 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiming Wang
RPMArt: Towards Robust Perception and Manipulation for Articulated Objects
Mar 24, 2024
Articulated objects are commonly found in daily life. It is essential that robots can exhibit robust perception and manipulation skills for articulated objects in real-world robotic applications. However, existing methods for articulated objects insufficiently address noise in point clouds and struggle to bridge the gap between simulation and reality, thus limiting the practical deployment in real-world scenarios. To tackle these challenges, we propose a framework towards Robust Perception and Manipulation for Articulated Objects (RPMArt), which learns to estimate the articulation parameters and manipulate the articulation part from the noisy point cloud. Our primary contribution is a Robust Articulation Network (RoArtNet) that is able to predict both joint parameters and affordable points robustly by local feature learning and point tuple voting. Moreover, we introduce an articulation-aware classification scheme to enhance its ability for sim-to-real transfer. Finally, with the estimated affordable point and articulation joint constraint, the robot can generate robust actions to manipulate articulated objects. After learning only from synthetic data, RPMArt is able to transfer zero-shot to real-world articulated objects. Experimental results confirm our approach's effectiveness, with our framework achieving state-of-the-art performance in both noise-added simulation and real-world environments. The code and data will be open-sourced for reproduction. More results are published on the project website at https://r-pmart.github.io .
PointeNet: A Lightweight Framework for Effective and Efficient Point Cloud Analysis
Dec 20, 2023Current methodologies in point cloud analysis predominantly explore 3D geometries, often achieved through the introduction of intricate learnable geometric extractors in the encoder or by deepening networks with repeated blocks. However, these approaches inevitably lead to a significant number of learnable parameters, resulting in substantial computational costs and imposing memory burdens on CPU/GPU. Additionally, the existing strategies are primarily tailored for object-level point cloud classification and segmentation tasks, with limited extensions to crucial scene-level applications, such as autonomous driving. In response to these limitations, we introduce PointeNet, an efficient network designed specifically for point cloud analysis. PointeNet distinguishes itself with its lightweight architecture, low training cost, and plug-and-play capability, effectively capturing representative features. The network consists of a Multivariate Geometric Encoding (MGE) module and an optional Distance-aware Semantic Enhancement (DSE) module. The MGE module employs operations of sampling, grouping, and multivariate geometric aggregation to lightweightly capture and adaptively aggregate multivariate geometric features, providing a comprehensive depiction of 3D geometries. The DSE module, designed for real-world autonomous driving scenarios, enhances the semantic perception of point clouds, particularly for distant points. Our method demonstrates flexibility by seamlessly integrating with a classification/segmentation head or embedding into off-the-shelf 3D object detection networks, achieving notable performance improvements at a minimal cost. Extensive experiments on object-level datasets, including ModelNet40, ScanObjectNN, ShapeNetPart, and the scene-level dataset KITTI, demonstrate the superior performance of PointeNet over state-of-the-art methods in point cloud analysis.
GAMMA: Generalizable Articulation Modeling and Manipulation for Articulated Objects
Oct 04, 2023
Articulated objects like cabinets and doors are widespread in daily life. However, directly manipulating 3D articulated objects is challenging because they have diverse geometrical shapes, semantic categories, and kinetic constraints. Prior works mostly focused on recognizing and manipulating articulated objects with specific joint types. They can either estimate the joint parameters or distinguish suitable grasp poses to facilitate trajectory planning. Although these approaches have succeeded in certain types of articulated objects, they lack generalizability to unseen objects, which significantly impedes their application in broader scenarios. In this paper, we propose a novel framework of Generalizable Articulation Modeling and Manipulating for Articulated Objects (GAMMA), which learns both articulation modeling and grasp pose affordance from diverse articulated objects with different categories. In addition, GAMMA adopts adaptive manipulation to iteratively reduce the modeling errors and enhance manipulation performance. We train GAMMA with the PartNet-Mobility dataset and evaluate with comprehensive experiments in SAPIEN simulation and real-world Franka robot. Results show that GAMMA significantly outperforms SOTA articulation modeling and manipulation algorithms in unseen and cross-category articulated objects. We will open-source all codes and datasets in both simulation and real robots for reproduction in the final version. Images and videos are published on the project website at: http://sites.google.com/view/gamma-articulation
Low-Cost Exoskeletons for Learning Whole-Arm Manipulation in the Wild
Sep 26, 2023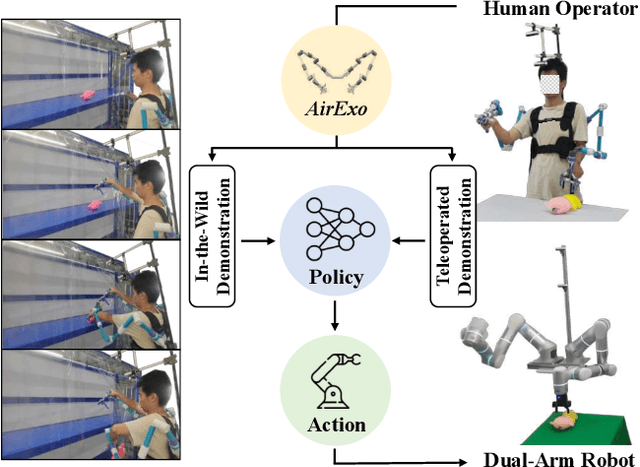



While humans can use parts of their arms other than the hands for manipulations like gathering and supporting, whether robots can effectively learn and perform the same type of operations remains relatively unexplored. As these manipulations require joint-level control to regulate the complete poses of the robots, we develop AirExo, a low-cost, adaptable, and portable dual-arm exoskeleton, for teleoperation and demonstration collection. As collecting teleoperated data is expensive and time-consuming, we further leverage AirExo to collect cheap in-the-wild demonstrations at scale. Under our in-the-wild learning framework, we show that with only 3 minutes of the teleoperated demonstrations, augmented by diverse and extensive in-the-wild data collected by AirExo, robots can learn a policy that is comparable to or even better than one learned from teleoperated demonstrations lasting over 20 minutes. Experiments demonstrate that our approach enables the model to learn a more general and robust policy across the various stages of the task, enhancing the success rates in task completion even with the presence of disturbances. Project website: https://airexo.github.io/
Video Adverse-Weather-Component Suppression Network via Weather Messenger and Adversarial Backpropagation
Sep 24, 2023Although convolutional neural networks (CNNs) have been proposed to remove adverse weather conditions in single images using a single set of pre-trained weights, they fail to restore weather videos due to the absence of temporal information. Furthermore, existing methods for removing adverse weather conditions (e.g., rain, fog, and snow) from videos can only handle one type of adverse weather. In this work, we propose the first framework for restoring videos from all adverse weather conditions by developing a video adverse-weather-component suppression network (ViWS-Net). To achieve this, we first devise a weather-agnostic video transformer encoder with multiple transformer stages. Moreover, we design a long short-term temporal modeling mechanism for weather messenger to early fuse input adjacent video frames and learn weather-specific information. We further introduce a weather discriminator with gradient reversion, to maintain the weather-invariant common information and suppress the weather-specific information in pixel features, by adversarially predicting weather types. Finally, we develop a messenger-driven video transformer decoder to retrieve the residual weather-specific feature, which is spatiotemporally aggregated with hierarchical pixel features and refined to predict the clean target frame of input videos. Experimental results, on benchmark datasets and real-world weather videos, demonstrate that our ViWS-Net outperforms current state-of-the-art methods in terms of restoring videos degraded by any weather condition.
SVDFormer: Complementing Point Cloud via Self-view Augmentation and Self-structure Dual-generator
Jul 17, 2023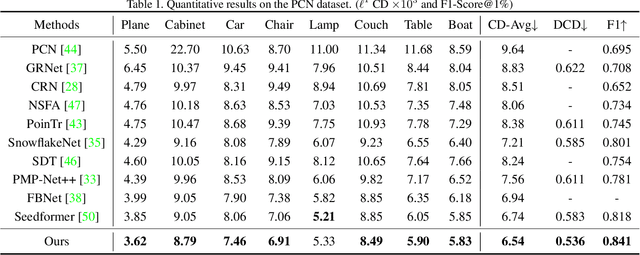
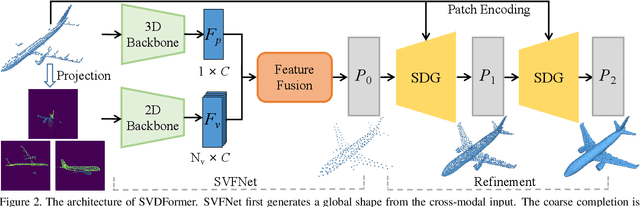
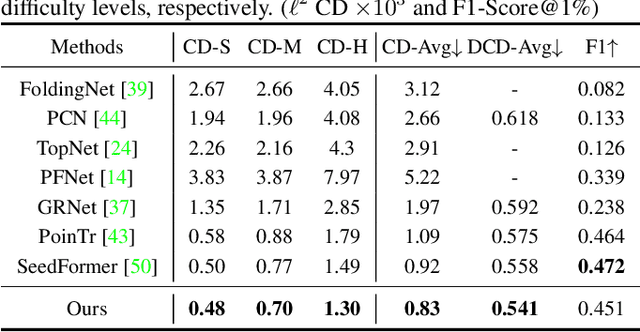
In this paper, we propose a novel network, SVDFormer, to tackle two specific challenges in point cloud completion: understanding faithful global shapes from incomplete point clouds and generating high-accuracy local structures. Current methods either perceive shape patterns using only 3D coordinates or import extra images with well-calibrated intrinsic parameters to guide the geometry estimation of the missing parts. However, these approaches do not always fully leverage the cross-modal self-structures available for accurate and high-quality point cloud completion. To this end, we first design a Self-view Fusion Network that leverages multiple-view depth image information to observe incomplete self-shape and generate a compact global shape. To reveal highly detailed structures, we then introduce a refinement module, called Self-structure Dual-generator, in which we incorporate learned shape priors and geometric self-similarities for producing new points. By perceiving the incompleteness of each point, the dual-path design disentangles refinement strategies conditioned on the structural type of each point. SVDFormer absorbs the wisdom of self-structures, avoiding any additional paired information such as color images with precisely calibrated camera intrinsic parameters. Comprehensive experiments indicate that our method achieves state-of-the-art performance on widely-used benchmarks. Code will be available at https://github.com/czvvd/SVDFormer.
CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference Frame
Mar 06, 2023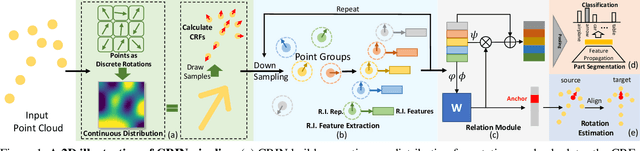
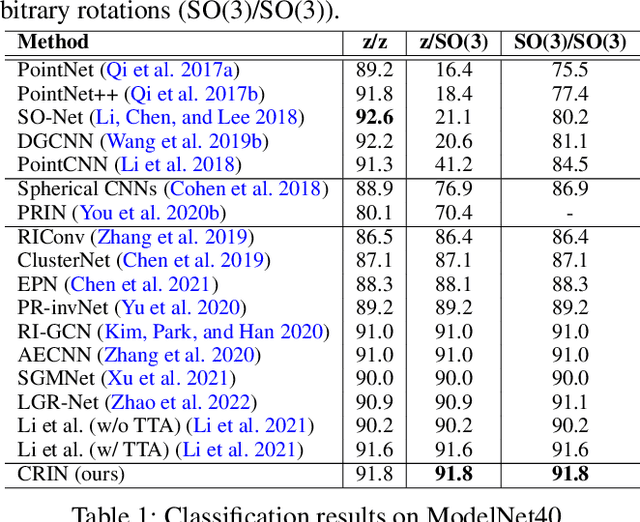
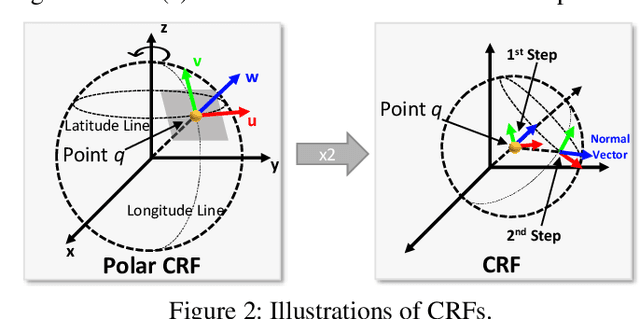
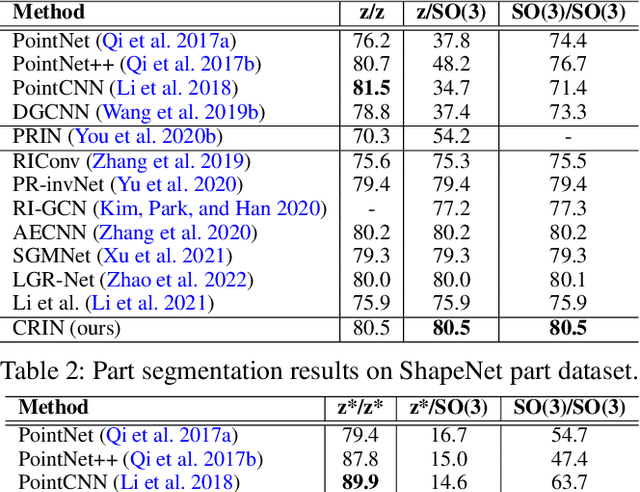
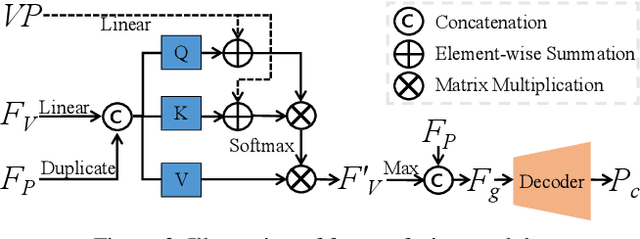
Various recent methods attempt to implement rotation-invariant 3D deep learning by replacing the input coordinates of points with relative distances and angles. Due to the incompleteness of these low-level features, they have to undertake the expense of losing global information. In this paper, we propose the CRIN, namely Centrifugal Rotation-Invariant Network. CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames. Aided by centrifugal reference frames, each point corresponds to a discrete rotation so that the information of rotations can be implicitly stored in point features. Unfortunately, discrete points are far from describing the whole rotation space. We further introduce a continuous distribution for 3D rotations based on points. Furthermore, we propose an attention-based down-sampling strategy to sample points invariant to rotations. A relation module is adopted at last for reinforcing the long-range dependencies between sampled points and predicts the anchor point for unsupervised rotation estimation. Extensive experiments show that our method achieves rotation invariance, accurately estimates the object rotation, and obtains state-of-the-art results on rotation-augmented classification and part segmentation. Ablation studies validate the effectiveness of the network design.
Go Beyond Point Pairs: A General and Accurate Sim2Real Object Pose Voting Method with Efficient Online Synthetic Training
Nov 24, 2022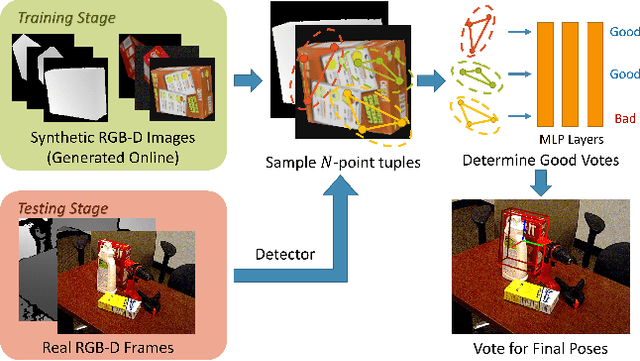
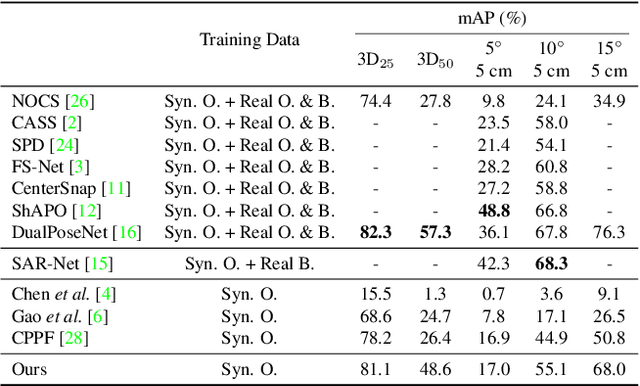

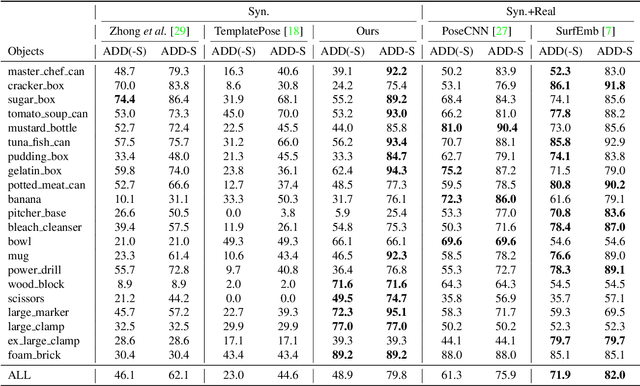
Object pose estimation is an important topic in 3D vision. Though most current state-of-the-art method that trains on real-world pose annotations achieve good results, the cost of such real-world training data is too high. In this paper, we propose a novel method for sim-to-real pose estimation, which is effective on both instance-level and category-level settings. The proposed method is based on the point-pair voting scheme from CPPF to vote for object centers, orientations, and scales. Unlike naive point pairs, to enrich the context provided by each voting unit, we introduce N-point tuples to fuse features from more than two points. Besides, a novel vote selection module is leveraged in order to discard those `bad' votes. Experiments show that our proposed method greatly advances the performance on both instance-level and category-level scenarios. Our method further narrows the gap between sim-to-real and real-training methods by generating synthetic training data online efficiently, while all previous sim-to-real methods need to generate data offline, because of their complex background synthesizing or photo-realistic rendering. Code repository: https://github.com/qq456cvb/BeyondPPF.
One-Shot General Object Localization
Nov 24, 2022
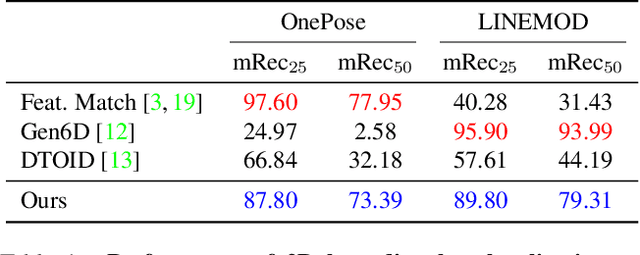

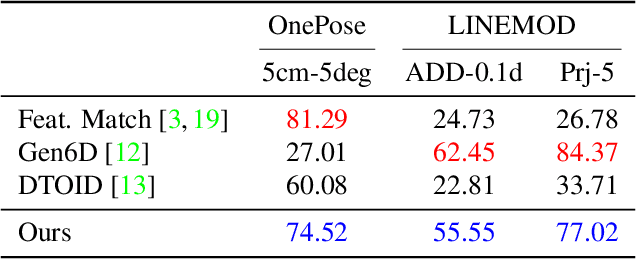
This paper presents a general one-shot object localization algorithm called OneLoc. Current one-shot object localization or detection methods either rely on a slow exhaustive feature matching process or lack the ability to generalize to novel objects. In contrast, our proposed OneLoc algorithm efficiently finds the object center and bounding box size by a special voting scheme. To keep our method scale-invariant, only unit center offset directions and relative sizes are estimated. A novel dense equalized voting module is proposed to better locate small texture-less objects. Experiments show that the proposed method achieves state-of-the-art overall performance on two datasets: OnePose dataset and LINEMOD dataset. In addition, our method can also achieve one-shot multi-instance detection and non-rigid object localization. Code repository: https://github.com/qq456cvb/OneLoc.
LBF:Learnable Bilateral Filter For Point Cloud Denoising
Oct 28, 2022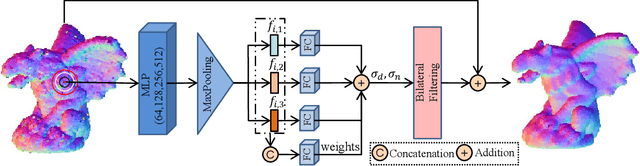
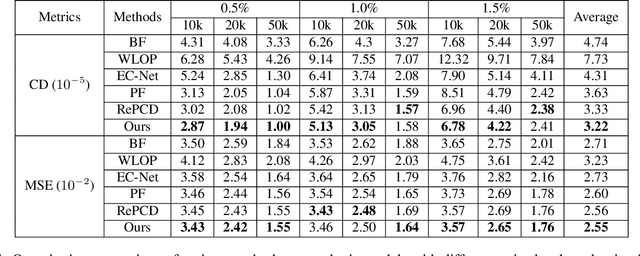
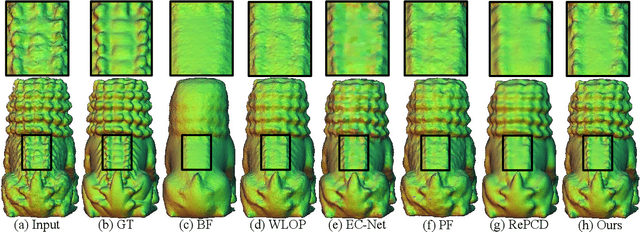
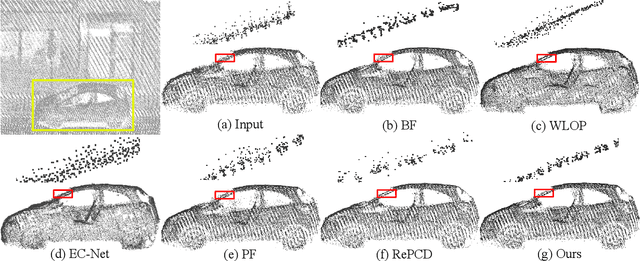
Bilateral filter (BF) is a fast, lightweight and effective tool for image denoising and well extended to point cloud denoising. However, it often involves continual yet manual parameter adjustment; this inconvenience discounts the efficiency and user experience to obtain satisfied denoising results. We propose LBF, an end-to-end learnable bilateral filtering network for point cloud denoising; to our knowledge, this is the first time. Unlike the conventional BF and its variants that receive the same parameters for a whole point cloud, LBF learns adaptive parameters for each point according its geometric characteristic (e.g., corner, edge, plane), avoiding remnant noise, wrongly-removed geometric details, and distorted shapes. Besides the learnable paradigm of BF, we have two cores to facilitate LBF. First, different from the local BF, LBF possesses a global-scale feature perception ability by exploiting multi-scale patches of each point. Second, LBF formulates a geometry-aware bi-directional projection loss, leading the denoising results to being faithful to their underlying surfaces. Users can apply our LBF without any laborious parameter tuning to achieve the optimal denoising results. Experiments show clear improvements of LBF over its competitors on both synthetic and real-scanned datasets.