 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByungseok Roh
CheX-GPT: Harnessing Large Language Models for Enhanced Chest X-ray Report Labeling
Jan 21, 2024
Free-text radiology reports present a rich data source for various medical tasks, but effectively labeling these texts remains challenging. Traditional rule-based labeling methods fall short of capturing the nuances of diverse free-text patterns. Moreover, models using expert-annotated data are limited by data scarcity and pre-defined classes, impacting their performance, flexibility and scalability. To address these issues, our study offers three main contributions: 1) We demonstrate the potential of GPT as an adept labeler using carefully designed prompts. 2) Utilizing only the data labeled by GPT, we trained a BERT-based labeler, CheX-GPT, which operates faster and more efficiently than its GPT counterpart. 3) To benchmark labeler performance, we introduced a publicly available expert-annotated test set, MIMIC-500, comprising 500 cases from the MIMIC validation set. Our findings demonstrate that CheX-GPT not only excels in labeling accuracy over existing models, but also showcases superior efficiency, flexibility, and scalability, supported by our introduction of the MIMIC-500 dataset for robust benchmarking. Code and models are available at https://github.com/kakaobrain/CheXGPT.
Honeybee: Locality-enhanced Projector for Multimodal LLM
Dec 11, 2023In Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the visual projector, it has been relatively less explored. In this study, we first identify two essential projector properties: (i) flexibility in managing the number of visual tokens, crucial for MLLMs' overall efficiency, and (ii) preservation of local context from visual features, vital for spatial understanding. Based on these findings, we propose a novel projector design that is both flexible and locality-enhanced, effectively satisfying the two desirable properties. Additionally, we present comprehensive strategies to effectively utilize multiple and multifaceted instruction datasets. Through extensive experiments, we examine the impact of individual design choices. Finally, our proposed MLLM, Honeybee, remarkably outperforms previous state-of-the-art methods across various benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench, achieving significantly higher efficiency. Code and models are available at https://github.com/kakaobrain/honeybee.
Learning Pseudo-Labeler beyond Noun Concepts for Open-Vocabulary Object Detection
Dec 04, 2023Open-vocabulary object detection (OVOD) has recently gained significant attention as a crucial step toward achieving human-like visual intelligence. Existing OVOD methods extend target vocabulary from pre-defined categories to open-world by transferring knowledge of arbitrary concepts from vision-language pre-training models to the detectors. While previous methods have shown remarkable successes, they suffer from indirect supervision or limited transferable concepts. In this paper, we propose a simple yet effective method to directly learn region-text alignment for arbitrary concepts. Specifically, the proposed method aims to learn arbitrary image-to-text mapping for pseudo-labeling of arbitrary concepts, named Pseudo-Labeling for Arbitrary Concepts (PLAC). The proposed method shows competitive performance on the standard OVOD benchmark for noun concepts and a large improvement on referring expression comprehension benchmark for arbitrary concepts.
Large Language Models are Temporal and Causal Reasoners for Video Question Answering
Nov 06, 2023Large Language Models (LLMs) have shown remarkable performances on a wide range of natural language understanding and generation tasks. We observe that the LLMs provide effective priors in exploiting $\textit{linguistic shortcuts}$ for temporal and causal reasoning in Video Question Answering (VideoQA). However, such priors often cause suboptimal results on VideoQA by leading the model to over-rely on questions, $\textit{i.e.}$, $\textit{linguistic bias}$, while ignoring visual content. This is also known as `ungrounded guesses' or `hallucinations'. To address this problem while leveraging LLMs' prior on VideoQA, we propose a novel framework, Flipped-VQA, encouraging the model to predict all the combinations of $\langle$V, Q, A$\rangle$ triplet by flipping the source pair and the target label to understand their complex relationships, $\textit{i.e.}$, predict A, Q, and V given a VQ, VA, and QA pairs, respectively. In this paper, we develop LLaMA-VQA by applying Flipped-VQA to LLaMA, and it outperforms both LLMs-based and non-LLMs-based models on five challenging VideoQA benchmarks. Furthermore, our Flipped-VQA is a general framework that is applicable to various LLMs (OPT and GPT-J) and consistently improves their performances. We empirically demonstrate that Flipped-VQA not only enhances the exploitation of linguistic shortcuts but also mitigates the linguistic bias, which causes incorrect answers over-relying on the question. Code is available at https://github.com/mlvlab/Flipped-VQA.
CXR-CLIP: Toward Large Scale Chest X-ray Language-Image Pre-training
Oct 20, 2023A large-scale image-text pair dataset has greatly contributed to the development of vision-language pre-training (VLP) models, which enable zero-shot or few-shot classification without costly annotation. However, in the medical domain, the scarcity of data remains a significant challenge for developing a powerful VLP model. In this paper, we tackle the lack of image-text data in chest X-ray by expanding image-label pair as image-text pair via general prompt and utilizing multiple images and multiple sections in a radiologic report. We also design two contrastive losses, named ICL and TCL, for learning study-level characteristics of medical images and reports, respectively. Our model outperforms the state-of-the-art models trained under the same conditions. Also, enlarged dataset improve the discriminative power of our pre-trained model for classification, while sacrificing marginal retrieval performance. Code is available at https://github.com/kakaobrain/cxr-clip.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023
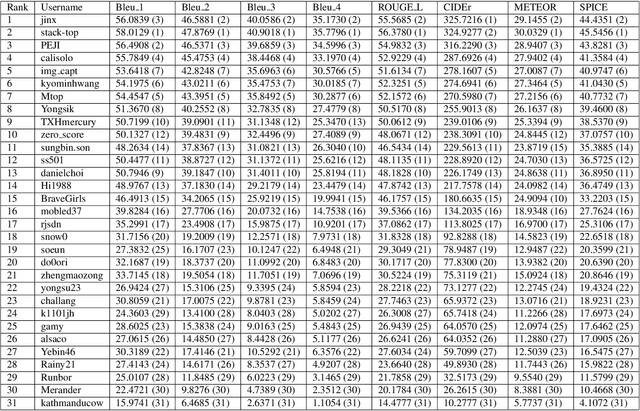
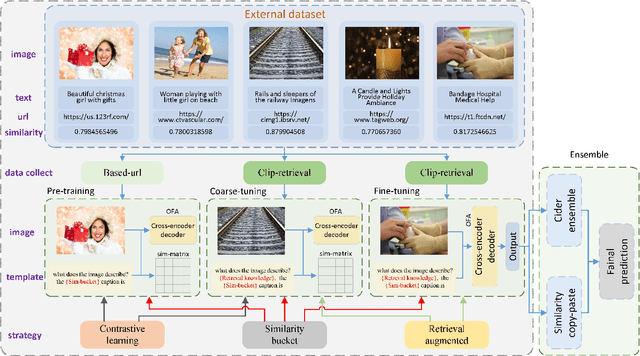
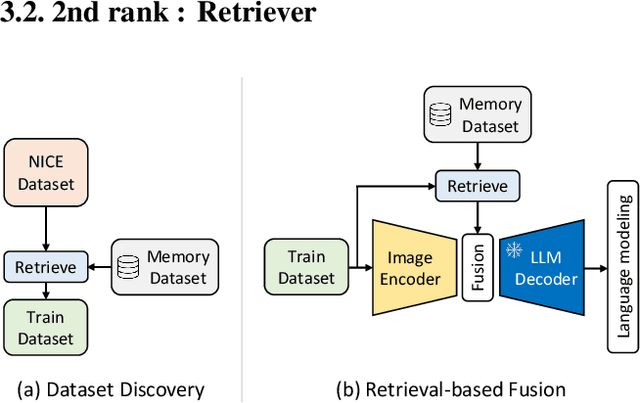
In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
MELTR: Meta Loss Transformer for Learning to Fine-tune Video Foundation Models
Mar 23, 2023



Foundation models have shown outstanding performance and generalization capabilities across domains. Since most studies on foundation models mainly focus on the pretraining phase, a naive strategy to minimize a single task-specific loss is adopted for fine-tuning. However, such fine-tuning methods do not fully leverage other losses that are potentially beneficial for the target task. Therefore, we propose MEta Loss TRansformer (MELTR), a plug-in module that automatically and non-linearly combines various loss functions to aid learning the target task via auxiliary learning. We formulate the auxiliary learning as a bi-level optimization problem and present an efficient optimization algorithm based on Approximate Implicit Differentiation (AID). For evaluation, we apply our framework to various video foundation models (UniVL, Violet and All-in-one), and show significant performance gain on all four downstream tasks: text-to-video retrieval, video question answering, video captioning, and multi-modal sentiment analysis. Our qualitative analyses demonstrate that MELTR adequately `transforms' individual loss functions and `melts' them into an effective unified loss. Code is available at https://github.com/mlvlab/MELTR.
Open-Vocabulary Object Detection using Pseudo Caption Labels
Mar 23, 2023



Recent open-vocabulary detection methods aim to detect novel objects by distilling knowledge from vision-language models (VLMs) trained on a vast amount of image-text pairs. To improve the effectiveness of these methods, researchers have utilized datasets with a large vocabulary that contains a large number of object classes, under the assumption that such data will enable models to extract comprehensive knowledge on the relationships between various objects and better generalize to unseen object classes. In this study, we argue that more fine-grained labels are necessary to extract richer knowledge about novel objects, including object attributes and relationships, in addition to their names. To address this challenge, we propose a simple and effective method named Pseudo Caption Labeling (PCL), which utilizes an image captioning model to generate captions that describe object instances from diverse perspectives. The resulting pseudo caption labels offer dense samples for knowledge distillation. On the LVIS benchmark, our best model trained on the de-duplicated VisualGenome dataset achieves an AP of 34.5 and an APr of 30.6, comparable to the state-of-the-art performance. PCL's simplicity and flexibility are other notable features, as it is a straightforward pre-processing technique that can be used with any image captioning model without imposing any restrictions on model architecture or training process.
Noise-aware Learning from Web-crawled Image-Text Data for Image Captioning
Dec 27, 2022



Image captioning is one of the straightforward tasks that can take advantage of large-scale web-crawled data which provides rich knowledge about the visual world for a captioning model. However, since web-crawled data contains image-text pairs that are aligned at different levels, the inherent noises (e.g., misaligned pairs) make it difficult to learn a precise captioning model. While the filtering strategy can effectively remove noisy data, however, it leads to a decrease in learnable knowledge and sometimes brings about a new problem of data deficiency. To take the best of both worlds, we propose a noise-aware learning framework, which learns rich knowledge from the whole web-crawled data while being less affected by the noises. This is achieved by the proposed quality controllable model, which is learned using alignment levels of the image-text pairs as an additional control signal during training. The alignment-conditioned training allows the model to generate high-quality captions of well-aligned by simply setting the control signal to desired alignment level at inference time. Through in-depth analysis, we show that our controllable captioning model is effective in handling noise. In addition, with two tasks of zero-shot captioning and text-to-image retrieval using generated captions (i.e., self-retrieval), we also demonstrate our model can produce high-quality captions in terms of descriptiveness and distinctiveness. Code is available at \url{https://github.com/kakaobrain/noc}.
Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
Dec 01, 2022



We tackle open-world semantic segmentation, which aims at learning to segment arbitrary visual concepts in images, by using only image-text pairs without dense annotations. Existing open-world segmentation methods have shown impressive advances by employing contrastive learning (CL) to learn diverse visual concepts and adapting the learned image-level understanding to the segmentation task. However, these methods based on CL have a discrepancy since it only considers image-text level alignment in training time, while the segmentation task requires region-text level alignment at test time. In this paper, we propose a novel Text-grounded Contrastive Learning (TCL) framework to directly align a text and a region described by the text to address the train-test discrepancy. Our method generates a segmentation mask associated with a given text, extracts grounded image embedding from the masked region, and aligns it with text embedding via TCL. The framework addresses the discrepancy by letting the model learn region-text level alignment instead of image-text level alignment and encourages the model to directly improve the quality of generated segmentation masks. In addition, for a rigorous and fair comparison, we present a unified evaluation protocol with widely used 8 semantic segmentation datasets. TCL achieves state-of-the-art zero-shot segmentation performance with large margins in all datasets. Code is available at https://github.com/kakaobrain/tcl.