 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheng Shen
DeeDSR: Towards Real-World Image Super-Resolution via Degradation-Aware Stable Diffusion
Mar 31, 2024
Diffusion models, known for their powerful generative capabilities, play a crucial role in addressing real-world super-resolution challenges. However, these models often focus on improving local textures while neglecting the impacts of global degradation, which can significantly reduce semantic fidelity and lead to inaccurate reconstructions and suboptimal super-resolution performance. To address this issue, we introduce a novel two-stage, degradation-aware framework that enhances the diffusion model's ability to recognize content and degradation in low-resolution images. In the first stage, we employ unsupervised contrastive learning to obtain representations of image degradations. In the second stage, we integrate a degradation-aware module into a simplified ControlNet, enabling flexible adaptation to various degradations based on the learned representations. Furthermore, we decompose the degradation-aware features into global semantics and local details branches, which are then injected into the diffusion denoising module to modulate the target generation. Our method effectively recovers semantically precise and photorealistic details, particularly under significant degradation conditions, demonstrating state-of-the-art performance across various benchmarks. Codes will be released at https://github.com/bichunyang419/DeeDSR.
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Mar 22, 2024Pretrained large language models (LLMs) are currently state-of-the-art for solving the vast majority of natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory levels of performance, many of them are in the low-data regime, making fine-tuning challenging. To address this, we propose LLM2LLM, a targeted and iterative data augmentation strategy that uses a teacher LLM to enhance a small seed dataset by augmenting additional data that can be used for fine-tuning on a specific task. LLM2LLM (1) fine-tunes a baseline student LLM on the initial seed data, (2) evaluates and extracts data points that the model gets wrong, and (3) uses a teacher LLM to generate synthetic data based on these incorrect data points, which are then added back into the training data. This approach amplifies the signal from incorrectly predicted data points by the LLM during training and reintegrates them into the dataset to focus on more challenging examples for the LLM. Our results show that LLM2LLM significantly enhances the performance of LLMs in the low-data regime, outperforming both traditional fine-tuning and other data augmentation baselines. LLM2LLM reduces the dependence on labor-intensive data curation and paves the way for more scalable and performant LLM solutions, allowing us to tackle data-constrained domains and tasks. We achieve improvements up to 24.2% on the GSM8K dataset, 32.6% on CaseHOLD, 32.0% on SNIPS, 52.6% on TREC and 39.8% on SST-2 over regular fine-tuning in the low-data regime using a LLaMA2-7B student model.
RAFT: Adapting Language Model to Domain Specific RAG
Mar 15, 2024
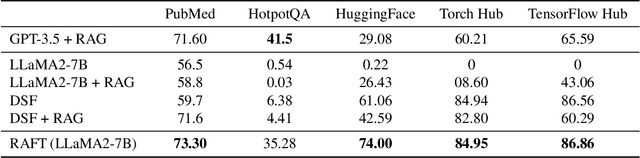
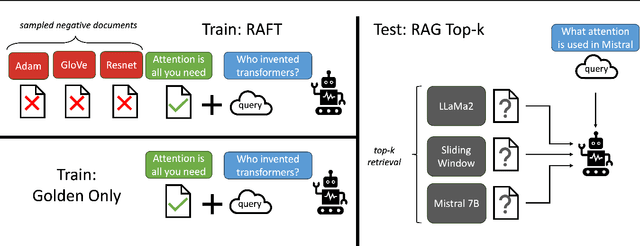
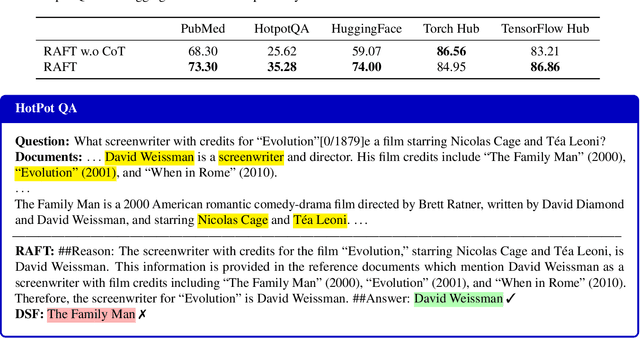
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Reinforcement Unlearning
Dec 26, 2023Machine unlearning refers to the process of mitigating the influence of specific training data on machine learning models based on removal requests from data owners. However, one important area that has been largely overlooked in the research of unlearning is reinforcement learning. Reinforcement learning focuses on training an agent to make optimal decisions within an environment to maximize its cumulative rewards. During the training, the agent tends to memorize the features of the environment, which raises a significant concern about privacy. As per data protection regulations, the owner of the environment holds the right to revoke access to the agent's training data, thus necessitating the development of a novel and pressing research field, known as \emph{reinforcement unlearning}. Reinforcement unlearning focuses on revoking entire environments rather than individual data samples. This unique characteristic presents three distinct challenges: 1) how to propose unlearning schemes for environments; 2) how to avoid degrading the agent's performance in remaining environments; and 3) how to evaluate the effectiveness of unlearning. To tackle these challenges, we propose two reinforcement unlearning methods. The first method is based on decremental reinforcement learning, which aims to erase the agent's previously acquired knowledge gradually. The second method leverages environment poisoning attacks, which encourage the agent to learn new, albeit incorrect, knowledge to remove the unlearning environment. Particularly, to tackle the third challenge, we introduce the concept of ``environment inference attack'' to evaluate the unlearning outcomes. The source code is available at \url{https://anonymous.4open.science/r/Reinforcement-Unlearning-D347}.
Large Language Models are Visual Reasoning Coordinators
Oct 23, 2023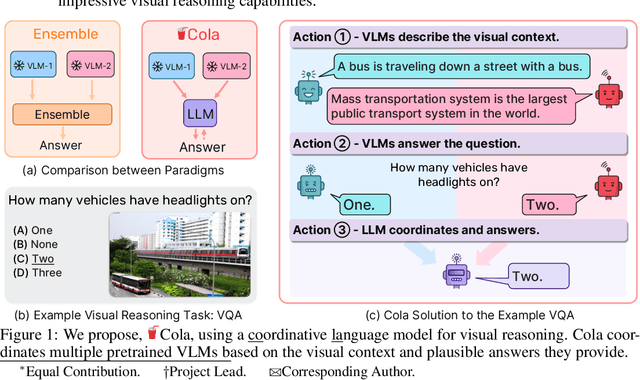
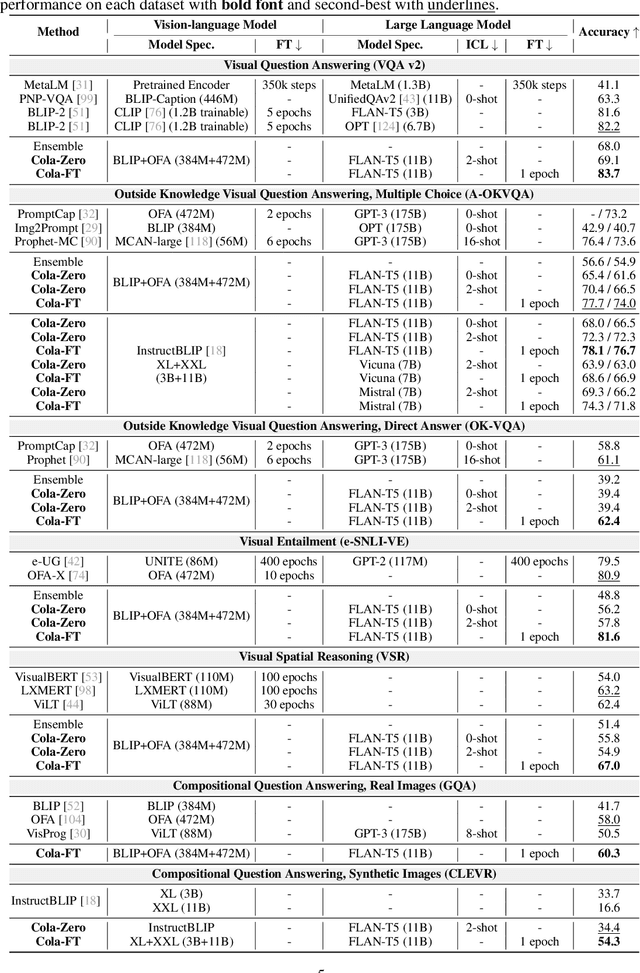

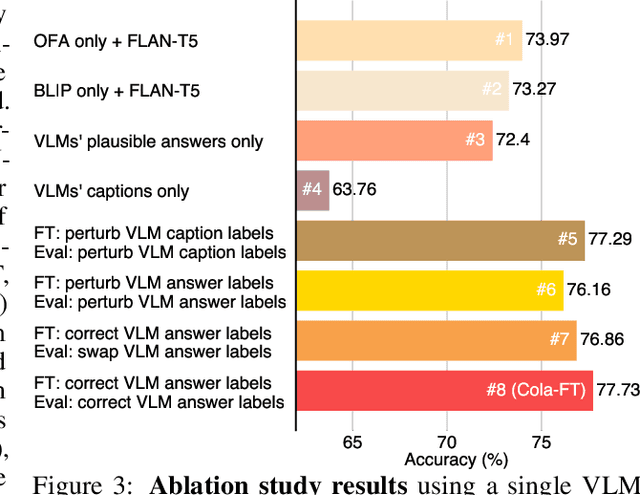
Visual reasoning requires multimodal perception and commonsense cognition of the world. Recently, multiple vision-language models (VLMs) have been proposed with excellent commonsense reasoning ability in various domains. However, how to harness the collective power of these complementary VLMs is rarely explored. Existing methods like ensemble still struggle to aggregate these models with the desired higher-order communications. In this work, we propose Cola, a novel paradigm that coordinates multiple VLMs for visual reasoning. Our key insight is that a large language model (LLM) can efficiently coordinate multiple VLMs by facilitating natural language communication that leverages their distinct and complementary capabilities. Extensive experiments demonstrate that our instruction tuning variant, Cola-FT, achieves state-of-the-art performance on visual question answering (VQA), outside knowledge VQA, visual entailment, and visual spatial reasoning tasks. Moreover, we show that our in-context learning variant, Cola-Zero, exhibits competitive performance in zero and few-shot settings, without finetuning. Through systematic ablation studies and visualizations, we validate that a coordinator LLM indeed comprehends the instruction prompts as well as the separate functionalities of VLMs; it then coordinates them to enable impressive visual reasoning capabilities.
From Text to Tactic: Evaluating LLMs Playing the Game of Avalon
Oct 10, 2023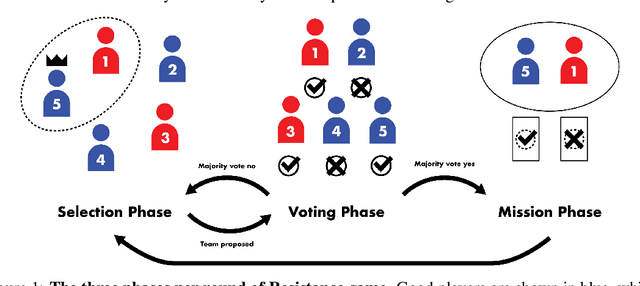

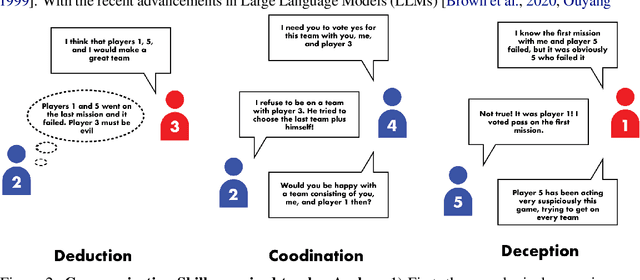
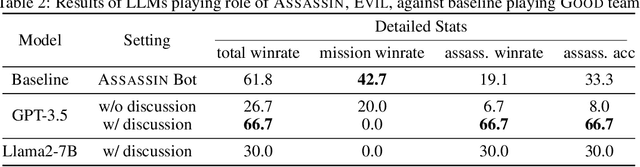
In this paper, we explore the potential of Large Language Models (LLMs) Agents in playing the strategic social deduction game, Resistance Avalon. Players in Avalon are challenged not only to make informed decisions based on dynamically evolving game phases, but also to engage in discussions where they must deceive, deduce, and negotiate with other players. These characteristics make Avalon a compelling test-bed to study the decision-making and language-processing capabilities of LLM Agents. To facilitate research in this line, we introduce AvalonBench - a comprehensive game environment tailored for evaluating multi-agent LLM Agents. This benchmark incorporates: (1) a game environment for Avalon, (2) rule-based bots as baseline opponents, and (3) ReAct-style LLM agents with tailored prompts for each role. Notably, our evaluations based on AvalonBench highlight a clear capability gap. For instance, models like ChatGPT playing good-role got a win rate of 22.2% against rule-based bots playing evil, while good-role bot achieves 38.2% win rate in the same setting. We envision AvalonBench could be a good test-bed for developing more advanced LLMs (with self-playing) and agent frameworks that can effectively model the layered complexities of such game environments.
HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Oct 03, 2023



Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.
Aligning Large Multimodal Models with Factually Augmented RLHF
Sep 25, 2023
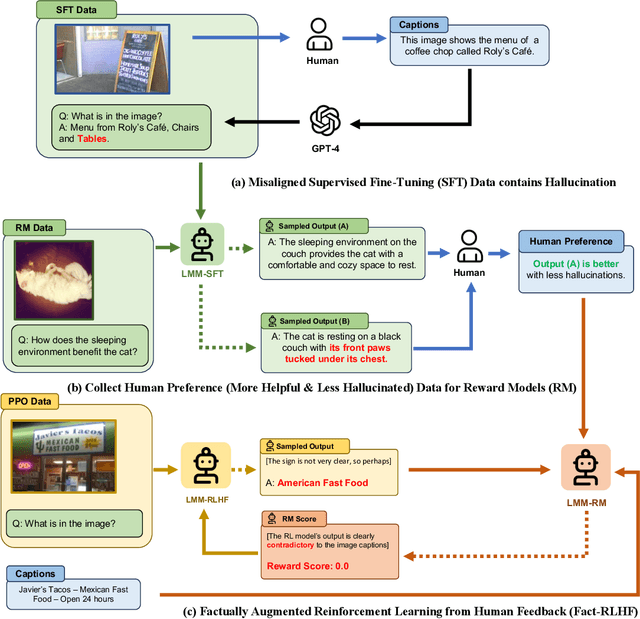

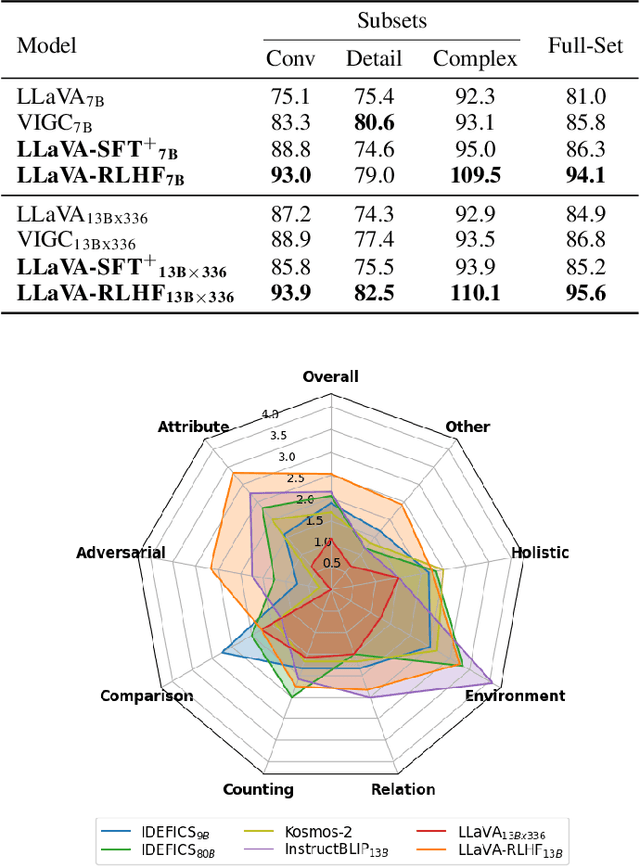
Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misalignment issue, we adapt the Reinforcement Learning from Human Feedback (RLHF) from the text domain to the task of vision-language alignment, where human annotators are asked to compare two responses and pinpoint the more hallucinated one, and the vision-language model is trained to maximize the simulated human rewards. We propose a new alignment algorithm called Factually Augmented RLHF that augments the reward model with additional factual information such as image captions and ground-truth multi-choice options, which alleviates the reward hacking phenomenon in RLHF and further improves the performance. We also enhance the GPT-4-generated training data (for vision instruction tuning) with previously available human-written image-text pairs to improve the general capabilities of our model. To evaluate the proposed approach in real-world scenarios, we develop a new evaluation benchmark MMHAL-BENCH with a special focus on penalizing hallucinations. As the first LMM trained with RLHF, our approach achieves remarkable improvement on the LLaVA-Bench dataset with the 94% performance level of the text-only GPT-4 (while previous best methods can only achieve the 87% level), and an improvement by 60% on MMHAL-BENCH over other baselines. We opensource our code, model, data at https://llava-rlhf.github.io.
AgentBench: Evaluating LLMs as Agents
Aug 07, 2023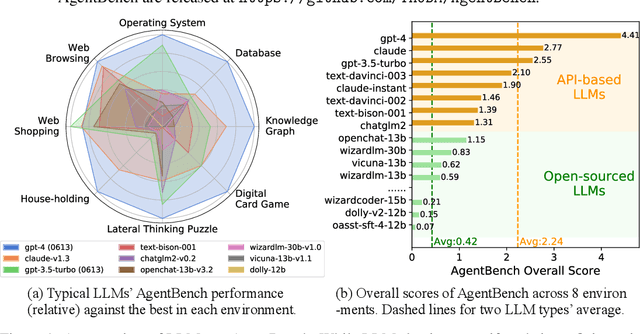
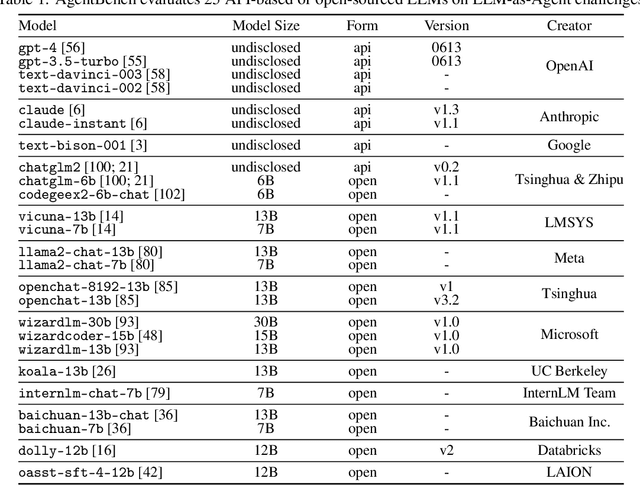
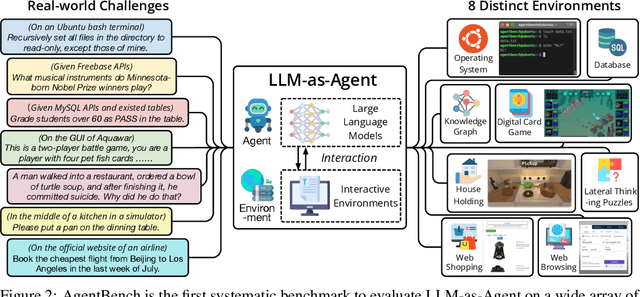
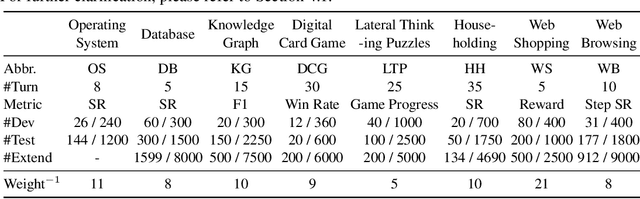
Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation. Datasets, environments, and an integrated evaluation package for AgentBench are released at https://github.com/THUDM/AgentBench
SqueezeLLM: Dense-and-Sparse Quantization
Jun 13, 2023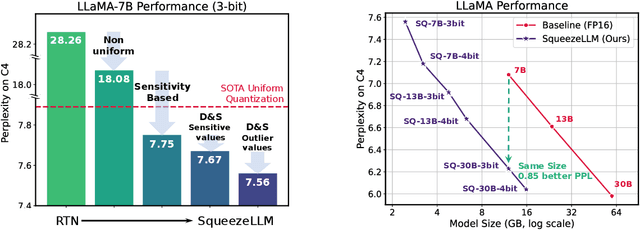

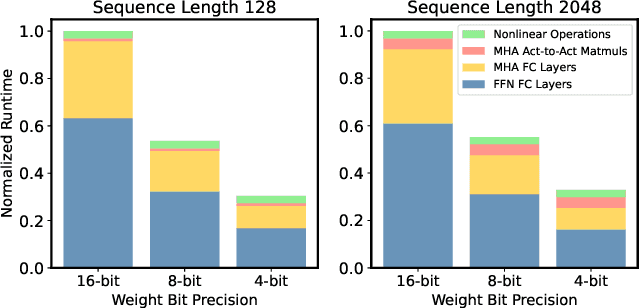
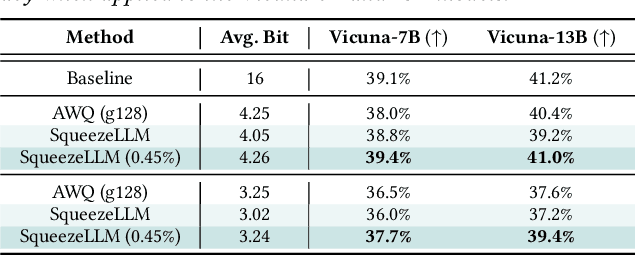
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing model weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is open-sourced and available online.