 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZun Wang
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024
We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
Self-Consistency Training for Hamiltonian Prediction
Mar 14, 2024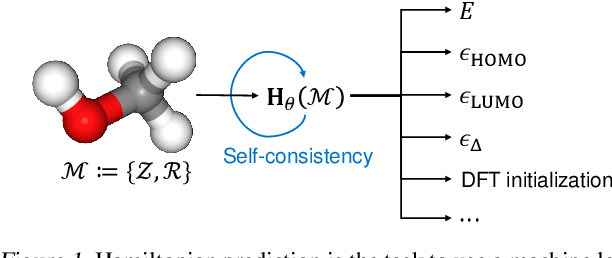
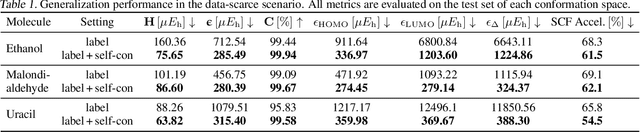
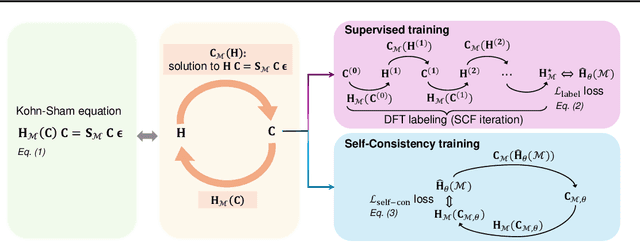
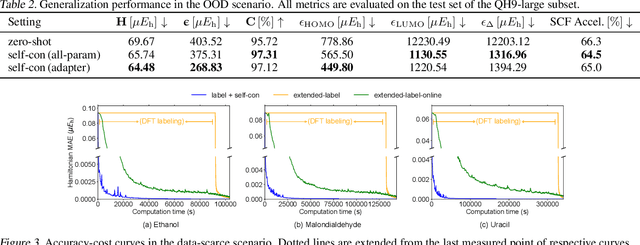
Hamiltonian prediction is a versatile formulation to leverage machine learning for solving molecular science problems. Yet, its applicability is limited by insufficient labeled data for training. In this work, we highlight that Hamiltonian prediction possesses a self-consistency principle, based on which we propose an exact training method that does not require labeled data. This merit addresses the data scarcity difficulty, and distinguishes the task from other property prediction formulations with unique benefits: (1) self-consistency training enables the model to be trained on a large amount of unlabeled data, hence substantially enhances generalization; (2) self-consistency training is more efficient than labeling data with DFT for supervised training, since it is an amortization of DFT calculation over a set of molecular structures. We empirically demonstrate the better generalization in data-scarce and out-of-distribution scenarios, and the better efficiency from the amortization. These benefits push forward the applicability of Hamiltonian prediction to an ever larger scale.
Leveraging Biomolecule and Natural Language through Multi-Modal Learning: A Survey
Mar 05, 2024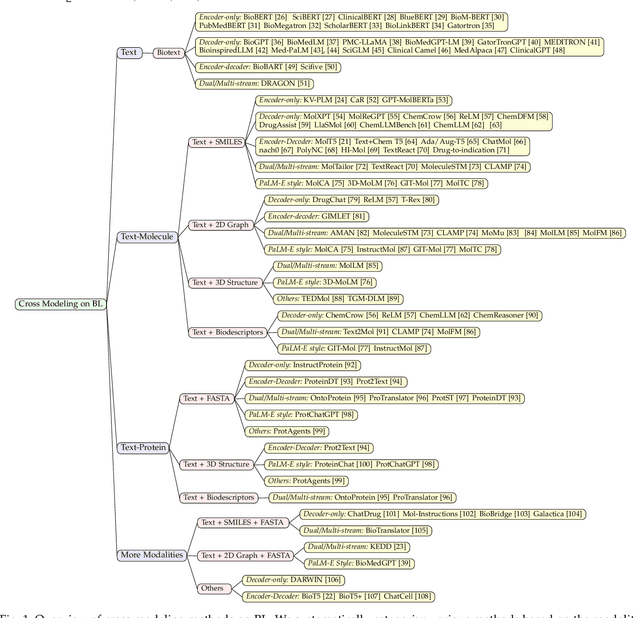
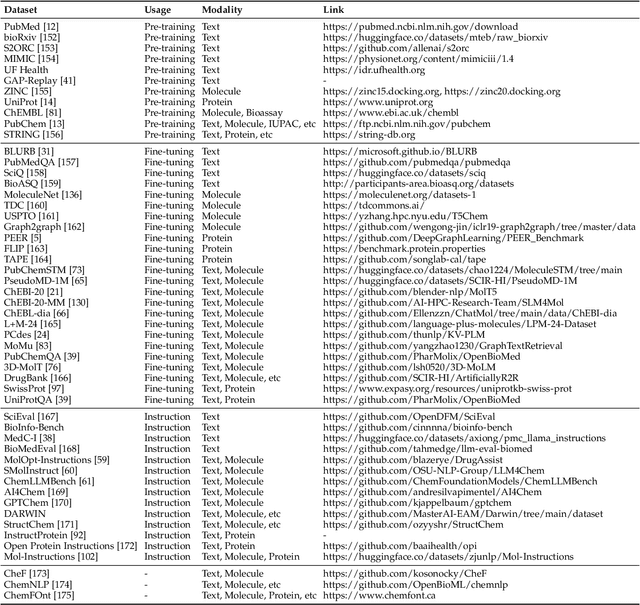
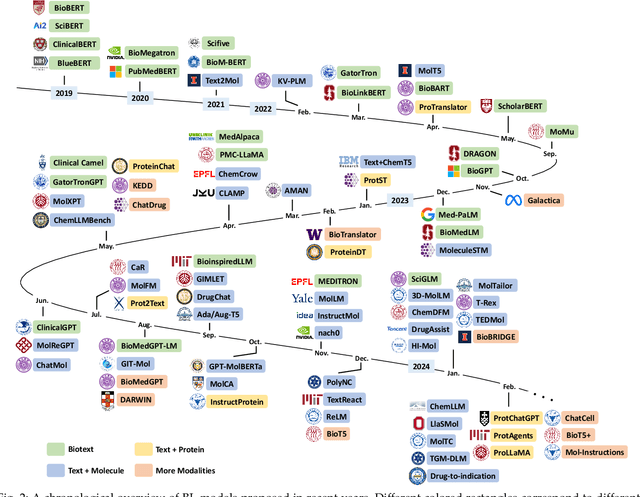
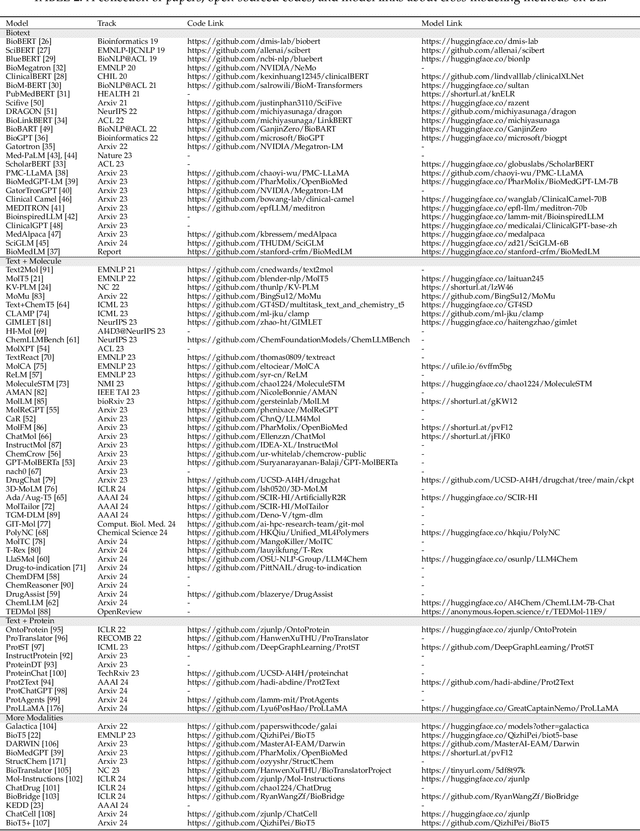
The integration of biomolecular modeling with natural language (BL) has emerged as a promising interdisciplinary area at the intersection of artificial intelligence, chemistry and biology. This approach leverages the rich, multifaceted descriptions of biomolecules contained within textual data sources to enhance our fundamental understanding and enable downstream computational tasks such as biomolecule property prediction. The fusion of the nuanced narratives expressed through natural language with the structural and functional specifics of biomolecules described via various molecular modeling techniques opens new avenues for comprehensively representing and analyzing biomolecules. By incorporating the contextual language data that surrounds biomolecules into their modeling, BL aims to capture a holistic view encompassing both the symbolic qualities conveyed through language as well as quantitative structural characteristics. In this review, we provide an extensive analysis of recent advancements achieved through cross modeling of biomolecules and natural language. (1) We begin by outlining the technical representations of biomolecules employed, including sequences, 2D graphs, and 3D structures. (2) We then examine in depth the rationale and key objectives underlying effective multi-modal integration of language and molecular data sources. (3) We subsequently survey the practical applications enabled to date in this developing research area. (4) We also compile and summarize the available resources and datasets to facilitate future work. (5) Looking ahead, we identify several promising research directions worthy of further exploration and investment to continue advancing the field. The related resources and contents are updating in \url{https://github.com/QizhiPei/Awesome-Biomolecule-Language-Cross-Modeling}.
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Dec 03, 2023
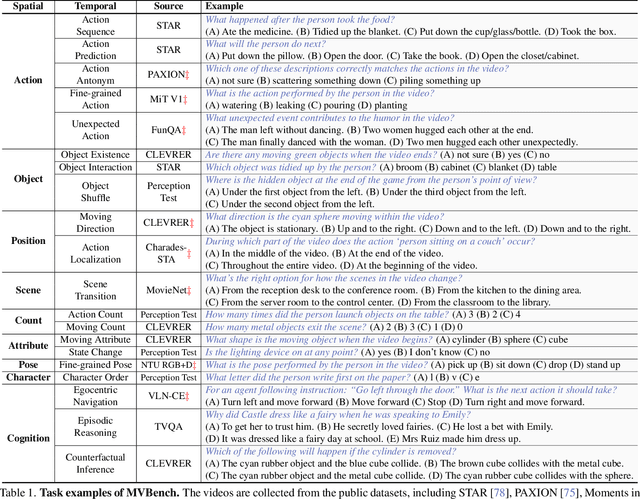
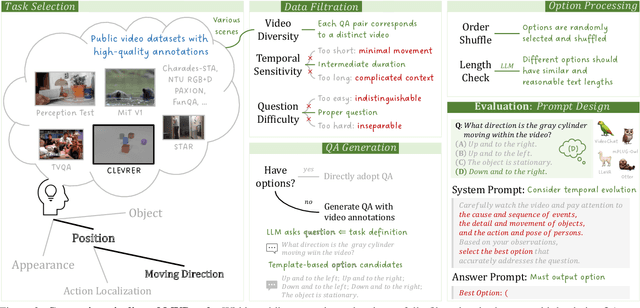

With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
Does AI for science need another ImageNet Or totally different benchmarks? A case study of machine learning force fields
Aug 11, 2023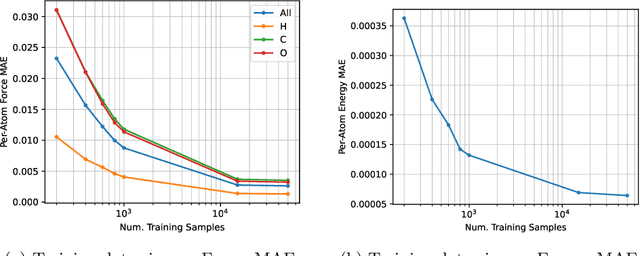
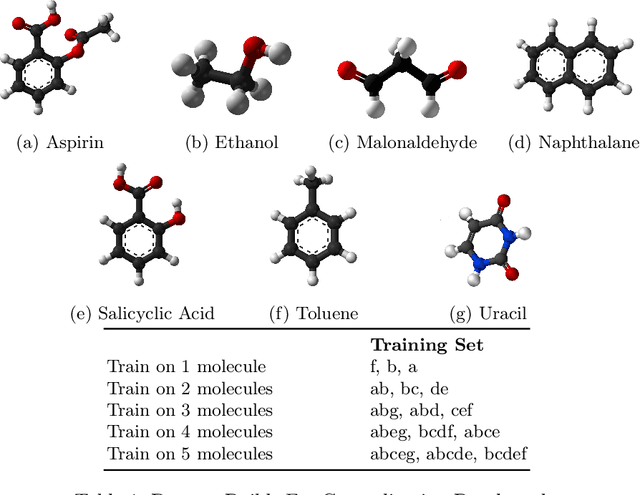
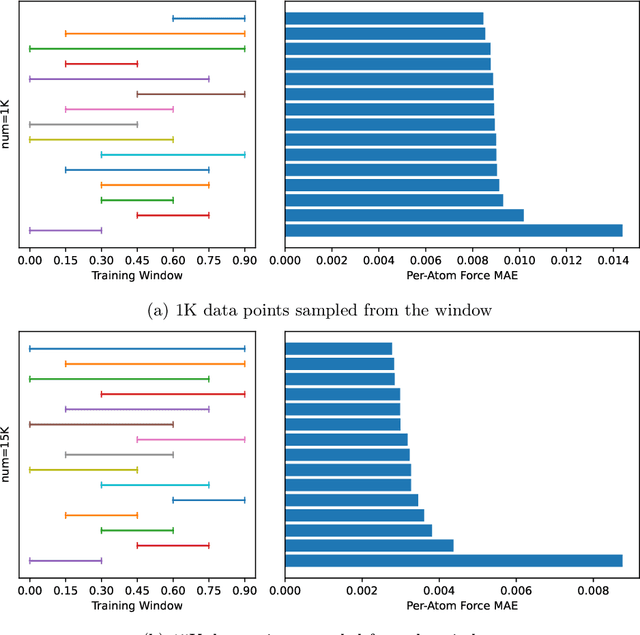
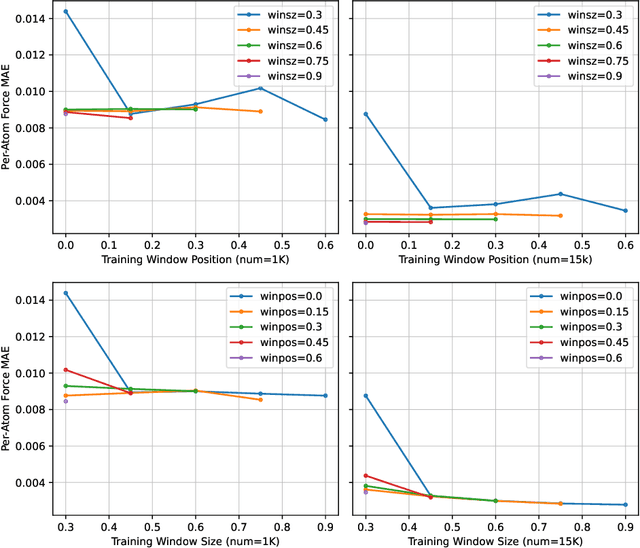
AI for science (AI4S) is an emerging research field that aims to enhance the accuracy and speed of scientific computing tasks using machine learning methods. Traditional AI benchmarking methods struggle to adapt to the unique challenges posed by AI4S because they assume data in training, testing, and future real-world queries are independent and identically distributed, while AI4S workloads anticipate out-of-distribution problem instances. This paper investigates the need for a novel approach to effectively benchmark AI for science, using the machine learning force field (MLFF) as a case study. MLFF is a method to accelerate molecular dynamics (MD) simulation with low computational cost and high accuracy. We identify various missed opportunities in scientifically meaningful benchmarking and propose solutions to evaluate MLFF models, specifically in the aspects of sample efficiency, time domain sensitivity, and cross-dataset generalization capabilities. By setting up the problem instantiation similar to the actual scientific applications, more meaningful performance metrics from the benchmark can be achieved. This suite of metrics has demonstrated a better ability to assess a model's performance in real-world scientific applications, in contrast to traditional AI benchmarking methodologies. This work is a component of the SAIBench project, an AI4S benchmarking suite. The project homepage is https://www.computercouncil.org/SAIBench.
Scaling Data Generation in Vision-and-Language Navigation
Aug 09, 2023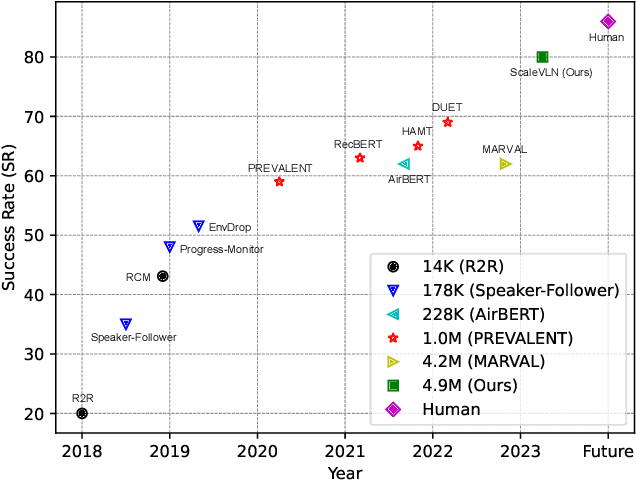
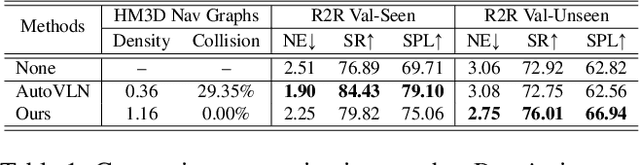
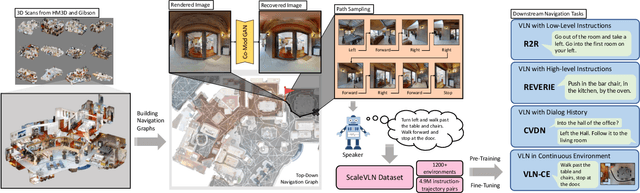
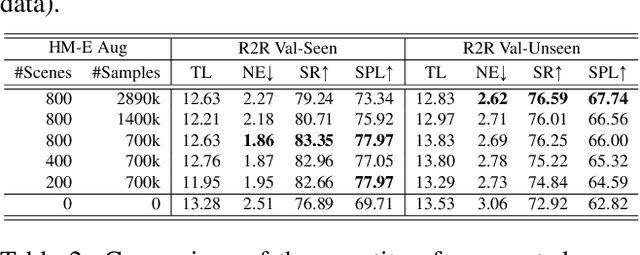
Recent research in language-guided visual navigation has demonstrated a significant demand for the diversity of traversable environments and the quantity of supervision for training generalizable agents. To tackle the common data scarcity issue in existing vision-and-language navigation datasets, we propose an effective paradigm for generating large-scale data for learning, which applies 1200+ photo-realistic environments from HM3D and Gibson datasets and synthesizes 4.9 million instruction trajectory pairs using fully-accessible resources on the web. Importantly, we investigate the influence of each component in this paradigm on the agent's performance and study how to adequately apply the augmented data to pre-train and fine-tune an agent. Thanks to our large-scale dataset, the performance of an existing agent can be pushed up (+11% absolute with regard to previous SoTA) to a significantly new best of 80% single-run success rate on the R2R test split by simple imitation learning. The long-lasting generalization gap between navigating in seen and unseen environments is also reduced to less than 1% (versus 8% in the previous best method). Moreover, our paradigm also facilitates different models to achieve new state-of-the-art navigation results on CVDN, REVERIE, and R2R in continuous environments.
ETPNav: Evolving Topological Planning for Vision-Language Navigation in Continuous Environments
Apr 07, 2023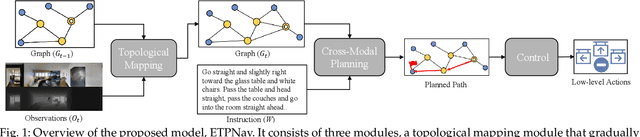

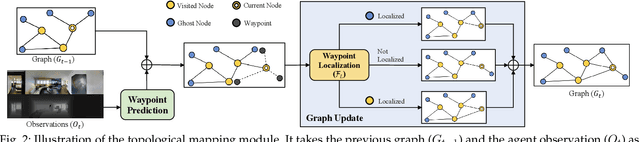
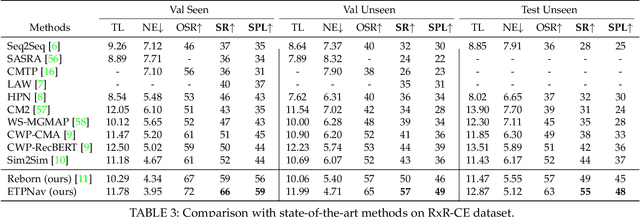
Vision-language navigation is a task that requires an agent to follow instructions to navigate in environments. It becomes increasingly crucial in the field of embodied AI, with potential applications in autonomous navigation, search and rescue, and human-robot interaction. In this paper, we propose to address a more practical yet challenging counterpart setting - vision-language navigation in continuous environments (VLN-CE). To develop a robust VLN-CE agent, we propose a new navigation framework, ETPNav, which focuses on two critical skills: 1) the capability to abstract environments and generate long-range navigation plans, and 2) the ability of obstacle-avoiding control in continuous environments. ETPNav performs online topological mapping of environments by self-organizing predicted waypoints along a traversed path, without prior environmental experience. It privileges the agent to break down the navigation procedure into high-level planning and low-level control. Concurrently, ETPNav utilizes a transformer-based cross-modal planner to generate navigation plans based on topological maps and instructions. The plan is then performed through an obstacle-avoiding controller that leverages a trial-and-error heuristic to prevent navigation from getting stuck in obstacles. Experimental results demonstrate the effectiveness of the proposed method. ETPNav yields more than 10% and 20% improvements over prior state-of-the-art on R2R-CE and RxR-CE datasets, respectively. Our code is available at https://github.com/MarSaKi/ETPNav.
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Dec 07, 2022

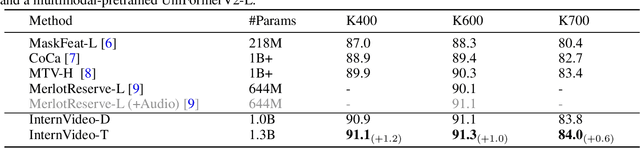
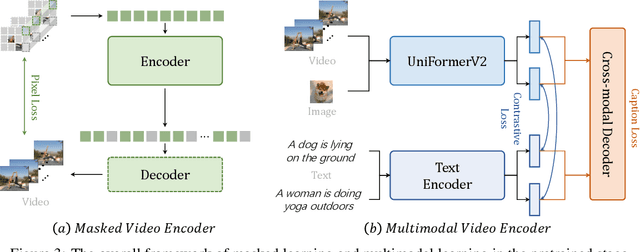
The foundation models have recently shown excellent performance on a variety of downstream tasks in computer vision. However, most existing vision foundation models simply focus on image-level pretraining and adpation, which are limited for dynamic and complex video-level understanding tasks. To fill the gap, we present general video foundation models, InternVideo, by taking advantage of both generative and discriminative self-supervised video learning. Specifically, InternVideo efficiently explores masked video modeling and video-language contrastive learning as the pretraining objectives, and selectively coordinates video representations of these two complementary frameworks in a learnable manner to boost various video applications. Without bells and whistles, InternVideo achieves state-of-the-art performance on 39 video datasets from extensive tasks including video action recognition/detection, video-language alignment, and open-world video applications. Especially, our methods can obtain 91.1% and 77.2% top-1 accuracy on the challenging Kinetics-400 and Something-Something V2 benchmarks, respectively. All of these results effectively show the generality of our InternVideo for video understanding. The code will be released at https://github.com/OpenGVLab/InternVideo .
An ensemble of VisNet, Transformer-M, and pretraining models for molecular property prediction in OGB Large-Scale Challenge @ NeurIPS 2022
Nov 23, 2022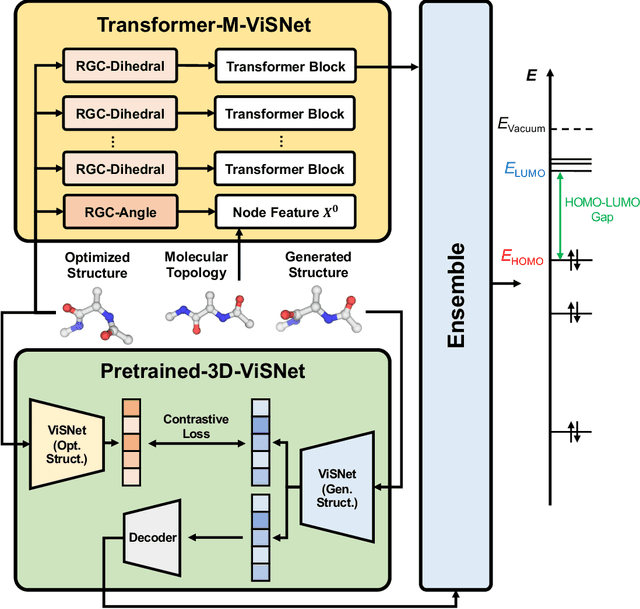
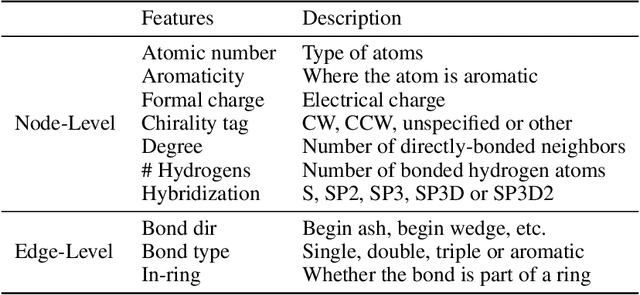

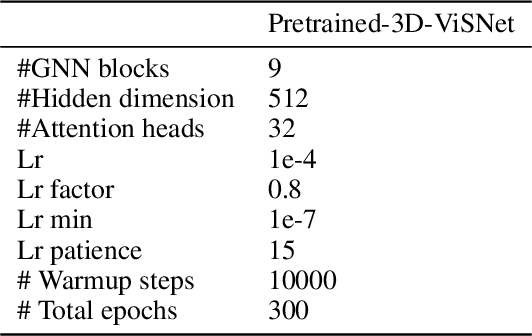
In the technical report, we provide our solution for OGB-LSC 2022 Graph Regression Task. The target of this task is to predict the quantum chemical property, HOMO-LUMO gap for a given molecule on PCQM4Mv2 dataset. In the competition, we designed two kinds of models: Transformer-M-ViSNet which is an geometry-enhanced graph neural network for fully connected molecular graphs and Pretrained-3D-ViSNet which is a pretrained ViSNet by distilling geomeotric information from optimized structures. With an ensemble of 22 models, ViSNet Team achieved the MAE of 0.0723 eV on the test-challenge set, dramatically reducing the error by 39.75% compared with the best method in the last year competition.
InternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Nov 17, 2022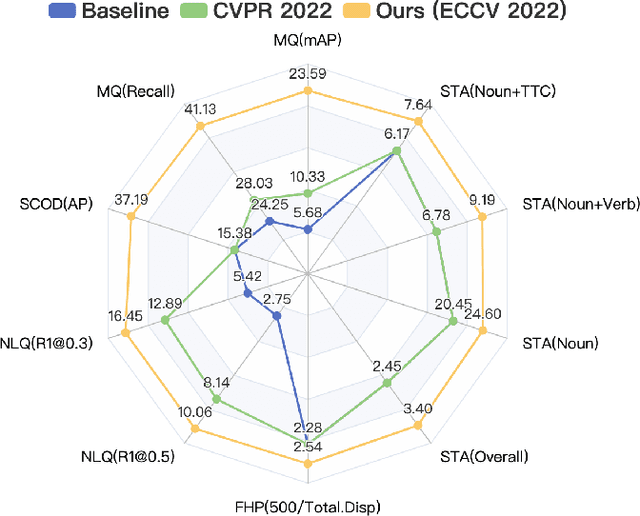

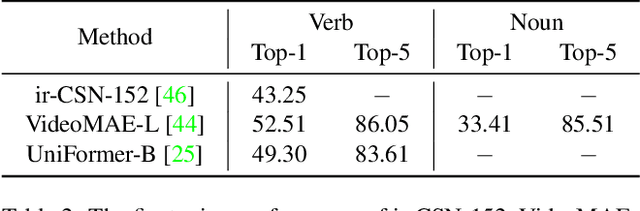

In this report, we present our champion solutions to five tracks at Ego4D challenge. We leverage our developed InternVideo, a video foundation model, for five Ego4D tasks, including Moment Queries, Natural Language Queries, Future Hand Prediction, State Change Object Detection, and Short-term Object Interaction Anticipation. InternVideo-Ego4D is an effective paradigm to adapt the strong foundation model to the downstream ego-centric video understanding tasks with simple head designs. In these five tasks, the performance of InternVideo-Ego4D comprehensively surpasses the baseline methods and the champions of CVPR2022, demonstrating the powerful representation ability of InternVideo as a video foundation model. Our code will be released at https://github.com/OpenGVLab/ego4d-eccv2022-solutions