 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiniu Hu
Thought Graph: Generating Thought Process for Biological Reasoning
Mar 11, 2024
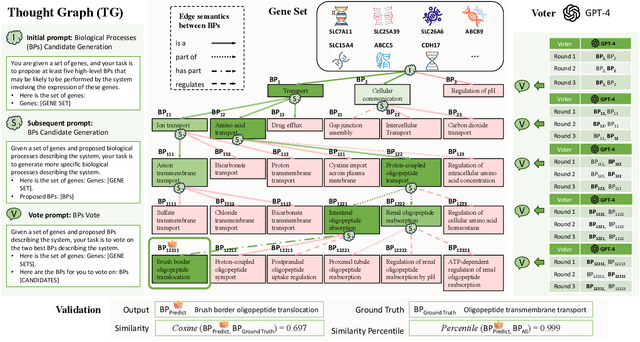
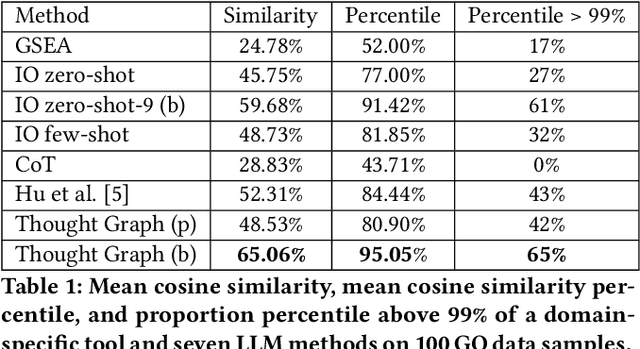
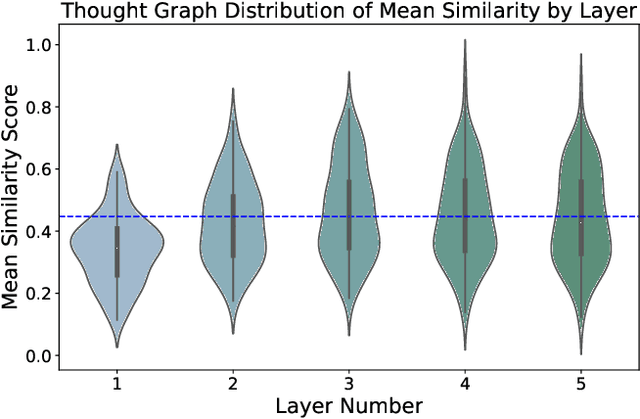
We present the Thought Graph as a novel framework to support complex reasoning and use gene set analysis as an example to uncover semantic relationships between biological processes. Our framework stands out for its ability to provide a deeper understanding of gene sets, significantly surpassing GSEA by 40.28% and LLM baselines by 5.38% based on cosine similarity to human annotations. Our analysis further provides insights into future directions of biological processes naming, and implications for bioinformatics and precision medicine.
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code
Mar 02, 2024
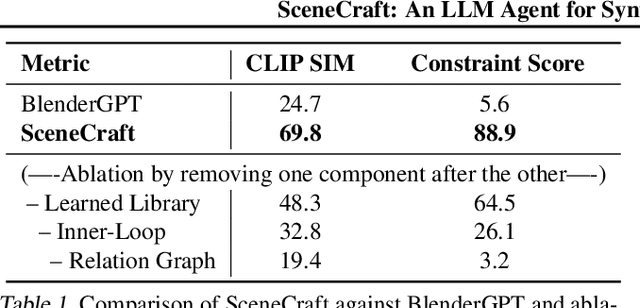
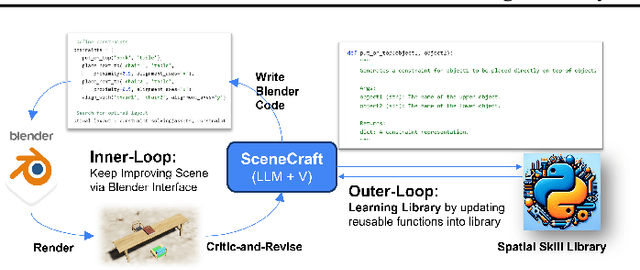
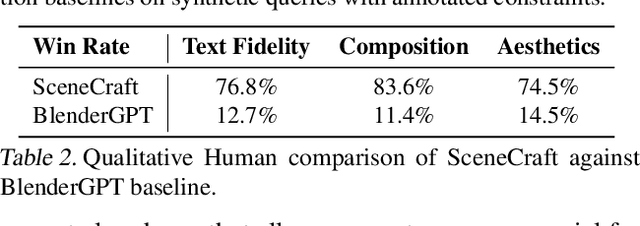
This paper introduces SceneCraft, a Large Language Model (LLM) Agent converting text descriptions into Blender-executable Python scripts which render complex scenes with up to a hundred 3D assets. This process requires complex spatial planning and arrangement. We tackle these challenges through a combination of advanced abstraction, strategic planning, and library learning. SceneCraft first models a scene graph as a blueprint, detailing the spatial relationships among assets in the scene. SceneCraft then writes Python scripts based on this graph, translating relationships into numerical constraints for asset layout. Next, SceneCraft leverages the perceptual strengths of vision-language foundation models like GPT-V to analyze rendered images and iteratively refine the scene. On top of this process, SceneCraft features a library learning mechanism that compiles common script functions into a reusable library, facilitating continuous self-improvement without expensive LLM parameter tuning. Our evaluation demonstrates that SceneCraft surpasses existing LLM-based agents in rendering complex scenes, as shown by its adherence to constraints and favorable human assessments. We also showcase the broader application potential of SceneCraft by reconstructing detailed 3D scenes from the Sintel movie and guiding a video generative model with generated scenes as intermediary control signal.
Symbolic Music Generation with Non-Differentiable Rule Guided Diffusion
Feb 23, 2024We study the problem of symbolic music generation (e.g., generating piano rolls), with a technical focus on non-differentiable rule guidance. Musical rules are often expressed in symbolic form on note characteristics, such as note density or chord progression, many of which are non-differentiable which pose a challenge when using them for guided diffusion. We propose Stochastic Control Guidance (SCG), a novel guidance method that only requires forward evaluation of rule functions that can work with pre-trained diffusion models in a plug-and-play way, thus achieving training-free guidance for non-differentiable rules for the first time. Additionally, we introduce a latent diffusion architecture for symbolic music generation with high time resolution, which can be composed with SCG in a plug-and-play fashion. Compared to standard strong baselines in symbolic music generation, this framework demonstrates marked advancements in music quality and rule-based controllability, outperforming current state-of-the-art generators in a variety of settings. For detailed demonstrations, code and model checkpoints, please visit our project website: https://scg-rule-guided-music.github.io/.
Can Large Language Model Agents Simulate Human Trust Behaviors?
Feb 07, 2024Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in applications such as social science. However, one fundamental question remains: can LLM agents really simulate human behaviors? In this paper, we focus on one of the most critical behaviors in human interactions, trust, and aim to investigate whether or not LLM agents can simulate human trust behaviors. We first find that LLM agents generally exhibit trust behaviors, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that LLM agents can have high behavioral alignment with humans regarding trust behaviors, indicating the feasibility to simulate human trust behaviors with LLM agents. In addition, we probe into the biases in agent trust and the differences in agent trust towards agents and humans. We also explore the intrinsic properties of agent trust under conditions including advanced reasoning strategies and external manipulations. We further offer important implications for various scenarios where trust is paramount. Our study represents a significant step in understanding the behaviors of LLM agents and the LLM-human analogy.
SciGLM: Training Scientific Language Models with Self-Reflective Instruction Annotation and Tuning
Jan 15, 2024\label{sec:abstract} Large Language Models (LLMs) have shown promise in assisting scientific discovery. However, such applications are currently limited by LLMs' deficiencies in understanding intricate scientific concepts, deriving symbolic equations, and solving advanced numerical calculations. To bridge these gaps, we introduce SciGLM, a suite of scientific language models able to conduct college-level scientific reasoning. Central to our approach is a novel self-reflective instruction annotation framework to address the data scarcity challenge in the science domain. This framework leverages existing LLMs to generate step-by-step reasoning for unlabelled scientific questions, followed by a process of self-reflective critic-and-revise. Applying this framework, we curated SciInstruct, a diverse and high-quality dataset encompassing mathematics, physics, chemistry, and formal proofs. We fine-tuned the ChatGLM family of language models with SciInstruct, enhancing their capabilities in scientific and mathematical reasoning. Remarkably, SciGLM consistently improves both the base model (ChatGLM3-6B-Base) and larger-scale models (12B and 32B), without sacrificing the language understanding capabilities of the base model. This makes SciGLM a suitable foundational model to facilitate diverse scientific discovery tasks. For the benefit of the wider research community, we release SciInstruct, SciGLM, alongside a self-reflective framework and fine-tuning code at \url{https://github.com/THUDM/SciGLM}.
From Text to Tactic: Evaluating LLMs Playing the Game of Avalon
Oct 10, 2023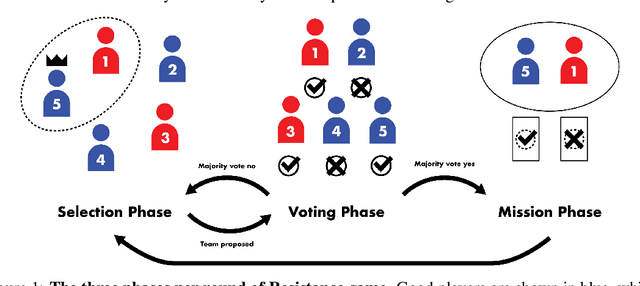

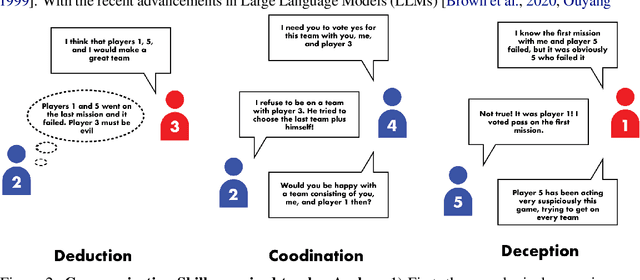
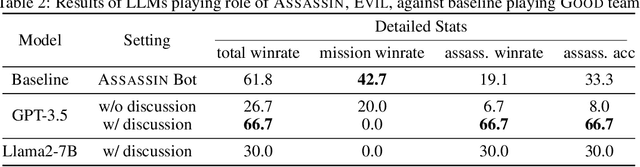
In this paper, we explore the potential of Large Language Models (LLMs) Agents in playing the strategic social deduction game, Resistance Avalon. Players in Avalon are challenged not only to make informed decisions based on dynamically evolving game phases, but also to engage in discussions where they must deceive, deduce, and negotiate with other players. These characteristics make Avalon a compelling test-bed to study the decision-making and language-processing capabilities of LLM Agents. To facilitate research in this line, we introduce AvalonBench - a comprehensive game environment tailored for evaluating multi-agent LLM Agents. This benchmark incorporates: (1) a game environment for Avalon, (2) rule-based bots as baseline opponents, and (3) ReAct-style LLM agents with tailored prompts for each role. Notably, our evaluations based on AvalonBench highlight a clear capability gap. For instance, models like ChatGPT playing good-role got a win rate of 22.2% against rule-based bots playing evil, while good-role bot achieves 38.2% win rate in the same setting. We envision AvalonBench could be a good test-bed for developing more advanced LLMs (with self-playing) and agent frameworks that can effectively model the layered complexities of such game environments.
TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems
Oct 10, 2023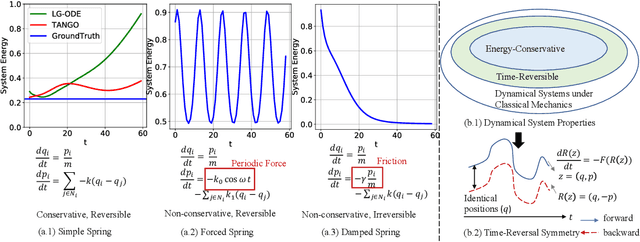
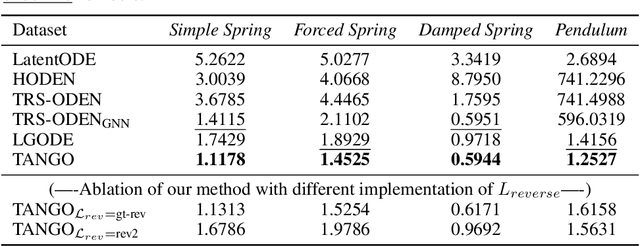
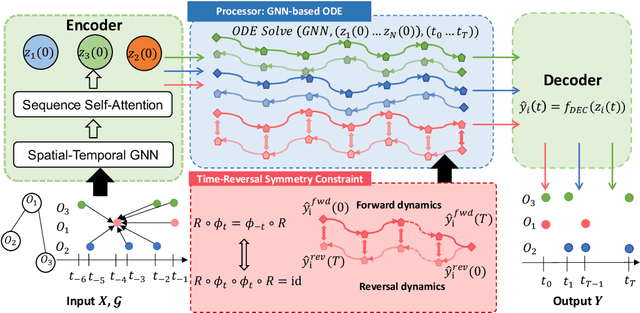
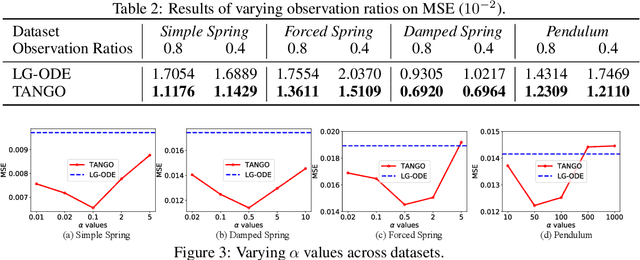
Learning complex multi-agent system dynamics from data is crucial across many domains, such as in physical simulations and material modeling. Extended from purely data-driven approaches, existing physics-informed approaches such as Hamiltonian Neural Network strictly follow energy conservation law to introduce inductive bias, making their learning more sample efficiently. However, many real-world systems do not strictly conserve energy, such as spring systems with frictions. Recognizing this, we turn our attention to a broader physical principle: Time-Reversal Symmetry, which depicts that the dynamics of a system shall remain invariant when traversed back over time. It still helps to preserve energies for conservative systems and in the meanwhile, serves as a strong inductive bias for non-conservative, reversible systems. To inject such inductive bias, in this paper, we propose a simple-yet-effective self-supervised regularization term as a soft constraint that aligns the forward and backward trajectories predicted by a continuous graph neural network-based ordinary differential equation (GraphODE). It effectively imposes time-reversal symmetry to enable more accurate model predictions across a wider range of dynamical systems under classical mechanics. In addition, we further provide theoretical analysis to show that our regularization essentially minimizes higher-order Taylor expansion terms during the ODE integration steps, which enables our model to be more noise-tolerant and even applicable to irreversible systems. Experimental results on a variety of physical systems demonstrate the effectiveness of our proposed method. Particularly, it achieves an MSE improvement of 11.5 % on a challenging chaotic triple-pendulum systems.
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Jul 20, 2023

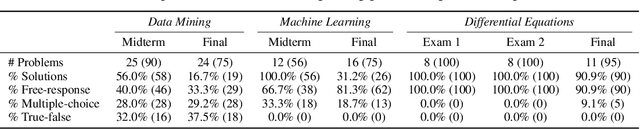

Recent advances in large language models (LLMs) have demonstrated notable progress on many mathematical benchmarks. However, most of these benchmarks only feature problems grounded in junior and senior high school subjects, contain only multiple-choice questions, and are confined to a limited scope of elementary arithmetic operations. To address these issues, this paper introduces an expansive benchmark suite SciBench that aims to systematically examine the reasoning capabilities required for complex scientific problem solving. SciBench contains two carefully curated datasets: an open set featuring a range of collegiate-level scientific problems drawn from mathematics, chemistry, and physics textbooks, and a closed set comprising problems from undergraduate-level exams in computer science and mathematics. Based on the two datasets, we conduct an in-depth benchmark study of two representative LLMs with various prompting strategies. The results reveal that current LLMs fall short of delivering satisfactory performance, with an overall score of merely 35.80%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms others and some strategies that demonstrate improvements in certain problem-solving skills result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.
Learning to Group Auxiliary Datasets for Molecule
Jul 08, 2023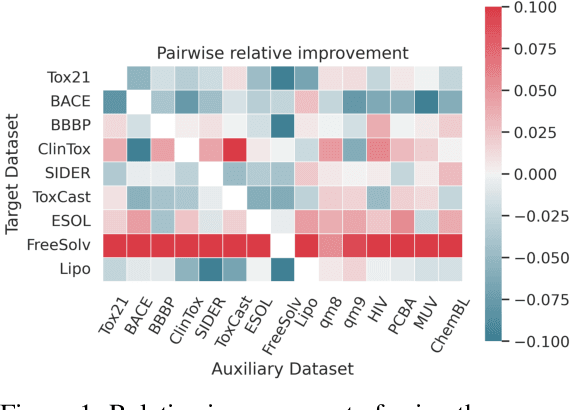
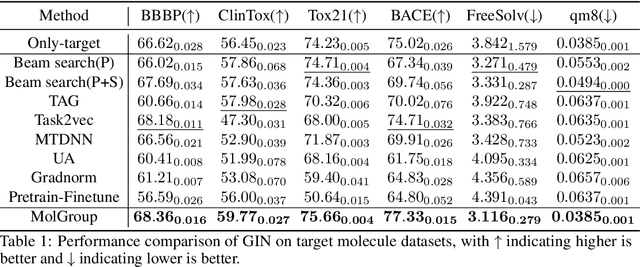
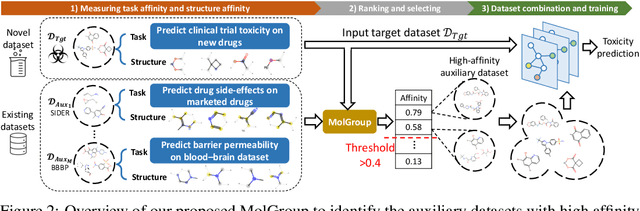
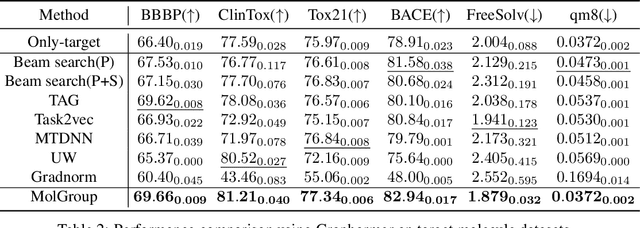
The limited availability of annotations in small molecule datasets presents a challenge to machine learning models. To address this, one common strategy is to collaborate with additional auxiliary datasets. However, having more data does not always guarantee improvements. Negative transfer can occur when the knowledge in the target dataset differs or contradicts that of the auxiliary molecule datasets. In light of this, identifying the auxiliary molecule datasets that can benefit the target dataset when jointly trained remains a critical and unresolved problem. Through an empirical analysis, we observe that combining graph structure similarity and task similarity can serve as a more reliable indicator for identifying high-affinity auxiliary datasets. Motivated by this insight, we propose MolGroup, which separates the dataset affinity into task and structure affinity to predict the potential benefits of each auxiliary molecule dataset. MolGroup achieves this by utilizing a routing mechanism optimized through a bi-level optimization framework. Empowered by the meta gradient, the routing mechanism is optimized toward maximizing the target dataset's performance and quantifies the affinity as the gating score. As a result, MolGroup is capable of predicting the optimal combination of auxiliary datasets for each target dataset. Our extensive experiments demonstrate the efficiency and effectiveness of MolGroup, showing an average improvement of 4.41%/3.47% for GIN/Graphormer trained with the group of molecule datasets selected by MolGroup on 11 target molecule datasets.
A Survey on Graph Neural Network Acceleration: Algorithms, Systems, and Customized Hardware
Jun 24, 2023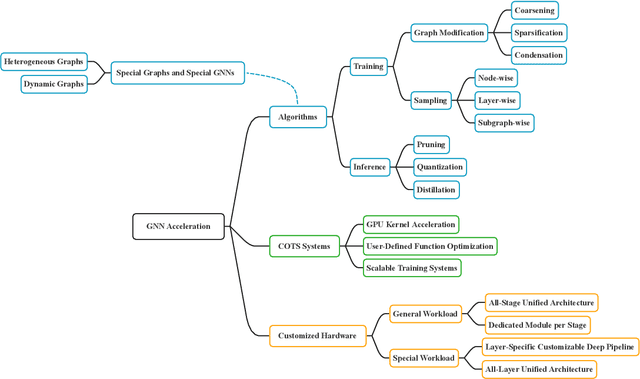
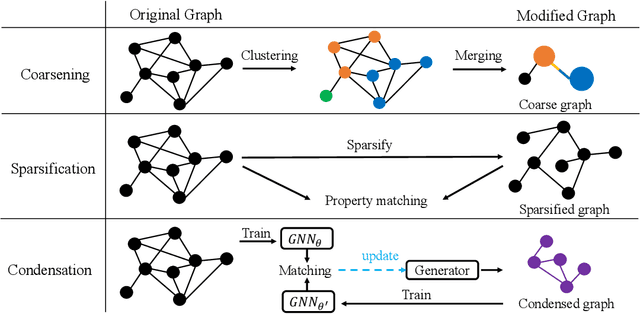
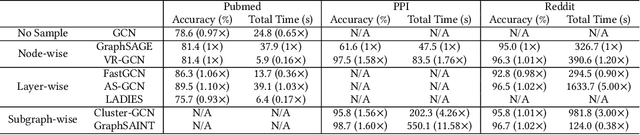
Graph neural networks (GNNs) are emerging for machine learning research on graph-structured data. GNNs achieve state-of-the-art performance on many tasks, but they face scalability challenges when it comes to real-world applications that have numerous data and strict latency requirements. Many studies have been conducted on how to accelerate GNNs in an effort to address these challenges. These acceleration techniques touch on various aspects of the GNN pipeline, from smart training and inference algorithms to efficient systems and customized hardware. As the amount of research on GNN acceleration has grown rapidly, there lacks a systematic treatment to provide a unified view and address the complexity of relevant works. In this survey, we provide a taxonomy of GNN acceleration, review the existing approaches, and suggest future research directions. Our taxonomic treatment of GNN acceleration connects the existing works and sets the stage for further development in this area.