 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManling Li
Text-Based Reasoning About Vector Graphics
Apr 10, 2024
While large multimodal models excel in broad vision-language benchmarks, they often struggle with tasks requiring precise perception of low-level visual details, such as comparing line lengths or solving simple mazes. In particular, this failure mode persists in question-answering tasks about vector graphics -- images composed purely of 2D objects and shapes. To address this challenge, we propose the Visually Descriptive Language Model (VDLM), which performs text-based reasoning about vector graphics. VDLM leverages Scalable Vector Graphics (SVG) for a more precise visual description and first uses an off-the-shelf raster-to-SVG algorithm for encoding. Since existing language models cannot understand raw SVGs in a zero-shot setting, VDLM then bridges SVG with pretrained language models through a newly introduced intermediate symbolic representation, Primal Visual Description (PVD), comprising primitive attributes (e.g., shape, position, measurement) with their corresponding predicted values. PVD is task-agnostic and represents visual primitives that are universal across all vector graphics. It can be learned with procedurally generated (SVG, PVD) pairs and also enables the direct use of LLMs for generalization to complex reasoning tasks. By casting an image to a text-based representation, we can leverage the power of language models to learn alignment from SVG to visual primitives and generalize to unseen question-answering tasks. Empirical results show that VDLM achieves stronger zero-shot performance compared to state-of-the-art LMMs, such as GPT-4V, in various low-level multimodal perception and reasoning tasks on vector graphics. We additionally present extensive analyses on VDLM's performance, demonstrating that our framework offers better interpretability due to its disentangled perception and reasoning processes. Project page: https://mikewangwzhl.github.io/VDLM/
Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
Mar 26, 2024

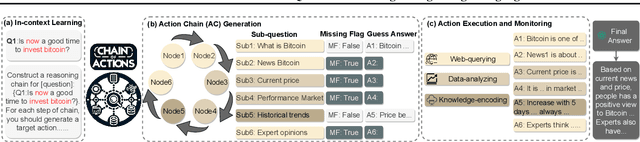
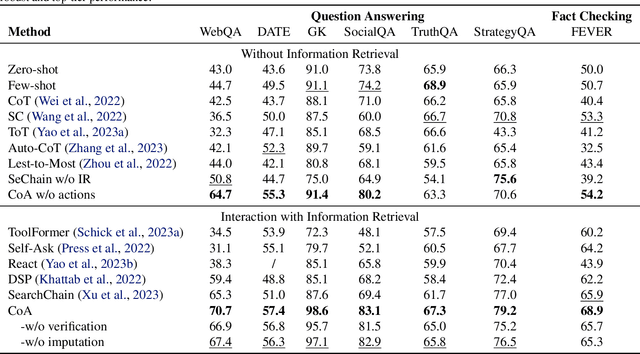
We present a Chain-of-Action (CoA) framework for multimodal and retrieval-augmented Question-Answering (QA). Compared to the literature, CoA overcomes two major challenges of current QA applications: (i) unfaithful hallucination that is inconsistent with real-time or domain facts and (ii) weak reasoning performance over compositional information. Our key contribution is a novel reasoning-retrieval mechanism that decomposes a complex question into a reasoning chain via systematic prompting and pre-designed actions. Methodologically, we propose three types of domain-adaptable `Plug-and-Play' actions for retrieving real-time information from heterogeneous sources. We also propose a multi-reference faith score (MRFS) to verify and resolve conflicts in the answers. Empirically, we exploit both public benchmarks and a Web3 case study to demonstrate the capability of CoA over other methods.
Can LLMs Produce Faithful Explanations For Fact-checking? Towards Faithful Explainable Fact-Checking via Multi-Agent Debate
Feb 12, 2024Fact-checking research has extensively explored verification but less so the generation of natural-language explanations, crucial for user trust. While Large Language Models (LLMs) excel in text generation, their capability for producing faithful explanations in fact-checking remains underexamined. Our study investigates LLMs' ability to generate such explanations, finding that zero-shot prompts often result in unfaithfulness. To address these challenges, we propose the Multi-Agent Debate Refinement (MADR) framework, leveraging multiple LLMs as agents with diverse roles in an iterative refining process aimed at enhancing faithfulness in generated explanations. MADR ensures that the final explanation undergoes rigorous validation, significantly reducing the likelihood of unfaithful elements and aligning closely with the provided evidence. Experimental results demonstrate that MADR significantly improves the faithfulness of LLM-generated explanations to the evidence, advancing the credibility and trustworthiness of these explanations.
InfoPattern: Unveiling Information Propagation Patterns in Social Media
Nov 27, 2023


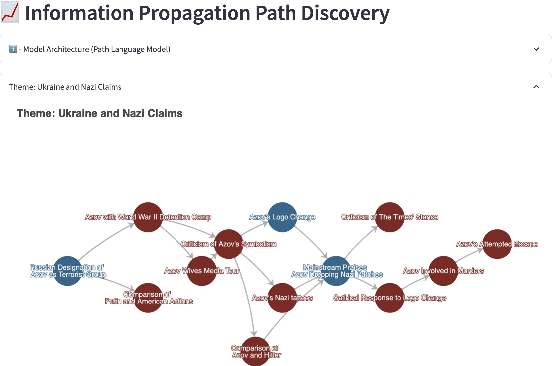
Social media play a significant role in shaping public opinion and influencing ideological communities through information propagation. Our demo InfoPattern centers on the interplay between language and human ideology. The demo (Code: https://github.com/blender-nlp/InfoPattern ) is capable of: (1) red teaming to simulate adversary responses from opposite ideology communities; (2) stance detection to identify the underlying political sentiments in each message; (3) information propagation graph discovery to reveal the evolution of claims across various communities over time. (Live Demo: https://incas.csl.illinois.edu/blender/About )
ViStruct: Visual Structural Knowledge Extraction via Curriculum Guided Code-Vision Representation
Nov 22, 2023
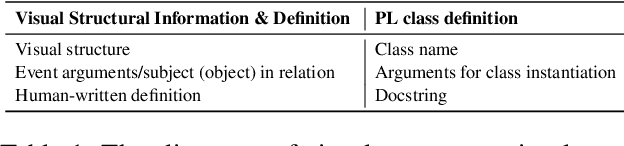


State-of-the-art vision-language models (VLMs) still have limited performance in structural knowledge extraction, such as relations between objects. In this work, we present ViStruct, a training framework to learn VLMs for effective visual structural knowledge extraction. Two novel designs are incorporated. First, we propose to leverage the inherent structure of programming language to depict visual structural information. This approach enables explicit and consistent representation of visual structural information of multiple granularities, such as concepts, relations, and events, in a well-organized structured format. Second, we introduce curriculum-based learning for VLMs to progressively comprehend visual structures, from fundamental visual concepts to intricate event structures. Our intuition is that lower-level knowledge may contribute to complex visual structure understanding. Furthermore, we compile and release a collection of datasets tailored for visual structural knowledge extraction. We adopt a weakly-supervised approach to directly generate visual event structures from captions for ViStruct training, capitalizing on abundant image-caption pairs from the web. In experiments, we evaluate ViStruct on visual structure prediction tasks, demonstrating its effectiveness in improving the understanding of visual structures. The code is public at \url{https://github.com/Yangyi-Chen/vi-struct}.
Defining a New NLP Playground
Oct 31, 2023The recent explosion of performance of large language models (LLMs) has changed the field of Natural Language Processing (NLP) more abruptly and seismically than any other shift in the field's 80-year history. This has resulted in concerns that the field will become homogenized and resource-intensive. The new status quo has put many academic researchers, especially PhD students, at a disadvantage. This paper aims to define a new NLP playground by proposing 20+ PhD-dissertation-worthy research directions, covering theoretical analysis, new and challenging problems, learning paradigms, and interdisciplinary applications.
Open Visual Knowledge Extraction via Relation-Oriented Multimodality Model Prompting
Oct 28, 2023

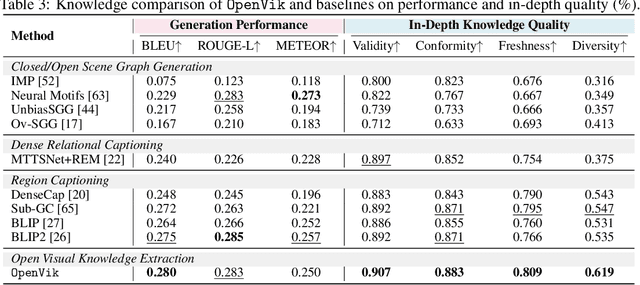
Images contain rich relational knowledge that can help machines understand the world. Existing methods on visual knowledge extraction often rely on the pre-defined format (e.g., sub-verb-obj tuples) or vocabulary (e.g., relation types), restricting the expressiveness of the extracted knowledge. In this work, we take a first exploration to a new paradigm of open visual knowledge extraction. To achieve this, we present OpenVik which consists of an open relational region detector to detect regions potentially containing relational knowledge and a visual knowledge generator that generates format-free knowledge by prompting the large multimodality model with the detected region of interest. We also explore two data enhancement techniques for diversifying the generated format-free visual knowledge. Extensive knowledge quality evaluations highlight the correctness and uniqueness of the extracted open visual knowledge by OpenVik. Moreover, integrating our extracted knowledge across various visual reasoning applications shows consistent improvements, indicating the real-world applicability of OpenVik.
HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Oct 03, 2023



Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.
Open-Domain Hierarchical Event Schema Induction by Incremental Prompting and Verification
Jul 05, 2023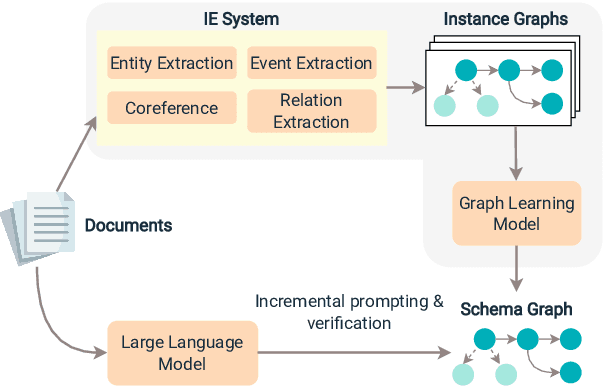


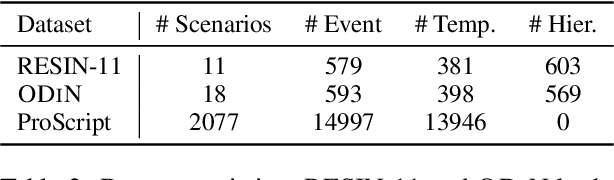
Event schemas are a form of world knowledge about the typical progression of events. Recent methods for event schema induction use information extraction systems to construct a large number of event graph instances from documents, and then learn to generalize the schema from such instances. In contrast, we propose to treat event schemas as a form of commonsense knowledge that can be derived from large language models (LLMs). This new paradigm greatly simplifies the schema induction process and allows us to handle both hierarchical relations and temporal relations between events in a straightforward way. Since event schemas have complex graph structures, we design an incremental prompting and verification method to break down the construction of a complex event graph into three stages: event skeleton construction, event expansion, and event-event relation verification. Compared to directly using LLMs to generate a linearized graph, our method can generate large and complex schemas with 7.2% F1 improvement in temporal relations and 31.0% F1 improvement in hierarchical relations. In addition, compared to the previous state-of-the-art closed-domain schema induction model, human assessors were able to cover $\sim$10% more events when translating the schemas into coherent stories and rated our schemas 1.3 points higher (on a 5-point scale) in terms of readability.
Non-Sequential Graph Script Induction via Multimedia Grounding
May 27, 2023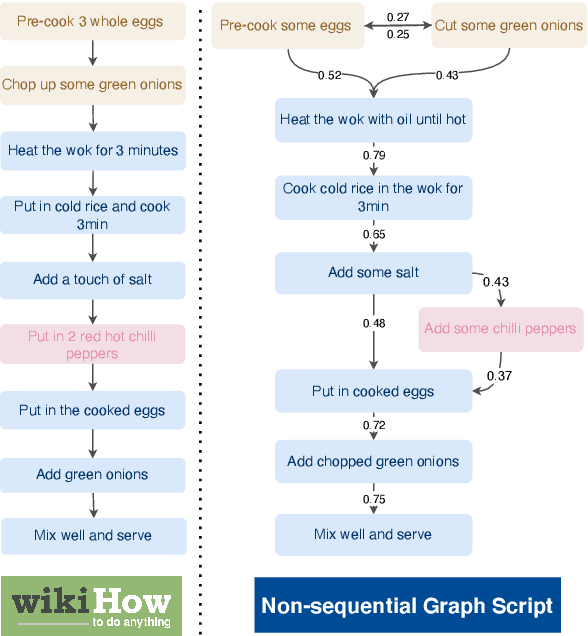
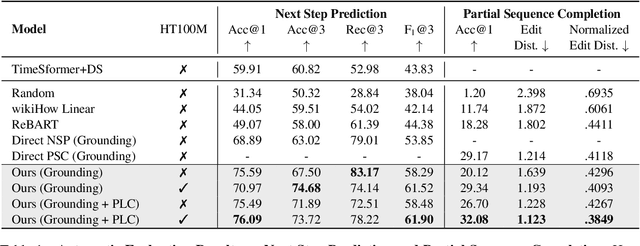
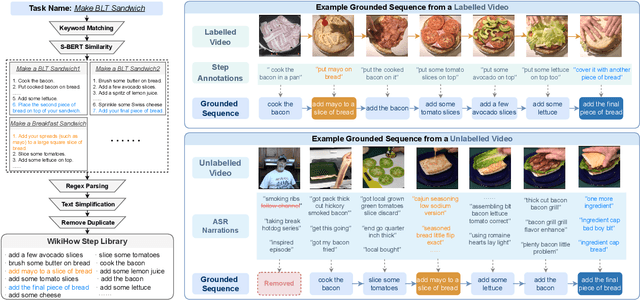
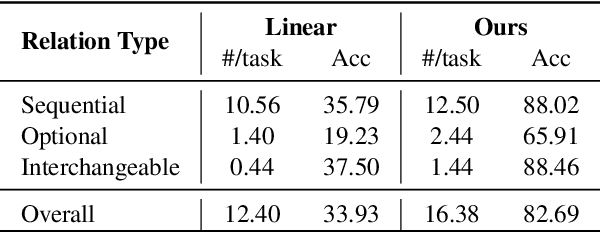
Online resources such as WikiHow compile a wide range of scripts for performing everyday tasks, which can assist models in learning to reason about procedures. However, the scripts are always presented in a linear manner, which does not reflect the flexibility displayed by people executing tasks in real life. For example, in the CrossTask Dataset, 64.5% of consecutive step pairs are also observed in the reverse order, suggesting their ordering is not fixed. In addition, each step has an average of 2.56 frequent next steps, demonstrating "branching". In this paper, we propose the new challenging task of non-sequential graph script induction, aiming to capture optional and interchangeable steps in procedural planning. To automate the induction of such graph scripts for given tasks, we propose to take advantage of loosely aligned videos of people performing the tasks. In particular, we design a multimodal framework to ground procedural videos to WikiHow textual steps and thus transform each video into an observed step path on the latent ground truth graph script. This key transformation enables us to train a script knowledge model capable of both generating explicit graph scripts for learnt tasks and predicting future steps given a partial step sequence. Our best model outperforms the strongest pure text/vision baselines by 17.52% absolute gains on F1@3 for next step prediction and 13.8% absolute gains on Acc@1 for partial sequence completion. Human evaluation shows our model outperforming the WikiHow linear baseline by 48.76% absolute gains in capturing sequential and non-sequential step relationships.