 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuguang Han
MetaSplit: Meta-Split Network for Limited-Stock Product Recommendation
Mar 16, 2024
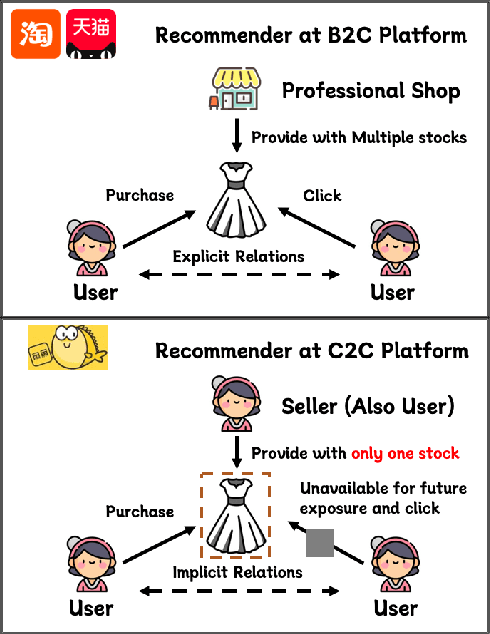
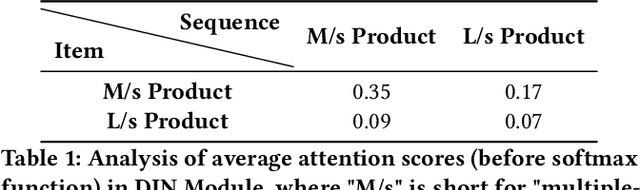
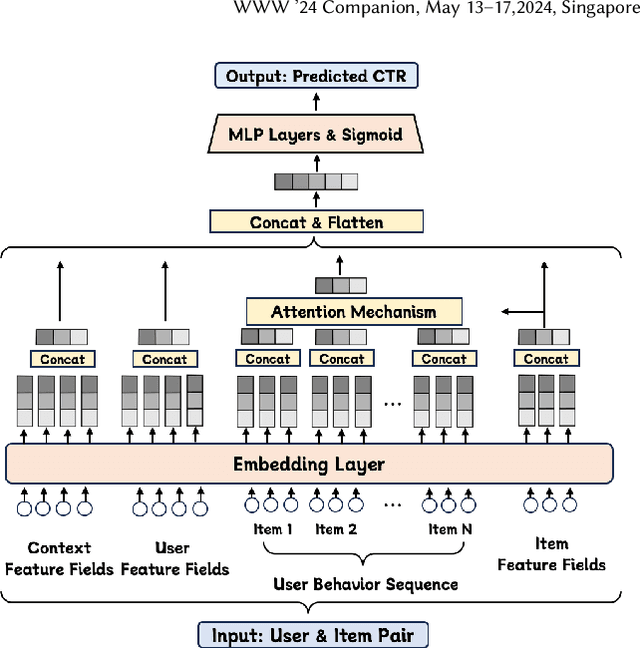
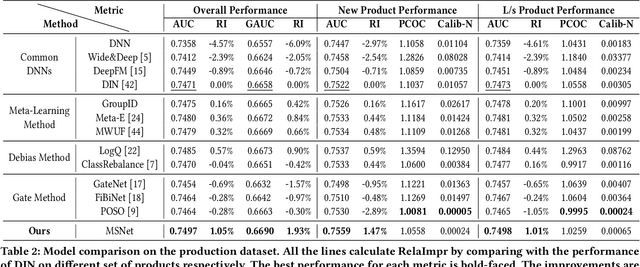
Compared to business-to-consumer (B2C) e-commerce systems, consumer-to-consumer (C2C) e-commerce platforms usually encounter the limited-stock problem, that is, a product can only be sold one time in a C2C system. This poses several unique challenges for click-through rate (CTR) prediction. Due to limited user interactions for each product (i.e. item), the corresponding item embedding in the CTR model may not easily converge. This makes the conventional sequence modeling based approaches cannot effectively utilize user history information since historical user behaviors contain a mixture of items with different volume of stocks. Particularly, the attention mechanism in a sequence model tends to assign higher score to products with more accumulated user interactions, making limited-stock products being ignored and contribute less to the final output. To this end, we propose the Meta-Split Network (MSNet) to split user history sequence regarding to the volume of stock for each product, and adopt differentiated modeling approaches for different sequences. As for the limited-stock products, a meta-learning approach is applied to address the problem of inconvergence, which is achieved by designing meta scaling and shifting networks with ID and side information. In addition, traditional approach can hardly update item embedding once the product is consumed. Thereby, we propose an auxiliary loss that makes the parameters updatable even when the product is no longer in distribution. To the best of our knowledge, this is the first solution addressing the recommendation of limited-stock product. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness of our proposed method.
Effective Two-Stage Knowledge Transfer for Multi-Entity Cross-Domain Recommendation
Feb 29, 2024In recent years, the recommendation content on e-commerce platforms has become increasingly rich -- a single user feed may contain multiple entities, such as selling products, short videos, and content posts. To deal with the multi-entity recommendation problem, an intuitive solution is to adopt the shared-network-based architecture for joint training. The idea is to transfer the extracted knowledge from one type of entity (source entity) to another (target entity). However, different from the conventional same-entity cross-domain recommendation, multi-entity knowledge transfer encounters several important issues: (1) data distributions of the source entity and target entity are naturally different, making the shared-network-based joint training susceptible to the negative transfer issue, (2) more importantly, the corresponding feature schema of each entity is not exactly aligned (e.g., price is an essential feature for selling product while missing for content posts), making the existing methods no longer appropriate. Recent researchers have also experimented with the pre-training and fine-tuning paradigm. Again, they only consider the scenarios with the same entity type and feature systems, which is inappropriate in our case. To this end, we design a pre-training & fine-tuning based Multi-entity Knowledge Transfer framework called MKT. MKT utilizes a multi-entity pre-training module to extract transferable knowledge across different entities. In particular, a feature alignment module is first applied to scale and align different feature schemas. Afterward, a couple of knowledge extractors are employed to extract the common and entity-specific knowledge. In the end, the extracted common knowledge is adopted for target entity model training. Through extensive offline and online experiments, we demonstrated the superiority of MKT over multiple State-Of-The-Art methods.
Calibration-compatible Listwise Distillation of Privileged Features for CTR Prediction
Dec 14, 2023In machine learning systems, privileged features refer to the features that are available during offline training but inaccessible for online serving. Previous studies have recognized the importance of privileged features and explored ways to tackle online-offline discrepancies. A typical practice is privileged features distillation (PFD): train a teacher model using all features (including privileged ones) and then distill the knowledge from the teacher model using a student model (excluding the privileged features), which is then employed for online serving. In practice, the pointwise cross-entropy loss is often adopted for PFD. However, this loss is insufficient to distill the ranking ability for CTR prediction. First, it does not consider the non-i.i.d. characteristic of the data distribution, i.e., other items on the same page significantly impact the click probability of the candidate item. Second, it fails to consider the relative item order ranked by the teacher model's predictions, which is essential to distill the ranking ability. To address these issues, we first extend the pointwise-based PFD to the listwise-based PFD. We then define the calibration-compatible property of distillation loss and show that commonly used listwise losses do not satisfy this property when employed as distillation loss, thus compromising the model's calibration ability, which is another important measure for CTR prediction. To tackle this dilemma, we propose Calibration-compatible LIstwise Distillation (CLID), which employs carefully-designed listwise distillation loss to achieve better ranking ability than the pointwise-based PFD while preserving the model's calibration ability. We theoretically prove it is calibration-compatible. Extensive experiments on public datasets and a production dataset collected from the display advertising system of Alibaba further demonstrate the effectiveness of CLID.
Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction
Aug 09, 2023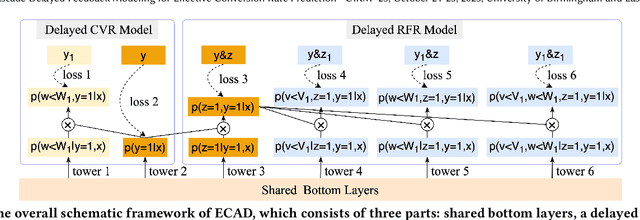
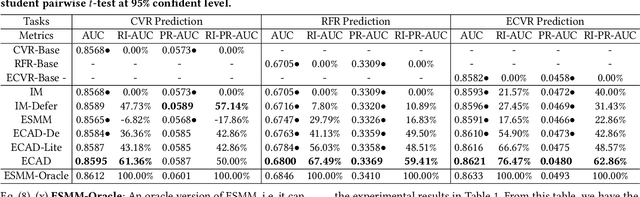
Conversion rate (CVR) prediction is an essential task for large-scale e-commerce platforms. However, refund behaviors frequently occur after conversion in online shopping systems, which drives us to pay attention to effective conversion for building healthier shopping services. This paper defines the probability of item purchasing without any subsequent refund as an effective conversion rate (ECVR). A simple paradigm for ECVR prediction is to decompose it into two sub-tasks: CVR prediction and post-conversion refund rate (RFR) prediction. However, RFR prediction suffers from data sparsity (DS) and sample selection bias (SSB) issues, as the refund behaviors are only available after user purchase. Furthermore, there is delayed feedback in both conversion and refund events and they are sequentially dependent, named cascade delayed feedback (CDF), which significantly harms data freshness for model training. Previous studies mainly focus on tackling DS and SSB or delayed feedback for a single event. To jointly tackle these issues in ECVR prediction, we propose an Entire space CAscade Delayed feedback modeling (ECAD) method. Specifically, ECAD deals with DS and SSB by constructing two tasks including CVR prediction and conversion \& refund rate (CVRFR) prediction using the entire space modeling framework. In addition, it carefully schedules auxiliary tasks to leverage both conversion and refund time within data to alleviate CDF. Experimental results on the offline industrial dataset and online A/B testing demonstrate the effectiveness of ECAD. In addition, ECAD has been deployed in one of the recommender systems in Alibaba, contributing to a significant improvement of ECVR.
Rec4Ad: A Free Lunch to Mitigate Sample Selection Bias for Ads CTR Prediction in Taobao
Jun 06, 2023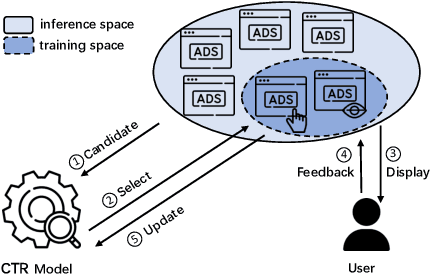
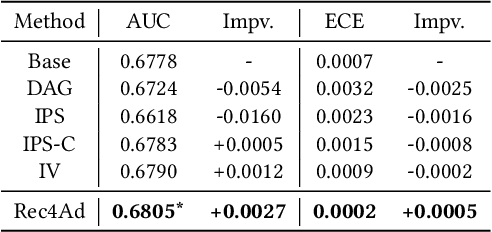
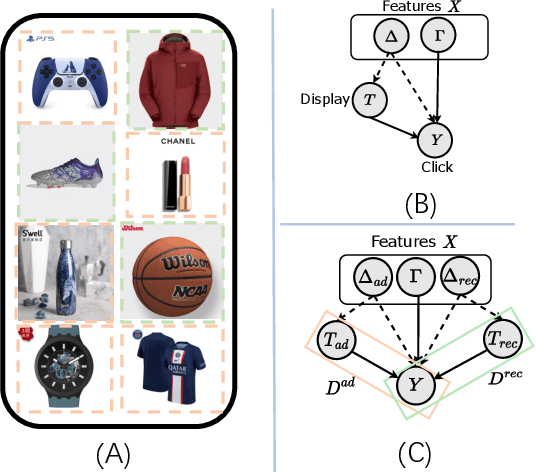
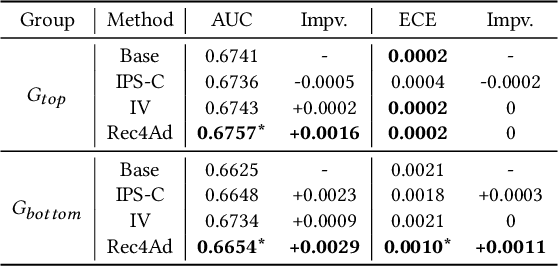
Click-Through Rate (CTR) prediction serves as a fundamental component in online advertising. A common practice is to train a CTR model on advertisement (ad) impressions with user feedback. Since ad impressions are purposely selected by the model itself, their distribution differs from the inference distribution and thus exhibits sample selection bias (SSB) that affects model performance. Existing studies on SSB mainly employ sample re-weighting techniques which suffer from high variance and poor model calibration. Another line of work relies on costly uniform data that is inadequate to train industrial models. Thus mitigating SSB in industrial models with a uniform-data-free framework is worth exploring. Fortunately, many platforms display mixed results of organic items (i.e., recommendations) and sponsored items (i.e., ads) to users, where impressions of ads and recommendations are selected by different systems but share the same user decision rationales. Based on the above characteristics, we propose to leverage recommendations samples as a free lunch to mitigate SSB for ads CTR model (Rec4Ad). After elaborating data augmentation, Rec4Ad learns disentangled representations with alignment and decorrelation modules for enhancement. When deployed in Taobao display advertising system, Rec4Ad achieves substantial gains in key business metrics, with a lift of up to +6.6\% CTR and +2.9\% RPM.
COPR: Consistency-Oriented Pre-Ranking for Online Advertising
Jun 06, 2023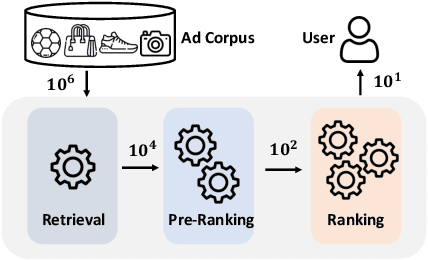

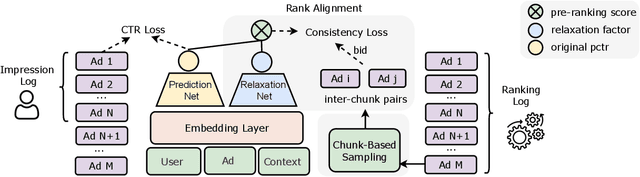
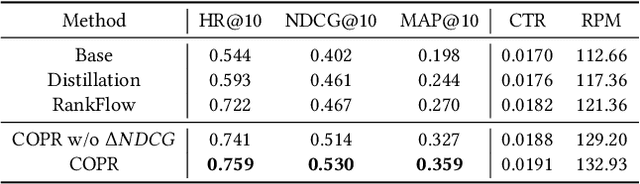
Cascading architecture has been widely adopted in large-scale advertising systems to balance efficiency and effectiveness. In this architecture, the pre-ranking model is expected to be a lightweight approximation of the ranking model, which handles more candidates with strict latency requirements. Due to the gap in model capacity, the pre-ranking and ranking models usually generate inconsistent ranked results, thus hurting the overall system effectiveness. The paradigm of score alignment is proposed to regularize their raw scores to be consistent. However, it suffers from inevitable alignment errors and error amplification by bids when applied in online advertising. To this end, we introduce a consistency-oriented pre-ranking framework for online advertising, which employs a chunk-based sampling module and a plug-and-play rank alignment module to explicitly optimize consistency of ECPM-ranked results. A $\Delta NDCG$-based weighting mechanism is adopted to better distinguish the importance of inter-chunk samples in optimization. Both online and offline experiments have validated the superiority of our framework. When deployed in Taobao display advertising system, it achieves an improvement of up to +12.3\% CTR and +5.6\% RPM.
Capturing Conversion Rate Fluctuation during Sales Promotions: A Novel Historical Data Reuse Approach
May 22, 2023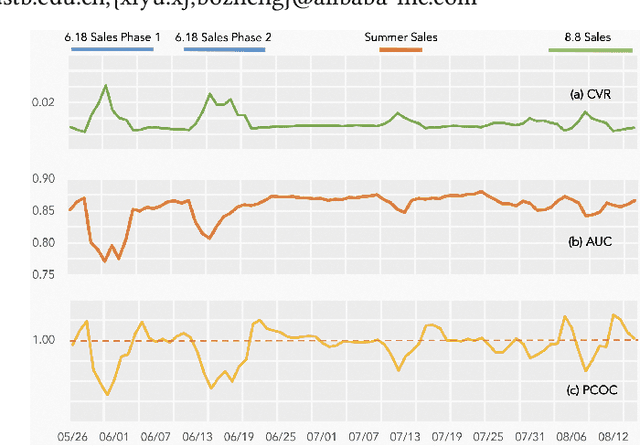
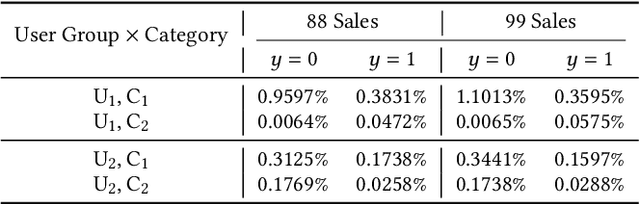
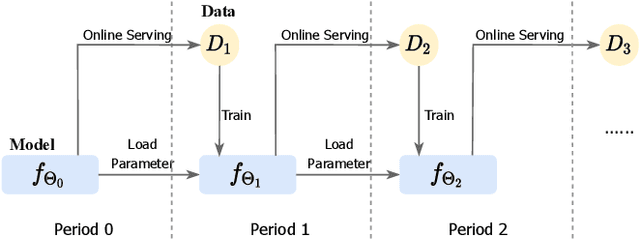
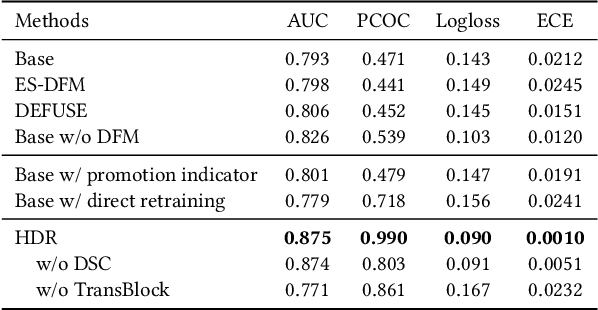
Conversion rate (CVR) prediction is one of the core components in online recommender systems, and various approaches have been proposed to obtain accurate and well-calibrated CVR estimation. However, we observe that a well-trained CVR prediction model often performs sub-optimally during sales promotions. This can be largely ascribed to the problem of the data distribution shift, in which the conventional methods no longer work. To this end, we seek to develop alternative modeling techniques for CVR prediction. Observing similar purchase patterns across different promotions, we propose reusing the historical promotion data to capture the promotional conversion patterns. Herein, we propose a novel \textbf{H}istorical \textbf{D}ata \textbf{R}euse (\textbf{HDR}) approach that first retrieves historically similar promotion data and then fine-tunes the CVR prediction model with the acquired data for better adaptation to the promotion mode. HDR consists of three components: an automated data retrieval module that seeks similar data from historical promotions, a distribution shift correction module that re-weights the retrieved data for better aligning with the target promotion, and a TransBlock module that quickly fine-tunes the original model for better adaptation to the promotion mode. Experiments conducted with real-world data demonstrate the effectiveness of HDR, as it improves both ranking and calibration metrics to a large extent. HDR has also been deployed on the display advertising system in Alibaba, bringing a lift of $9\%$ RPM and $16\%$ CVR during Double 11 Sales in 2022.
Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Prediction Models
Sep 04, 2022
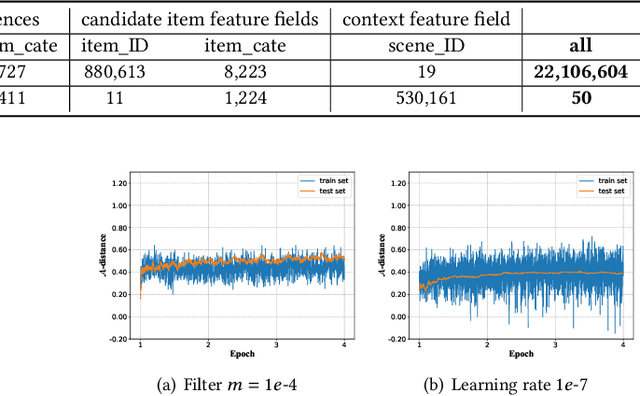
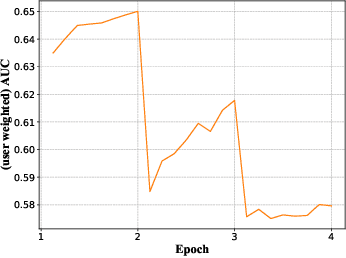

Deep learning techniques have been applied widely in industrial recommendation systems. However, far less attention has been paid to the overfitting problem of models in recommendation systems, which, on the contrary, is recognized as a critical issue for deep neural networks. In the context of Click-Through Rate (CTR) prediction, we observe an interesting one-epoch overfitting problem: the model performance exhibits a dramatic degradation at the beginning of the second epoch. Such a phenomenon has been witnessed widely in real-world applications of CTR models. Thereby, the best performance is usually achieved by training with only one epoch. To understand the underlying factors behind the one-epoch phenomenon, we conduct extensive experiments on the production data set collected from the display advertising system of Alibaba. The results show that the model structure, the optimization algorithm with a fast convergence rate, and the feature sparsity are closely related to the one-epoch phenomenon. We also provide a likely hypothesis for explaining such a phenomenon and conduct a set of proof-of-concept experiments. We hope this work can shed light on future research on training more epochs for better performance.
KEEP: An Industrial Pre-Training Framework for Online Recommendation via Knowledge Extraction and Plugging
Aug 22, 2022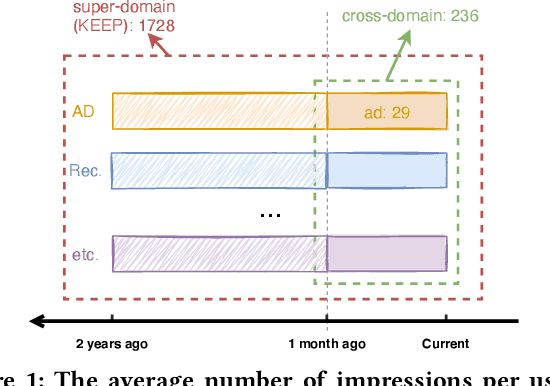

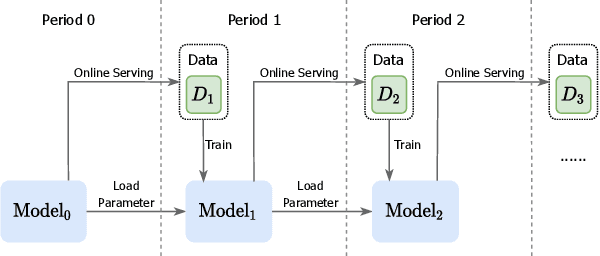
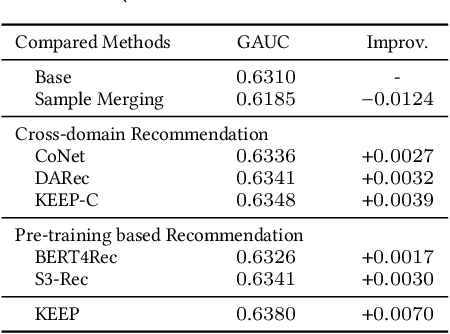
An industrial recommender system generally presents a hybrid list that contains results from multiple subsystems. In practice, each subsystem is optimized with its own feedback data to avoid the disturbance among different subsystems. However, we argue that such data usage may lead to sub-optimal online performance because of the \textit{data sparsity}. To alleviate this issue, we propose to extract knowledge from the \textit{super-domain} that contains web-scale and long-time impression data, and further assist the online recommendation task (downstream task). To this end, we propose a novel industrial \textbf{K}nowl\textbf{E}dge \textbf{E}xtraction and \textbf{P}lugging (\textbf{KEEP}) framework, which is a two-stage framework that consists of 1) a supervised pre-training knowledge extraction module on super-domain, and 2) a plug-in network that incorporates the extracted knowledge into the downstream model. This makes it friendly for incremental training of online recommendation. Moreover, we design an efficient empirical approach for KEEP and introduce our hands-on experience during the implementation of KEEP in a large-scale industrial system. Experiments conducted on two real-world datasets demonstrate that KEEP can achieve promising results. It is notable that KEEP has also been deployed on the display advertising system in Alibaba, bringing a lift of $+5.4\%$ CTR and $+4.7\%$ RPM.
Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model
Aug 12, 2022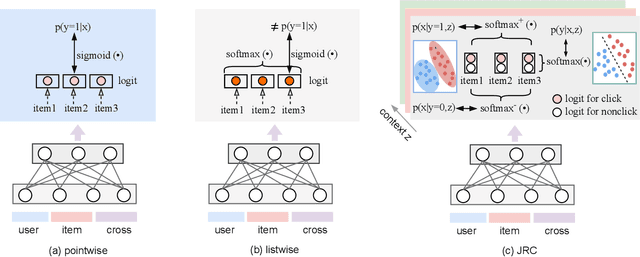
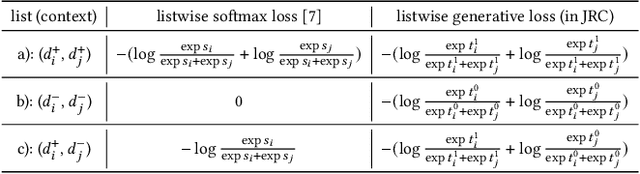

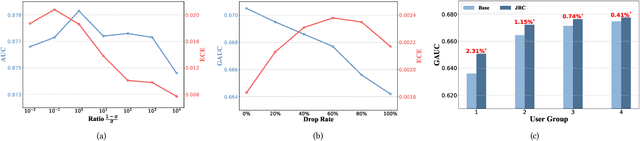
Despite the development of ranking optimization techniques, the pointwise model remains the dominating approach for click-through rate (CTR) prediction. It can be attributed to the calibration ability of the pointwise model since the prediction can be viewed as the click probability. In practice, a CTR prediction model is also commonly assessed with the ranking ability, for which prediction models based on ranking losses (e.g., pairwise or listwise loss) usually achieve better performances than the pointwise loss. Previous studies have experimented with a direct combination of the two losses to obtain the benefit from both losses and observed an improved performance. However, previous studies break the meaning of output logit as the click-through rate, which may lead to sub-optimal solutions. To address this issue, we propose an approach that can Jointly optimize the Ranking and Calibration abilities (JRC for short). JRC improves the ranking ability by contrasting the logit value for the sample with different labels and constrains the predicted probability to be a function of the logit subtraction. We further show that JRC consolidates the interpretation of logits, where the logits model the joint distribution. With such an interpretation, we prove that JRC approximately optimizes the contextualized hybrid discriminative-generative objective. Experiments on public and industrial datasets and online A/B testing show that our approach improves both ranking and calibration abilities. Since May 2022, JRC has been deployed on the display advertising platform of Alibaba and has obtained significant performance improvements.