 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiang Wang
LongEmbed: Extending Embedding Models for Long Context Retrieval
Apr 18, 2024
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
Jetsons at FinNLP 2024: Towards Understanding the ESG Impact of a News Article using Transformer-based Models
Mar 30, 2024In this paper, we describe the different approaches explored by the Jetsons team for the Multi-Lingual ESG Impact Duration Inference (ML-ESG-3) shared task. The shared task focuses on predicting the duration and type of the ESG impact of a news article. The shared task dataset consists of 2,059 news titles and articles in English, French, Korean, and Japanese languages. For the impact duration classification task, we fine-tuned XLM-RoBERTa with a custom fine-tuning strategy and using self-training and DeBERTa-v3 using only English translations. These models individually ranked first on the leaderboard for Korean and Japanese and in an ensemble for the English language, respectively. For the impact type classification task, our XLM-RoBERTa model fine-tuned using a custom fine-tuning strategy ranked first for the English language.
Out-of-distribution Rumor Detection via Test-Time Adaptation
Mar 26, 2024Due to the rapid spread of rumors on social media, rumor detection has become an extremely important challenge. Existing methods for rumor detection have achieved good performance, as they have collected enough corpus from the same data distribution for model training. However, significant distribution shifts between the training data and real-world test data occur due to differences in news topics, social media platforms, languages and the variance in propagation scale caused by news popularity. This leads to a substantial decline in the performance of these existing methods in Out-Of-Distribution (OOD) situations. To address this problem, we propose a simple and efficient method named Test-time Adaptation for Rumor Detection under distribution shifts (TARD). This method models the propagation of news in the form of a propagation graph, and builds propagation graph test-time adaptation framework, enhancing the model's adaptability and robustness when facing OOD problems. Extensive experiments conducted on two group datasets collected from real-world social platforms demonstrate that our framework outperforms the state-of-the-art methods in performance.
Antigen-Specific Antibody Design via Direct Energy-based Preference Optimization
Mar 25, 2024Antibody design, a crucial task with significant implications across various disciplines such as therapeutics and biology, presents considerable challenges due to its intricate nature. In this paper, we tackle antigen-specific antibody design as a protein sequence-structure co-design problem, considering both rationality and functionality. Leveraging a pre-trained conditional diffusion model that jointly models sequences and structures of complementarity-determining regions (CDR) in antibodies with equivariant neural networks, we propose direct energy-based preference optimization to guide the generation of antibodies with both rational structures and considerable binding affinities to given antigens. Our method involves fine-tuning the pre-trained diffusion model using a residue-level decomposed energy preference. Additionally, we employ gradient surgery to address conflicts between various types of energy, such as attraction and repulsion. Experiments on RAbD benchmark show that our approach effectively optimizes the energy of generated antibodies and achieves state-of-the-art performance in designing high-quality antibodies with low total energy and high binding affinity, demonstrating the superiority of our approach.
Addressing Concept Shift in Online Time Series Forecasting: Detect-then-Adapt
Mar 22, 2024Online updating of time series forecasting models aims to tackle the challenge of concept drifting by adjusting forecasting models based on streaming data. While numerous algorithms have been developed, most of them focus on model design and updating. In practice, many of these methods struggle with continuous performance regression in the face of accumulated concept drifts over time. To address this limitation, we present a novel approach, Concept \textbf{D}rift \textbf{D}etection an\textbf{D} \textbf{A}daptation (D3A), that first detects drifting conception and then aggressively adapts the current model to the drifted concepts after the detection for rapid adaption. To best harness the utility of historical data for model adaptation, we propose a data augmentation strategy introducing Gaussian noise into existing training instances. It helps mitigate the data distribution gap, a critical factor contributing to train-test performance inconsistency. The significance of our data augmentation process is verified by our theoretical analysis. Our empirical studies across six datasets demonstrate the effectiveness of D3A in improving model adaptation capability. Notably, compared to a simple Temporal Convolutional Network (TCN) baseline, D3A reduces the average Mean Squared Error (MSE) by $43.9\%$. For the state-of-the-art (SOTA) model, the MSE is reduced by $33.3\%$.
KEBench: A Benchmark on Knowledge Editing for Large Vision-Language Models
Mar 12, 2024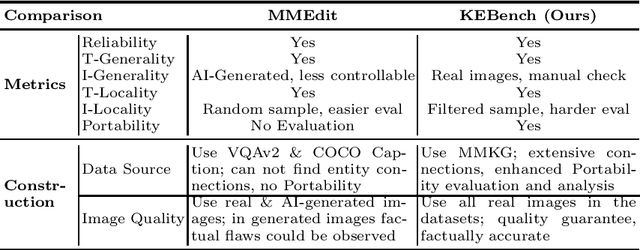

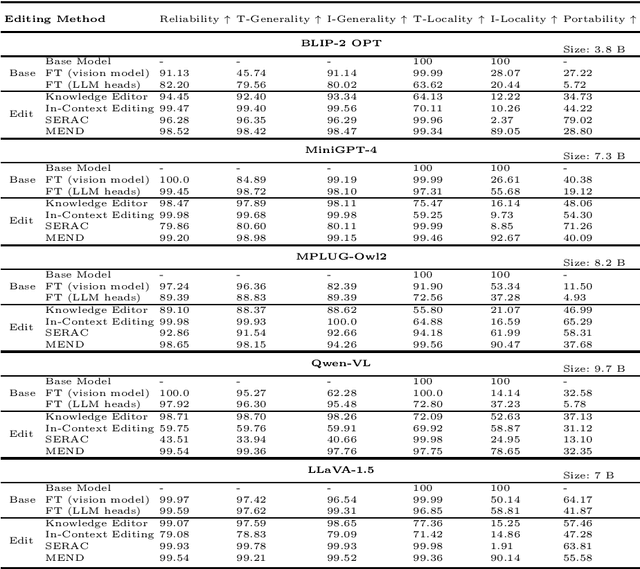
Currently, little research has been done on knowledge editing for Large Vision-Language Models (LVLMs). Editing LVLMs faces the challenge of effectively integrating diverse modalities (image and text) while ensuring coherent and contextually relevant modifications. An existing benchmark has three metrics (Reliability, Locality and Generality) to measure knowledge editing for LVLMs. However, the benchmark falls short in the quality of generated images used in evaluation and cannot assess whether models effectively utilize edited knowledge in relation to the associated content. We adopt different data collection methods to construct a new benchmark, $\textbf{KEBench}$, and extend new metric (Portability) for a comprehensive evaluation. Leveraging a multimodal knowledge graph, our image data exhibits clear directionality towards entities. This directional aspect can be further utilized to extract entity-related knowledge and form editing data. We conducted experiments of different editing methods on five LVLMs, and thoroughly analyze how these methods impact the models. The results reveal strengths and deficiencies of these methods and, hopefully, provide insights into potential avenues for future research.
Debiasing Large Visual Language Models
Mar 08, 2024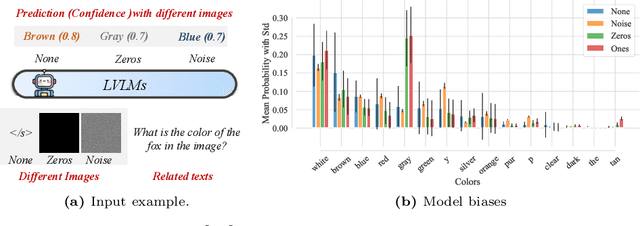
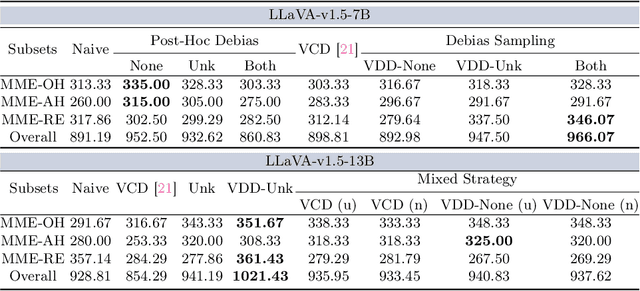
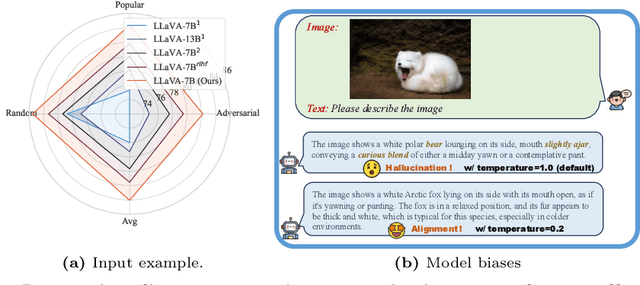
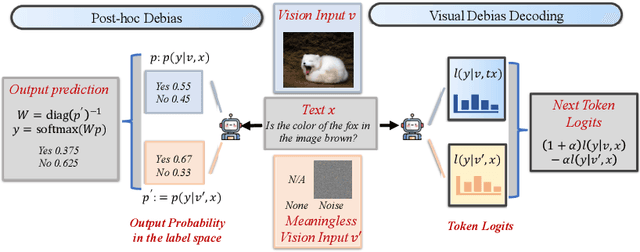
In the realms of computer vision and natural language processing, Large Vision-Language Models (LVLMs) have become indispensable tools, proficient in generating textual descriptions based on visual inputs. Despite their advancements, our investigation reveals a noteworthy bias in the generated content, where the output is primarily influenced by the underlying Large Language Models (LLMs) prior rather than the input image. Our empirical experiments underscore the persistence of this bias, as LVLMs often provide confident answers even in the absence of relevant images or given incongruent visual input. To rectify these biases and redirect the model's focus toward vision information, we introduce two simple, training-free strategies. Firstly, for tasks such as classification or multi-choice question-answering (QA), we propose a ``calibration'' step through affine transformation to adjust the output distribution. This ``Post-Hoc debias'' approach ensures uniform scores for each answer when the image is absent, serving as an effective regularization technique to alleviate the influence of LLM priors. For more intricate open-ended generation tasks, we extend this method to ``Debias sampling'', drawing inspirations from contrastive decoding methods. Furthermore, our investigation sheds light on the instability of LVLMs across various decoding configurations. Through systematic exploration of different settings, we significantly enhance performance, surpassing reported results and raising concerns about the fairness of existing evaluations. Comprehensive experiments substantiate the effectiveness of our proposed strategies in mitigating biases. These strategies not only prove beneficial in minimizing hallucinations but also contribute to the generation of more helpful and precise illustrations.
PromptIQA: Boosting the Performance and Generalization for No-Reference Image Quality Assessment via Prompts
Mar 08, 2024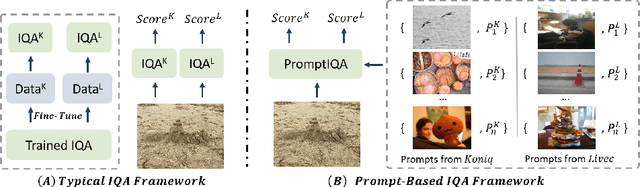
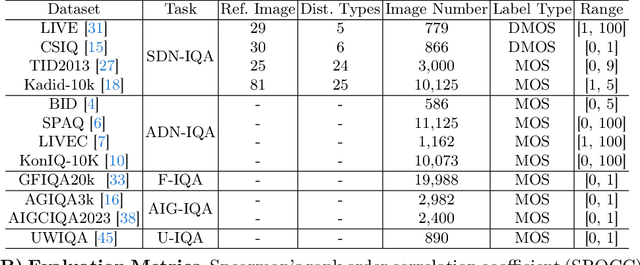
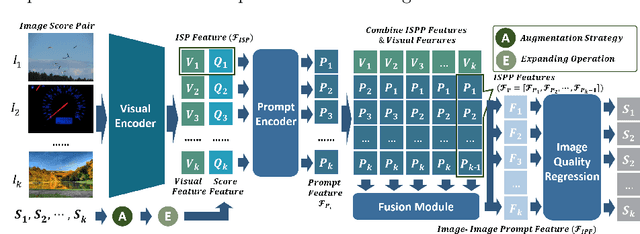
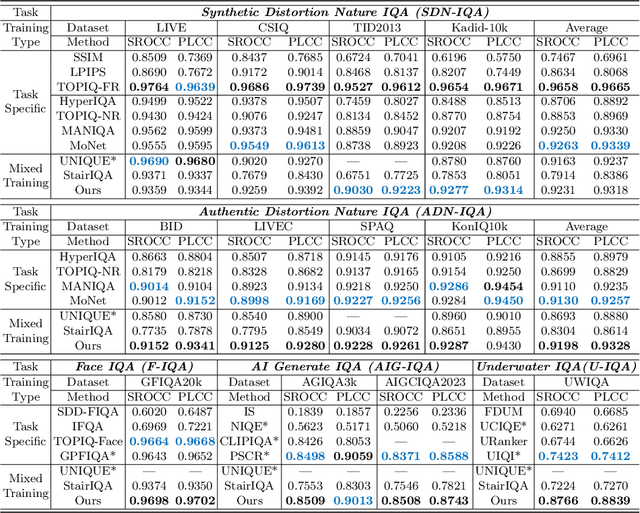
Due to the diversity of assessment requirements in various application scenarios for the IQA task, existing IQA methods struggle to directly adapt to these varied requirements after training. Thus, when facing new requirements, a typical approach is fine-tuning these models on datasets specifically created for those requirements. However, it is time-consuming to establish IQA datasets. In this work, we propose a Prompt-based IQA (PromptIQA) that can directly adapt to new requirements without fine-tuning after training. On one hand, it utilizes a short sequence of Image-Score Pairs (ISP) as prompts for targeted predictions, which significantly reduces the dependency on the data requirements. On the other hand, PromptIQA is trained on a mixed dataset with two proposed data augmentation strategies to learn diverse requirements, thus enabling it to effectively adapt to new requirements. Experiments indicate that the PromptIQA outperforms SOTA methods with higher performance and better generalization. The code will be available.
Stabilizing Policy Gradients for Stochastic Differential Equations via Consistency with Perturbation Process
Mar 07, 2024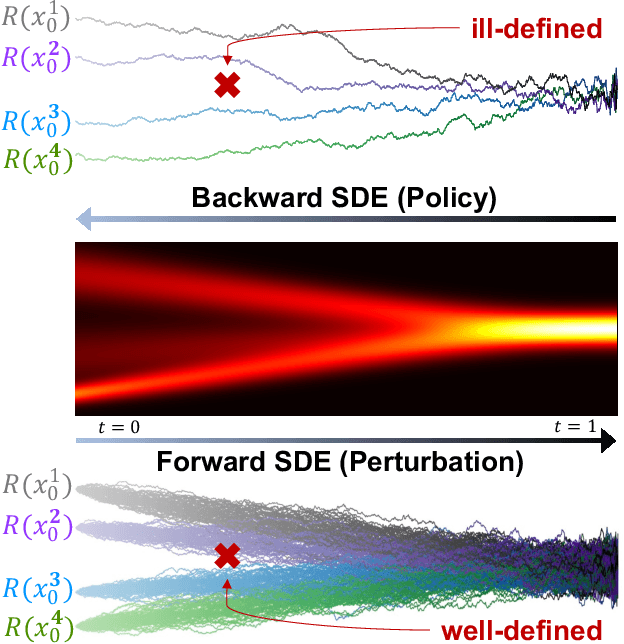
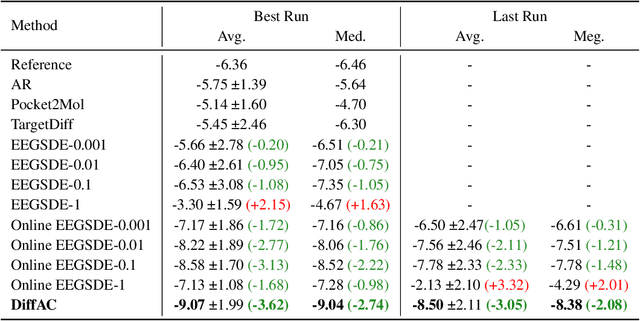
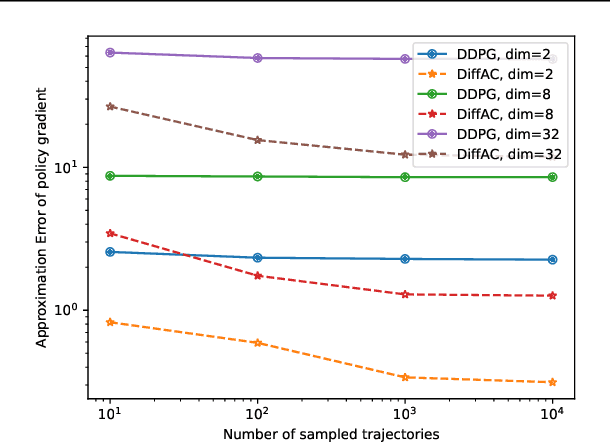
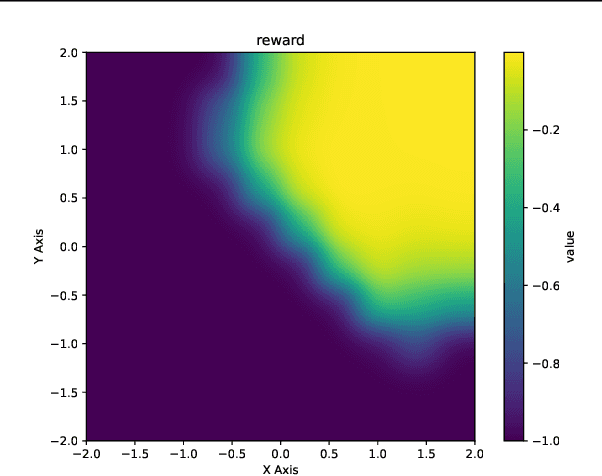
Considering generating samples with high rewards, we focus on optimizing deep neural networks parameterized stochastic differential equations (SDEs), the advanced generative models with high expressiveness, with policy gradient, the leading algorithm in reinforcement learning. Nevertheless, when applying policy gradients to SDEs, since the policy gradient is estimated on a finite set of trajectories, it can be ill-defined, and the policy behavior in data-scarce regions may be uncontrolled. This challenge compromises the stability of policy gradients and negatively impacts sample complexity. To address these issues, we propose constraining the SDE to be consistent with its associated perturbation process. Since the perturbation process covers the entire space and is easy to sample, we can mitigate the aforementioned problems. Our framework offers a general approach allowing for a versatile selection of policy gradient methods to effectively and efficiently train SDEs. We evaluate our algorithm on the task of structure-based drug design and optimize the binding affinity of generated ligand molecules. Our method achieves the best Vina score -9.07 on the CrossDocked2020 dataset.
Evolving to the Future: Unseen Event Adaptive Fake News Detection on Social Media
Feb 29, 2024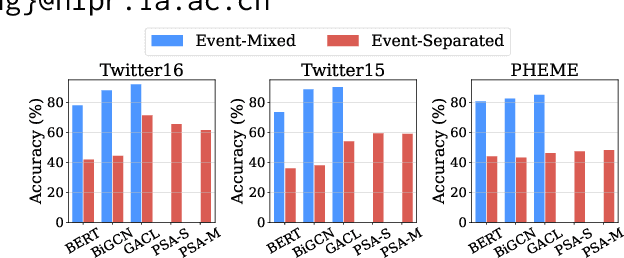
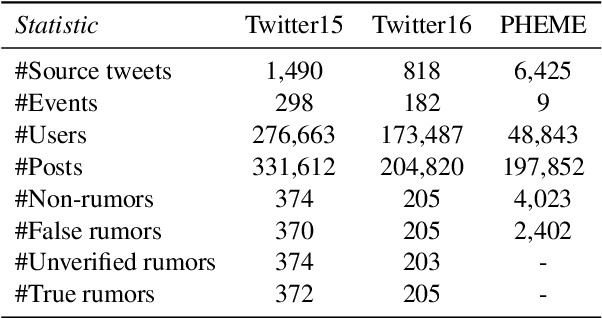
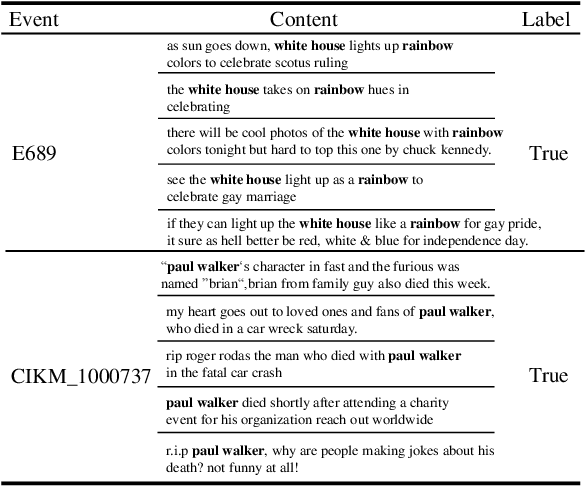
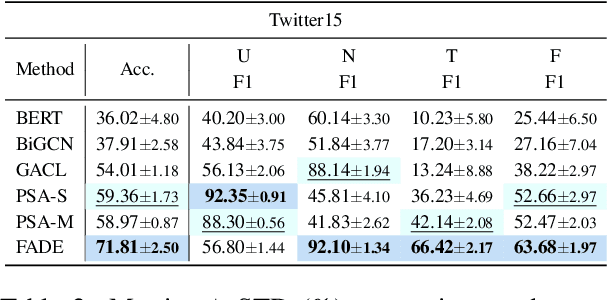
With the rapid development of social media, the wide dissemination of fake news on social media is increasingly threatening both individuals and society. In the dynamic landscape of social media, fake news detection aims to develop a model trained on news reporting past events. The objective is to predict and identify fake news about future events, which often relate to subjects entirely different from those in the past. However, existing fake detection methods exhibit a lack of robustness and cannot generalize to unseen events. To address this, we introduce Future ADaptive Event-based Fake news Detection (FADE) framework. Specifically, we train a target predictor through an adaptive augmentation strategy and graph contrastive learning to make more robust overall predictions. Simultaneously, we independently train an event-only predictor to obtain biased predictions. Then we further mitigate event bias by obtaining the final prediction by subtracting the output of the event-only predictor from the output of the target predictor. Encouraging results from experiments designed to emulate real-world social media conditions validate the effectiveness of our method in comparison to existing state-of-the-art approaches.