 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenhao Wu
LongEmbed: Extending Embedding Models for Long Context Retrieval
Apr 18, 2024
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
CoUDA: Coherence Evaluation via Unified Data Augmentation
Mar 31, 2024Coherence evaluation aims to assess the organization and structure of a discourse, which remains challenging even in the era of large language models. Due to the scarcity of annotated data, data augmentation is commonly used for training coherence evaluation models. However, previous augmentations for this task primarily rely on heuristic rules, lacking designing criteria as guidance. In this paper, we take inspiration from linguistic theory of discourse structure, and propose a data augmentation framework named CoUDA. CoUDA breaks down discourse coherence into global and local aspects, and designs augmentation strategies for both aspects, respectively. Especially for local coherence, we propose a novel generative strategy for constructing augmentation samples, which involves post-pretraining a generative model and applying two controlling mechanisms to control the difficulty of generated samples. During inference, CoUDA also jointly evaluates both global and local aspects to comprehensively assess the overall coherence of a discourse. Extensive experiments in coherence evaluation show that, with only 233M parameters, CoUDA achieves state-of-the-art performance in both pointwise scoring and pairwise ranking tasks, even surpassing recent GPT-3.5 and GPT-4 based metrics.
DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
Mar 19, 2024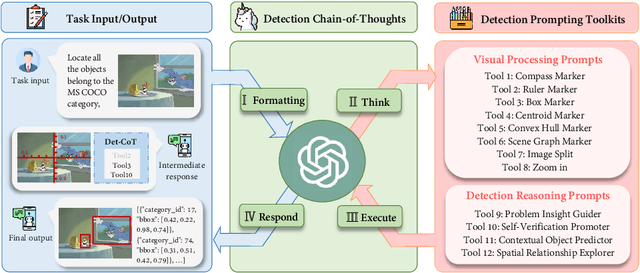

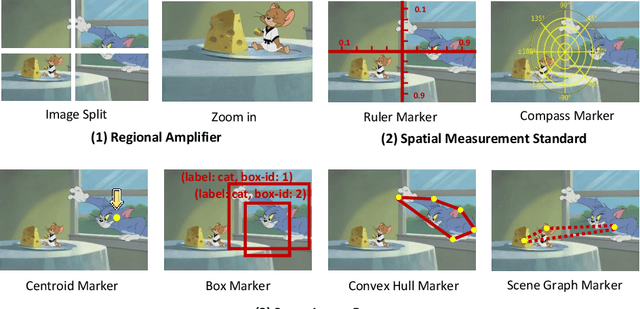
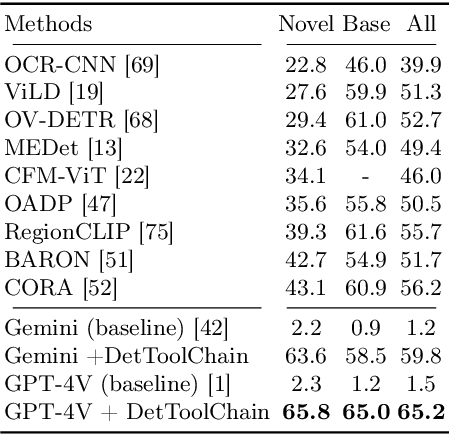
We present DetToolChain, a novel prompting paradigm, to unleash the zero-shot object detection ability of multimodal large language models (MLLMs), such as GPT-4V and Gemini. Our approach consists of a detection prompting toolkit inspired by high-precision detection priors and a new Chain-of-Thought to implement these prompts. Specifically, the prompts in the toolkit are designed to guide the MLLM to focus on regional information (e.g., zooming in), read coordinates according to measure standards (e.g., overlaying rulers and compasses), and infer from the contextual information (e.g., overlaying scene graphs). Building upon these tools, the new detection chain-of-thought can automatically decompose the task into simple subtasks, diagnose the predictions, and plan for progressive box refinements. The effectiveness of our framework is demonstrated across a spectrum of detection tasks, especially hard cases. Compared to existing state-of-the-art methods, GPT-4V with our DetToolChain improves state-of-the-art object detectors by +21.5% AP50 on MS COCO Novel class set for open-vocabulary detection, +24.23% Acc on RefCOCO val set for zero-shot referring expression comprehension, +14.5% AP on D-cube describe object detection FULL setting.
MetaSplit: Meta-Split Network for Limited-Stock Product Recommendation
Mar 16, 2024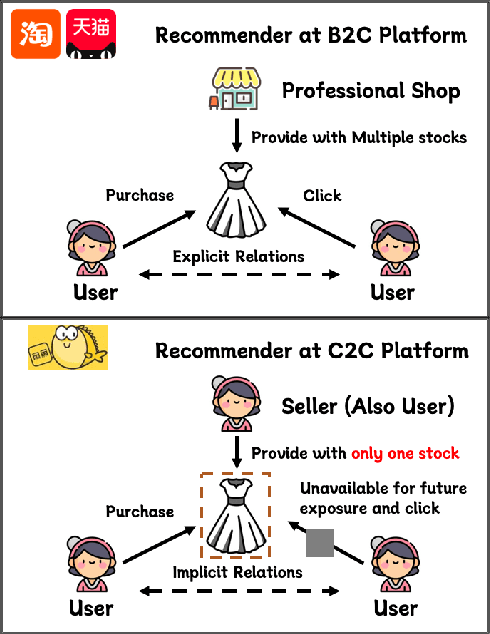
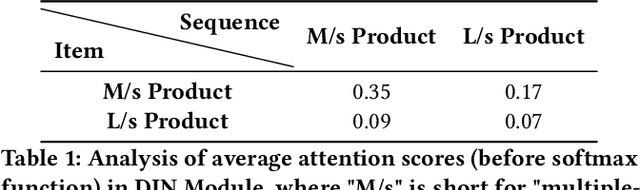
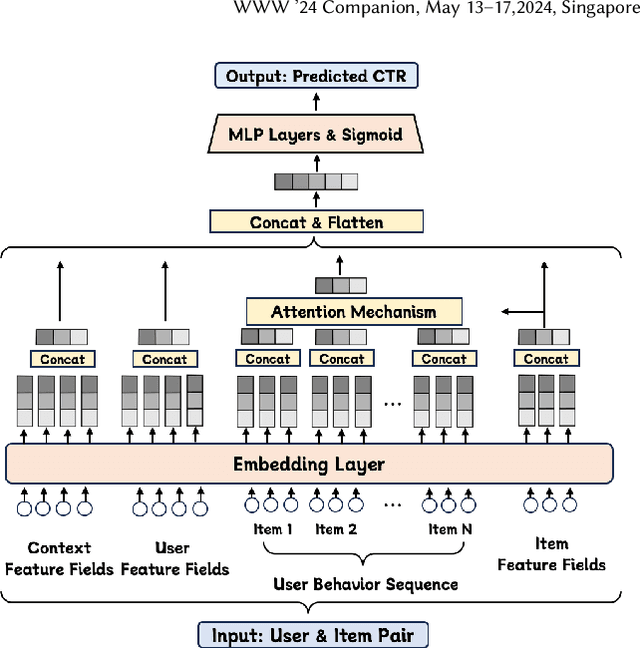
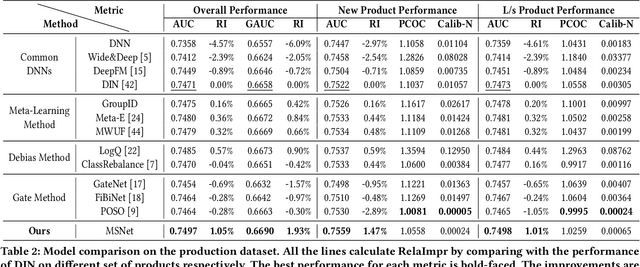
Compared to business-to-consumer (B2C) e-commerce systems, consumer-to-consumer (C2C) e-commerce platforms usually encounter the limited-stock problem, that is, a product can only be sold one time in a C2C system. This poses several unique challenges for click-through rate (CTR) prediction. Due to limited user interactions for each product (i.e. item), the corresponding item embedding in the CTR model may not easily converge. This makes the conventional sequence modeling based approaches cannot effectively utilize user history information since historical user behaviors contain a mixture of items with different volume of stocks. Particularly, the attention mechanism in a sequence model tends to assign higher score to products with more accumulated user interactions, making limited-stock products being ignored and contribute less to the final output. To this end, we propose the Meta-Split Network (MSNet) to split user history sequence regarding to the volume of stock for each product, and adopt differentiated modeling approaches for different sequences. As for the limited-stock products, a meta-learning approach is applied to address the problem of inconvergence, which is achieved by designing meta scaling and shifting networks with ID and side information. In addition, traditional approach can hardly update item embedding once the product is consumed. Thereby, we propose an auxiliary loss that makes the parameters updatable even when the product is no longer in distribution. To the best of our knowledge, this is the first solution addressing the recommendation of limited-stock product. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness of our proposed method.
GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition
Jan 18, 2024Vision-Language Models (VLMs), pre-trained on large-scale datasets, have shown impressive performance in various visual recognition tasks. This advancement paves the way for notable performance in Zero-Shot Egocentric Action Recognition (ZS-EAR). Typically, VLMs handle ZS-EAR as a global video-text matching task, which often leads to suboptimal alignment of vision and linguistic knowledge. We propose a refined approach for ZS-EAR using VLMs, emphasizing fine-grained concept-description alignment that capitalizes on the rich semantic and contextual details in egocentric videos. In this paper, we introduce GPT4Ego, a straightforward yet remarkably potent VLM framework for ZS-EAR, designed to enhance the fine-grained alignment of concept and description between vision and language. Extensive experiments demonstrate GPT4Ego significantly outperforms existing VLMs on three large-scale egocentric video benchmarks, i.e., EPIC-KITCHENS-100 (33.2%, +9.4%), EGTEA (39.6%, +5.5%), and CharadesEgo (31.5%, +2.6%).
Deep Structure and Attention Aware Subspace Clustering
Dec 25, 2023Clustering is a fundamental unsupervised representation learning task with wide application in computer vision and pattern recognition. Deep clustering utilizes deep neural networks to learn latent representation, which is suitable for clustering. However, previous deep clustering methods, especially image clustering, focus on the features of the data itself and ignore the relationship between the data, which is crucial for clustering. In this paper, we propose a novel Deep Structure and Attention aware Subspace Clustering (DSASC), which simultaneously considers data content and structure information. We use a vision transformer to extract features, and the extracted features are divided into two parts, structure features, and content features. The two features are used to learn a more efficient subspace structure for spectral clustering. Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art methods. Our code will be available at https://github.com/cs-whh/DSASC
Side4Video: Spatial-Temporal Side Network for Memory-Efficient Image-to-Video Transfer Learning
Nov 27, 2023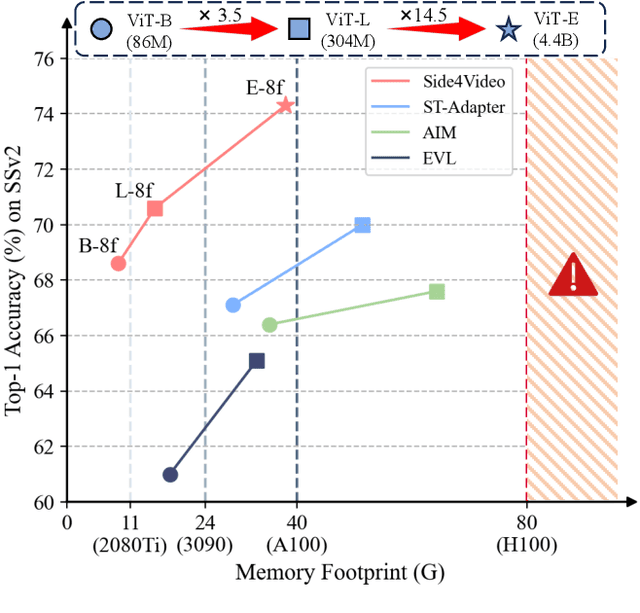
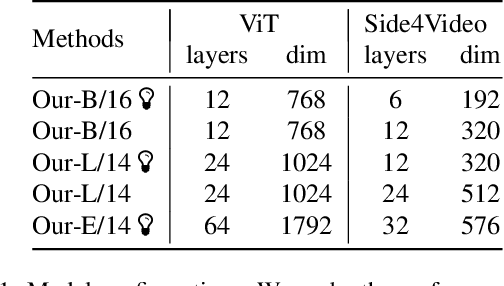
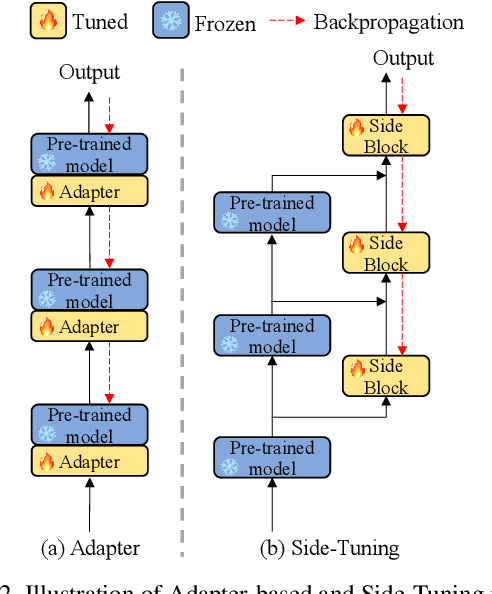
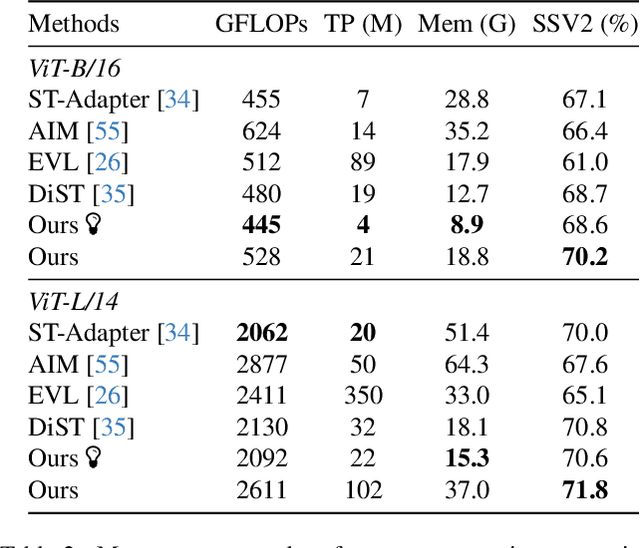
Large pre-trained vision models achieve impressive success in computer vision. However, fully fine-tuning large models for downstream tasks, particularly in video understanding, can be prohibitively computationally expensive. Recent studies turn their focus towards efficient image-to-video transfer learning. Nevertheless, existing efficient fine-tuning methods lack attention to training memory usage and exploration of transferring a larger model to the video domain. In this paper, we present a novel Spatial-Temporal Side Network for memory-efficient fine-tuning large image models to video understanding, named Side4Video. Specifically, we introduce a lightweight spatial-temporal side network attached to the frozen vision model, which avoids the backpropagation through the heavy pre-trained model and utilizes multi-level spatial features from the original image model. Extremely memory-efficient architecture enables our method to reduce 75% memory usage than previous adapter-based methods. In this way, we can transfer a huge ViT-E (4.4B) for video understanding tasks which is 14x larger than ViT-L (304M). Our approach achieves remarkable performance on various video datasets across unimodal and cross-modal tasks (i.e., action recognition and text-video retrieval), especially in Something-Something V1&V2 (67.3% & 74.6%), Kinetics-400 (88.6%), MSR-VTT (52.3%), MSVD (56.1%) and VATEX (68.8%). We release our code at https://github.com/HJYao00/Side4Video.
GPT4Vis: What Can GPT-4 Do for Zero-shot Visual Recognition?
Nov 27, 2023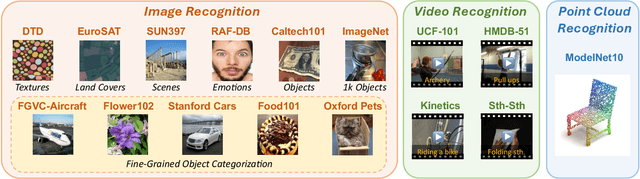
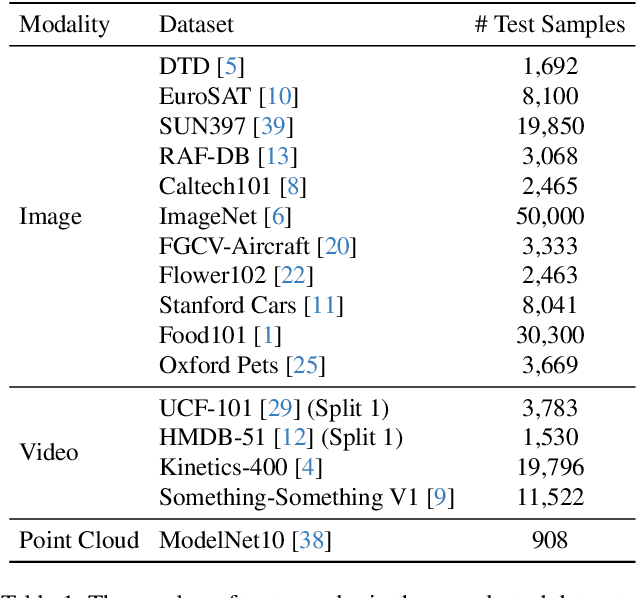
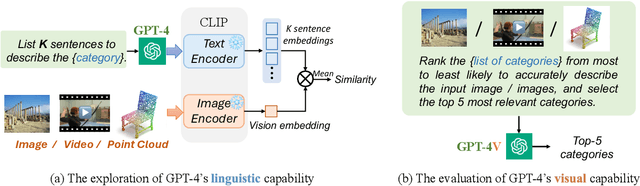
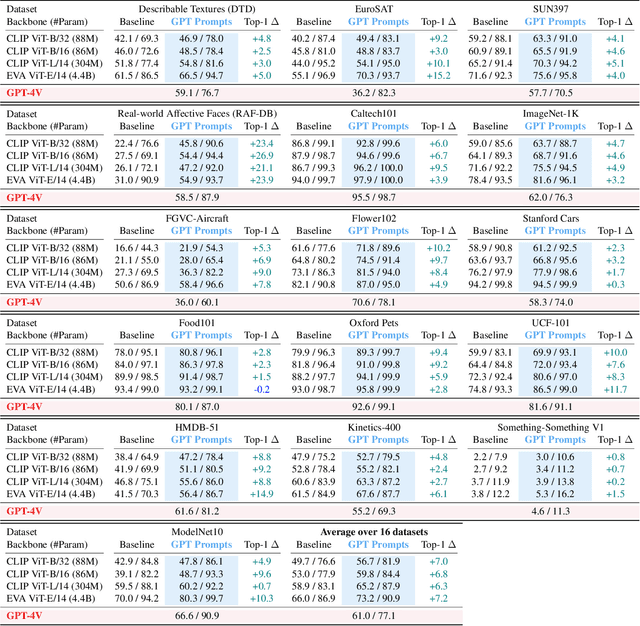
This paper does not present a novel method. Instead, it delves into an essential, yet must-know baseline in light of the latest advancements in Generative Artificial Intelligence (GenAI): the utilization of GPT-4 for visual understanding. Our study centers on the evaluation of GPT-4's linguistic and visual capabilities in zero-shot visual recognition tasks. Specifically, we explore the potential of its generated rich textual descriptions across various categories to enhance recognition performance without any training. Additionally, we evaluate its visual proficiency in directly recognizing diverse visual content. To achieve this, we conduct an extensive series of experiments, systematically quantifying the performance of GPT-4 across three modalities: images, videos, and point clouds. This comprehensive evaluation encompasses a total of 16 widely recognized benchmark datasets, providing top-1 and top-5 accuracy metrics. Our study reveals that leveraging GPT-4's advanced linguistic knowledge to generate rich descriptions markedly improves zero-shot recognition. In terms of visual proficiency, GPT-4V's average performance across 16 datasets sits roughly between the capabilities of OpenAI-CLIP's ViT-L and EVA-CLIP's ViT-E. We hope that this research will contribute valuable data points and experience for future studies. We release our code at https://github.com/whwu95/GPT4Vis.
PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training
Sep 19, 2023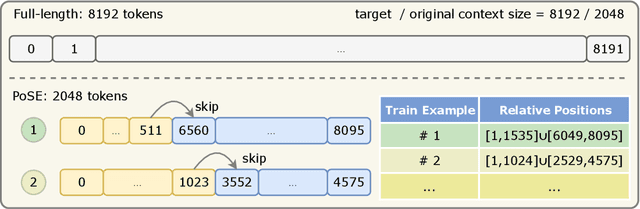
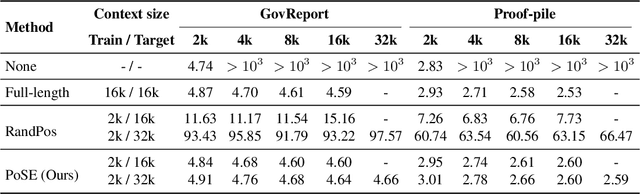
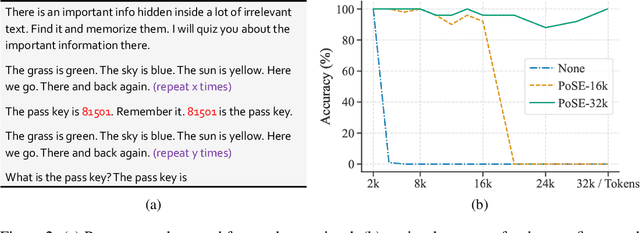
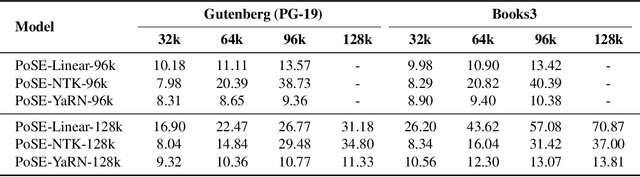
In this paper, we introduce Positional Skip-wisE (PoSE) training for efficient adaptation of large language models~(LLMs) to extremely long context windows. PoSE decouples train length from target context window size by simulating long inputs using a fixed context window with manipulated position indices during training. Concretely, we select several short chunks from a long input sequence, and introduce distinct skipping bias terms to modify the position indices of each chunk. These bias terms, along with the length of each chunk, are altered for each training example, allowing the model to adapt to all positions within the target context window without training on full length inputs. Experiments show that, compared with fine-tuning on the full length, PoSE greatly reduces memory and time overhead with minimal impact on performance. Leveraging this advantage, we have successfully extended the LLaMA model to 128k tokens. Furthermore, we empirically confirm that PoSE is compatible with all RoPE-based LLMs and various position interpolation strategies. Notably, by decoupling fine-tuning length from target context window, PoSE can theoretically extend the context window infinitely, constrained only by memory usage for inference. With ongoing advancements for efficient inference, we believe PoSE holds great promise for scaling the context window even further.