 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengxi Zhang
DeeDSR: Towards Real-World Image Super-Resolution via Degradation-Aware Stable Diffusion
Mar 31, 2024
Diffusion models, known for their powerful generative capabilities, play a crucial role in addressing real-world super-resolution challenges. However, these models often focus on improving local textures while neglecting the impacts of global degradation, which can significantly reduce semantic fidelity and lead to inaccurate reconstructions and suboptimal super-resolution performance. To address this issue, we introduce a novel two-stage, degradation-aware framework that enhances the diffusion model's ability to recognize content and degradation in low-resolution images. In the first stage, we employ unsupervised contrastive learning to obtain representations of image degradations. In the second stage, we integrate a degradation-aware module into a simplified ControlNet, enabling flexible adaptation to various degradations based on the learned representations. Furthermore, we decompose the degradation-aware features into global semantics and local details branches, which are then injected into the diffusion denoising module to modulate the target generation. Our method effectively recovers semantically precise and photorealistic details, particularly under significant degradation conditions, demonstrating state-of-the-art performance across various benchmarks. Codes will be released at https://github.com/bichunyang419/DeeDSR.
MARIS: Referring Image Segmentation via Mutual-Aware Attention Features
Nov 27, 2023
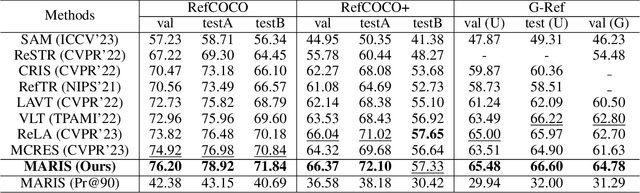

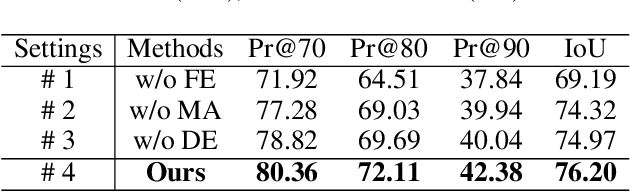
Referring image segmentation (RIS) aims to segment a particular region based on a language expression prompt. Existing methods incorporate linguistic features into visual features and obtain multi-modal features for mask decoding. However, these methods may segment the visually salient entity instead of the correct referring region, as the multi-modal features are dominated by the abundant visual context. In this paper, we propose MARIS, a referring image segmentation method that leverages the Segment Anything Model (SAM) and introduces a mutual-aware attention mechanism to enhance the cross-modal fusion via two parallel branches. Specifically, our mutual-aware attention mechanism consists of Vision-Guided Attention and Language-Guided Attention, which bidirectionally model the relationship between visual and linguistic features. Correspondingly, we design a Mask Decoder to enable explicit linguistic guidance for more consistent segmentation with the language expression. To this end, a multi-modal query token is proposed to integrate linguistic information and interact with visual information simultaneously. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art RIS methods. Our code will be publicly available.
GPT4Vis: What Can GPT-4 Do for Zero-shot Visual Recognition?
Nov 27, 2023
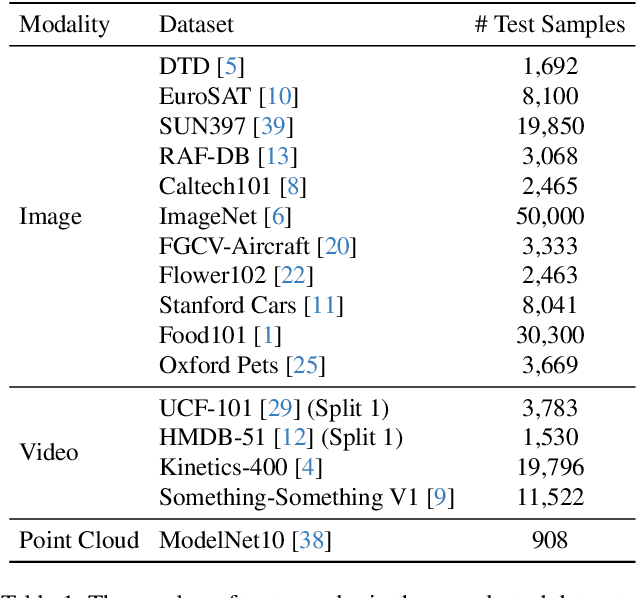
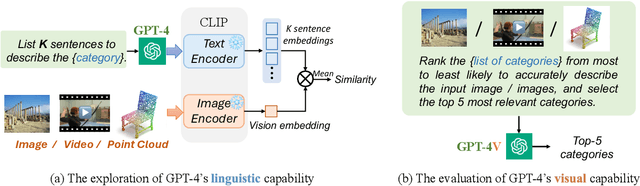
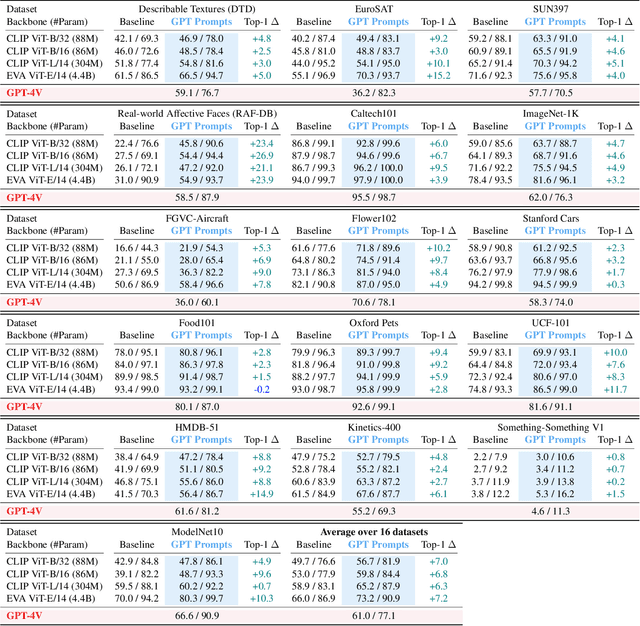
This paper does not present a novel method. Instead, it delves into an essential, yet must-know baseline in light of the latest advancements in Generative Artificial Intelligence (GenAI): the utilization of GPT-4 for visual understanding. Our study centers on the evaluation of GPT-4's linguistic and visual capabilities in zero-shot visual recognition tasks. Specifically, we explore the potential of its generated rich textual descriptions across various categories to enhance recognition performance without any training. Additionally, we evaluate its visual proficiency in directly recognizing diverse visual content. To achieve this, we conduct an extensive series of experiments, systematically quantifying the performance of GPT-4 across three modalities: images, videos, and point clouds. This comprehensive evaluation encompasses a total of 16 widely recognized benchmark datasets, providing top-1 and top-5 accuracy metrics. Our study reveals that leveraging GPT-4's advanced linguistic knowledge to generate rich descriptions markedly improves zero-shot recognition. In terms of visual proficiency, GPT-4V's average performance across 16 datasets sits roughly between the capabilities of OpenAI-CLIP's ViT-L and EVA-CLIP's ViT-E. We hope that this research will contribute valuable data points and experience for future studies. We release our code at https://github.com/whwu95/GPT4Vis.
RT-SRTS: Angle-Agnostic Real-Time Simultaneous 3D Reconstruction and Tumor Segmentation from Single X-Ray Projection
Oct 12, 2023Radiotherapy is one of the primary treatment methods for tumors, but the organ movement caused by respiratory motion limits its accuracy. Recently, 3D imaging from single X-ray projection receives extensive attentions as a promising way to address this issue. However, current methods can only reconstruct 3D image without direct location of the tumor and are only validated for fixed-angle imaging, which fails to fully meet the requirement of motion control in radiotherapy. In this study, we propose a novel imaging method RT-SRTS which integrates 3D imaging and tumor segmentation into one network based on the multi-task learning (MTL) and achieves real-time simultaneous 3D reconstruction and tumor segmentation from single X-ray projection at any angle. Futhermore, we propose the attention enhanced calibrator (AEC) and uncertain-region elaboration (URE) modules to aid feature extraction and improve segmentation accuracy. We evaluated the proposed method on ten patient cases and compared it with two state-of-the-art methods. Our approach not only delivered superior 3D reconstruction but also demonstrated commendable tumor segmentation results. The simultaneous reconstruction and segmentation could be completed in approximately 70 ms, significantly faster than the required time threshold for real-time tumor tracking. The efficacy of both AEC and URE was also validated through ablation studies.
Flexible Alignment Super-Resolution Network for Multi-Contrast MRI
Oct 07, 2022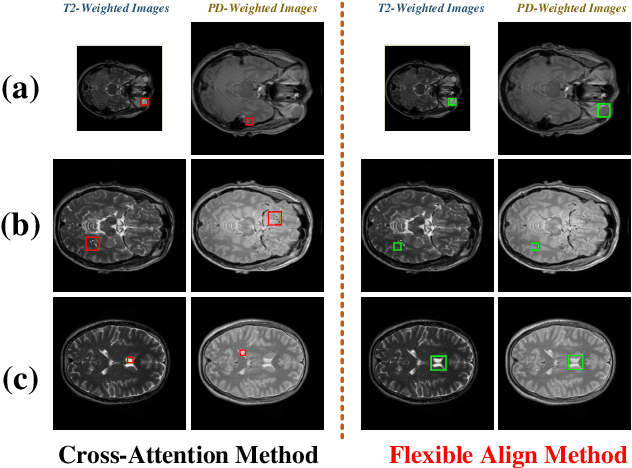
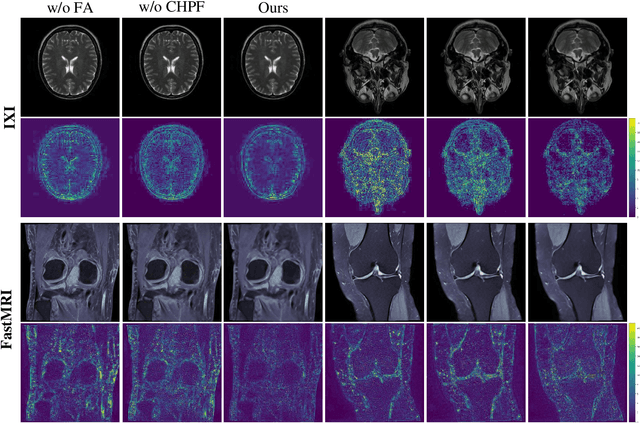
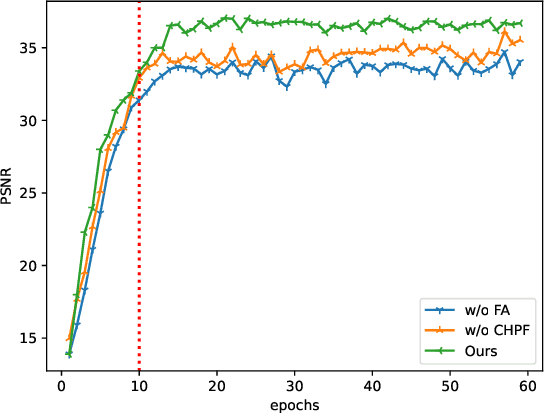
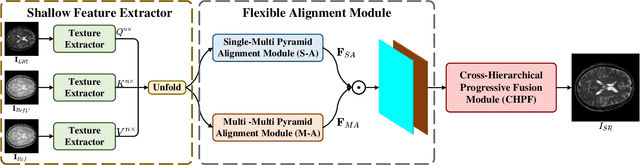
Magnetic resonance images play an essential role in clinical diagnosis by acquiring the structural information of biological tissue. However, during acquiring magnetic resonance images, patients have to endure physical and psychological discomfort, including irritating noise and acute anxiety. To make the patient feel cozier, technically, it will reduce the retention time that patients stay in the strong magnetic field at the expense of image quality. Therefore, Super-Resolution plays a crucial role in preprocessing the low-resolution images for more precise medical analysis. In this paper, we propose the Flexible Alignment Super-Resolution Network (FASR-Net) for multi-contrast magnetic resonance images Super-Resolution. The core of multi-contrast SR is to match the patches of low-resolution and reference images. However, the inappropriate foreground scale and patch size of multi-contrast MRI sometimes lead to the mismatch of patches. To tackle this problem, the Flexible Alignment module is proposed to endow receptive fields with flexibility. Flexible Alignment module contains two parts: (1) The Single-Multi Pyramid Alignmet module serves for low-resolution and reference image with different scale. (2) The Multi-Multi Pyramid Alignment module serves for low-resolution and reference image with the same scale. Extensive experiments on the IXI and FastMRI datasets demonstrate that the FASR-Net outperforms the existing state-of-the-art approaches. In addition, by comparing the reconstructed images with the counterparts obtained by the existing algorithms, our method could retain more textural details by leveraging multi-contrast images.