 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenyu Pan
Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
Mar 26, 2024


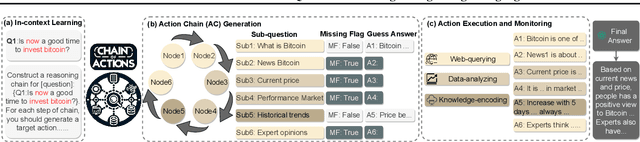
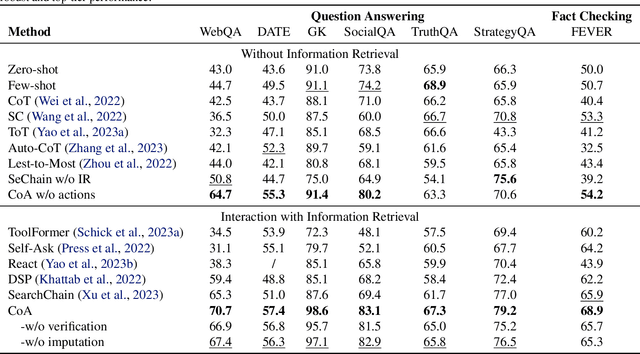
We present a Chain-of-Action (CoA) framework for multimodal and retrieval-augmented Question-Answering (QA). Compared to the literature, CoA overcomes two major challenges of current QA applications: (i) unfaithful hallucination that is inconsistent with real-time or domain facts and (ii) weak reasoning performance over compositional information. Our key contribution is a novel reasoning-retrieval mechanism that decomposes a complex question into a reasoning chain via systematic prompting and pre-designed actions. Methodologically, we propose three types of domain-adaptable `Plug-and-Play' actions for retrieving real-time information from heterogeneous sources. We also propose a multi-reference faith score (MRFS) to verify and resolve conflicts in the answers. Empirically, we exploit both public benchmarks and a Web3 case study to demonstrate the capability of CoA over other methods.
CoRMF: Criticality-Ordered Recurrent Mean Field Ising Solver
Mar 07, 2024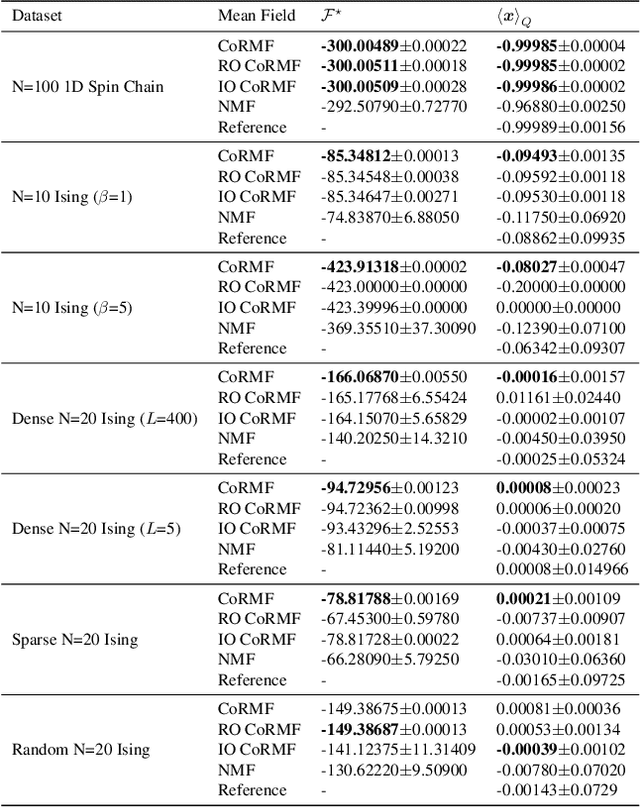
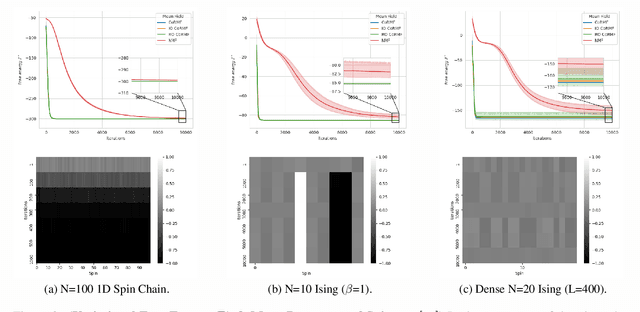
We propose an RNN-based efficient Ising model solver, the Criticality-ordered Recurrent Mean Field (CoRMF), for forward Ising problems. In its core, a criticality-ordered spin sequence of an $N$-spin Ising model is introduced by sorting mission-critical edges with greedy algorithm, such that an autoregressive mean-field factorization can be utilized and optimized with Recurrent Neural Networks (RNNs). Our method has two notable characteristics: (i) by leveraging the approximated tree structure of the underlying Ising graph, the newly-obtained criticality order enables the unification between variational mean-field and RNN, allowing the generally intractable Ising model to be efficiently probed with probabilistic inference; (ii) it is well-modulized, model-independent while at the same time expressive enough, and hence fully applicable to any forward Ising inference problems with minimal effort. Computationally, by using a variance-reduced Monte Carlo gradient estimator, CoRFM solves the Ising problems in a self-train fashion without data/evidence, and the inference tasks can be executed by directly sampling from RNN. Theoretically, we establish a provably tighter error bound than naive mean-field by using the matrix cut decomposition machineries. Numerically, we demonstrate the utility of this framework on a series of Ising datasets.
Object-Agnostic Suction Grasp Affordance Detection in Dense Cluster Using Self-Supervised Learning.docx
Jun 07, 2019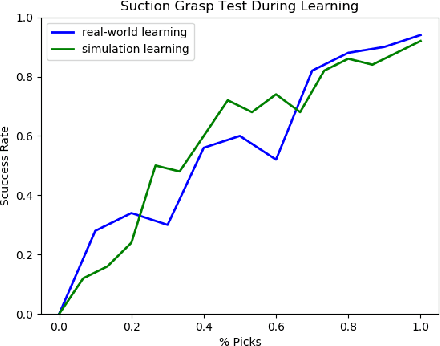
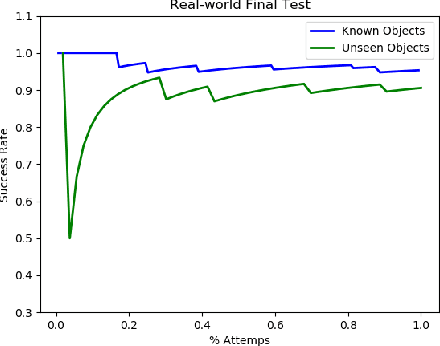
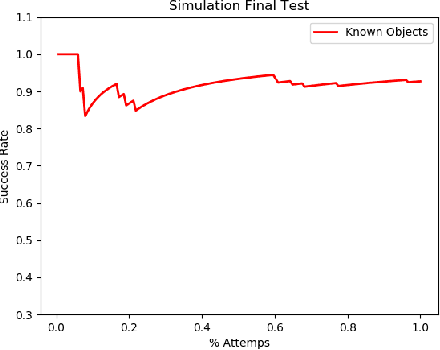
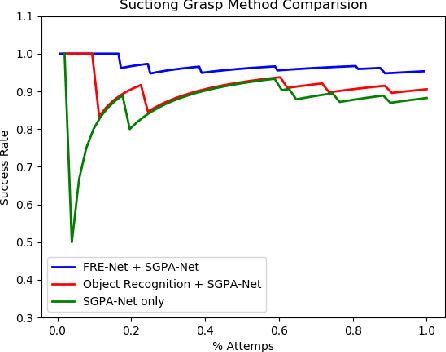
In this paper we study grasp problem in dense cluster, a challenging task in warehouse logistics scenario. By introducing a two-step robust suction affordance detection method, we focus on using vacuum suction pad to clear up a box filled with seen and unseen objects. Two CNN based neural networks are proposed. A Fast Region Estimation Network (FRE-Net) predicts which region contains pickable objects, and a Suction Grasp Point Affordance network (SGPA-Net) determines which point in that region is pickable. So as to enable such two networks, we design a self-supervised learning pipeline to accumulate data, train and test the performance of our method. In both virtual and real environment, within 1500 picks (~5 hours), we reach a picking accuracy of 95% for known objects and 90% for unseen objects with similar geometry features.
Bayesian Grasp: Robotic visual stable grasp based on prior tactile knowledge
May 30, 2019

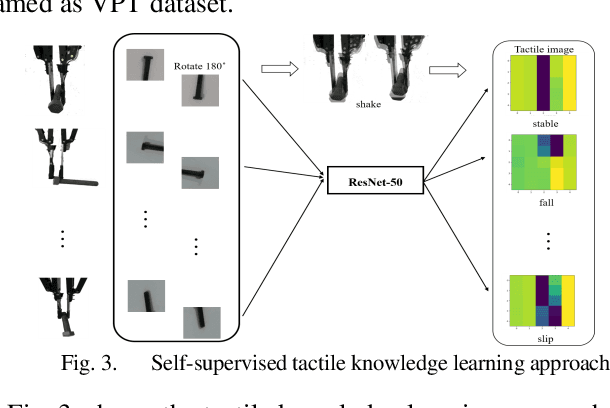
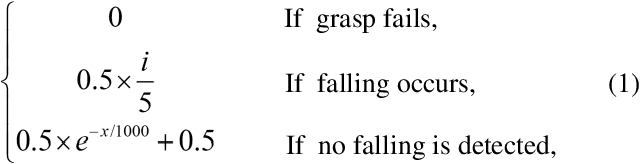
Robotic grasp detection is a fundamental capability for intelligent manipulation in unstructured environments. Previous work mainly employed visual and tactile fusion to achieve stable grasp, while, the whole process depending heavily on regrasping, which wastes much time to regulate and evaluate. We propose a novel way to improve robotic grasping: by using learned tactile knowledge, a robot can achieve a stable grasp from an image. First, we construct a prior tactile knowledge learning framework with novel grasp quality metric which is determined by measuring its resistance to external perturbations. Second, we propose a multi-phases Bayesian Grasp architecture to generate stable grasp configurations through a single RGB image based on prior tactile knowledge. Results show that this framework can classify the outcome of grasps with an average accuracy of 86% on known objects and 79% on novel objects. The prior tactile knowledge improves the successful rate of 55% over traditional vision-based strategies.