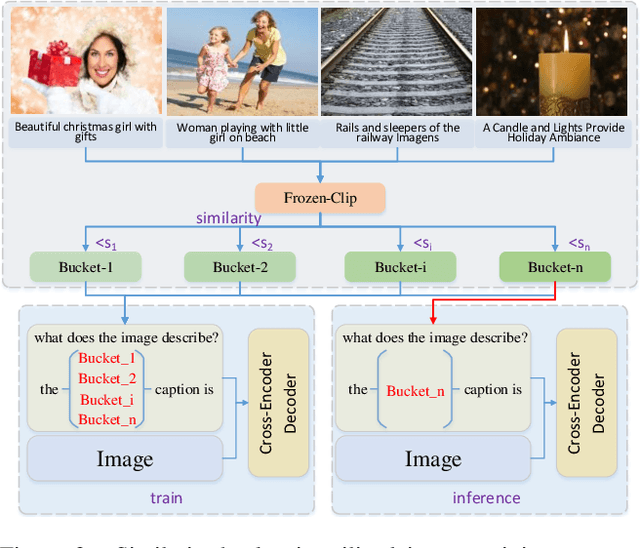
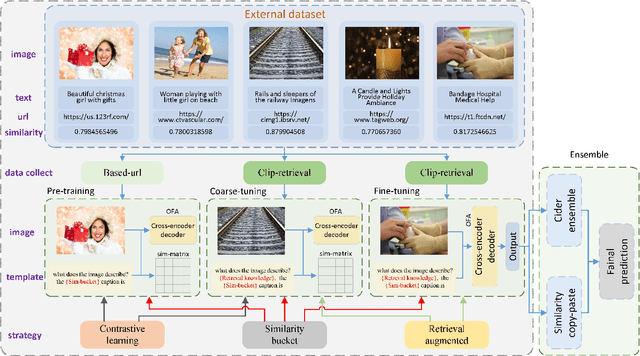
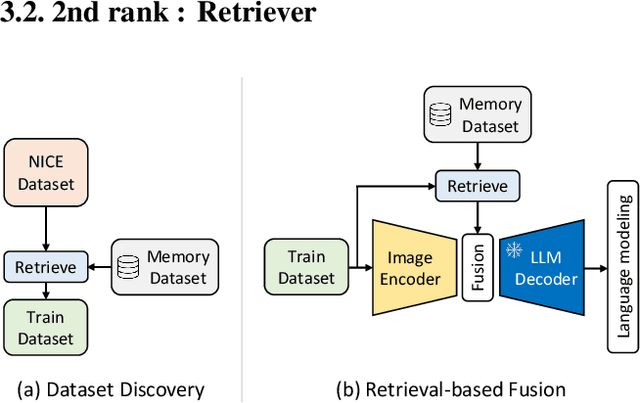
In this paper, we present our solution to the New frontiers for Zero-shot Image Captioning Challenge. Different from the traditional image captioning datasets, this challenge includes a larger new variety of visual concepts from many domains (such as COVID-19) as well as various image types (photographs, illustrations, graphics). For the data level, we collect external training data from Laion-5B, a large-scale CLIP-filtered image-text dataset. For the model level, we use OFA, a large-scale visual-language pre-training model based on handcrafted templates, to perform the image captioning task. In addition, we introduce contrastive learning to align image-text pairs to learn new visual concepts in the pre-training stage. Then, we propose a similarity-bucket strategy and incorporate this strategy into the template to force the model to generate higher quality and more matching captions. Finally, by retrieval-augmented strategy, we construct a content-rich template, containing the most relevant top-k captions from other image-text pairs, to guide the model in generating semantic-rich captions. Our method ranks first on the leaderboard, achieving 105.17 and 325.72 Cider-Score in the validation and test phase, respectively.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023
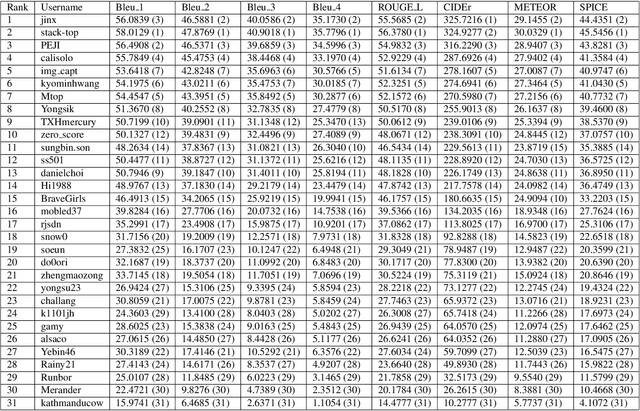
In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
A Spatial Calibration Method for Robust Cooperative Perception
Apr 25, 2023



Cooperative perception is a promising technique for enhancing the perception capabilities of automated vehicles through vehicle-to-everything (V2X) cooperation, provided that accurate relative pose transforms are available. Nevertheless, obtaining precise positioning information often entails high costs associated with navigation systems. Moreover, signal drift resulting from factors such as occlusion and multipath effects can compromise the stability of the positioning information. Hence, a low-cost and robust method is required to calibrate relative pose information for multi-agent cooperative perception. In this paper, we propose a simple but effective inter-agent object association approach (CBM), which constructs contexts using the detected bounding boxes, followed by local context matching and global consensus maximization. Based on the matched correspondences, optimal relative pose transform is estimated, followed by cooperative perception fusion. Extensive experimental studies are conducted on both the simulated and real-world datasets, high object association precision and decimeter level relative pose calibration accuracy is achieved among the cooperating agents even with larger inter-agent localization errors. Furthermore, the proposed approach outperforms the state-of-the-art methods in terms of object association and relative pose estimation accuracy, as well as the robustness of cooperative perception against the pose errors of the connected agents. The code will be available at https://github.com/zhyingS/CBM.
An Efficient and Robust Object-Level Cooperative Perception Framework for Connected and Automated Driving
Oct 12, 2022



Cooperative perception is challenging for connected and automated driving because of the real-time requirements and bandwidth limitation, especially when the vehicle location and pose information are inaccurate. We propose an efficient object-level cooperative perception framework, in which data of the 3D bounding boxes, location, and pose are broadcast and received between the connected vehicles, then fused at the object level. Two Iterative Closest Point (ICP) and Optimal Transport theory-based matching algorithms are developed to maximize the total correlations between the 3D bounding boxes jointly detected by the vehicles. Experiment results show that it only takes 5ms to associate objects from different vehicles for each frame, and robust performance is achieved for different levels of location and heading errors. Meanwhile, the proposed framework outperforms the state-of-the-art benchmark methods when location or pose errors occur.