 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingdong Gao
TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems
Oct 10, 2023
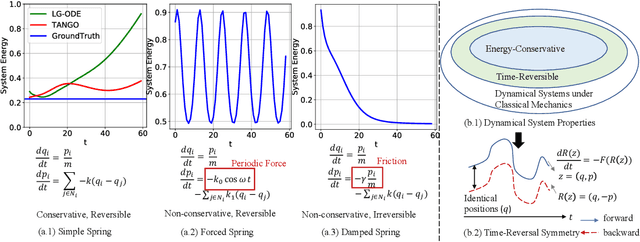
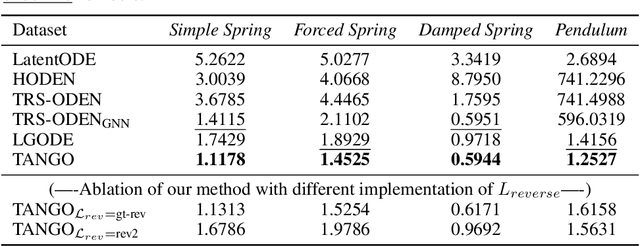
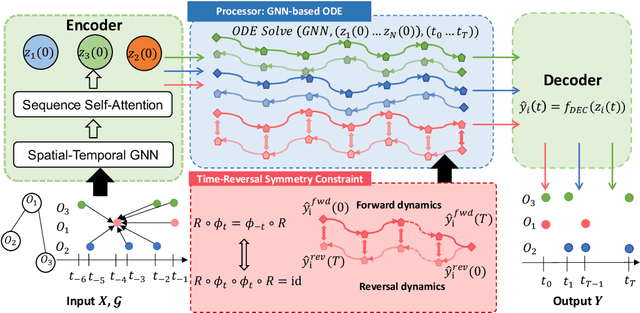
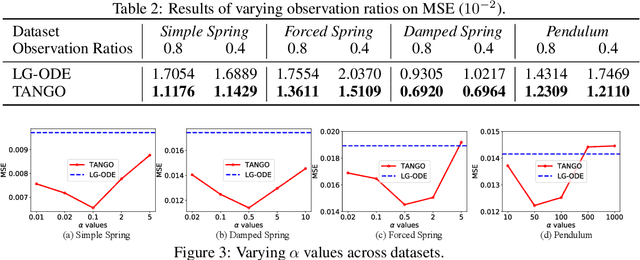
Learning complex multi-agent system dynamics from data is crucial across many domains, such as in physical simulations and material modeling. Extended from purely data-driven approaches, existing physics-informed approaches such as Hamiltonian Neural Network strictly follow energy conservation law to introduce inductive bias, making their learning more sample efficiently. However, many real-world systems do not strictly conserve energy, such as spring systems with frictions. Recognizing this, we turn our attention to a broader physical principle: Time-Reversal Symmetry, which depicts that the dynamics of a system shall remain invariant when traversed back over time. It still helps to preserve energies for conservative systems and in the meanwhile, serves as a strong inductive bias for non-conservative, reversible systems. To inject such inductive bias, in this paper, we propose a simple-yet-effective self-supervised regularization term as a soft constraint that aligns the forward and backward trajectories predicted by a continuous graph neural network-based ordinary differential equation (GraphODE). It effectively imposes time-reversal symmetry to enable more accurate model predictions across a wider range of dynamical systems under classical mechanics. In addition, we further provide theoretical analysis to show that our regularization essentially minimizes higher-order Taylor expansion terms during the ODE integration steps, which enables our model to be more noise-tolerant and even applicable to irreversible systems. Experimental results on a variety of physical systems demonstrate the effectiveness of our proposed method. Particularly, it achieves an MSE improvement of 11.5 % on a challenging chaotic triple-pendulum systems.
Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks
Oct 05, 2023Contrastive Language-Image Pre-training (CLIP) on large image-caption datasets has achieved remarkable success in zero-shot classification and enabled transferability to new domains. However, CLIP is extremely more vulnerable to targeted data poisoning and backdoor attacks, compared to supervised learning. Perhaps surprisingly, poisoning 0.0001% of CLIP pre-training data is enough to make targeted data poisoning attacks successful. This is four orders of magnitude smaller than what is required to poison supervised models. Despite this vulnerability, existing methods are very limited in defending CLIP models during pre-training. In this work, we propose a strong defense, SAFECLIP, to safely pre-train CLIP against targeted data poisoning and backdoor attacks. SAFECLIP warms up the model by applying unimodal contrastive learning (CL) on image and text modalities separately. Then, it carefully divides the data into safe and risky subsets. SAFECLIP trains on the risky data by applying unimodal CL to image and text modalities separately, and trains on the safe data using the CLIP loss. By gradually increasing the size of the safe subset during the training, SAFECLIP effectively breaks targeted data poisoning and backdoor attacks without harming the CLIP performance. Our extensive experiments show that SAFECLIP decrease the attack success rate of targeted data poisoning attacks from 93.75% to 0% and that of the backdoor attacks from 100% to 0%, without harming the CLIP performance on various datasets.
High Probability Bounds for Stochastic Continuous Submodular Maximization
Mar 20, 2023



We consider maximization of stochastic monotone continuous submodular functions (CSF) with a diminishing return property. Existing algorithms only guarantee the performance \textit{in expectation}, and do not bound the probability of getting a bad solution. This implies that for a particular run of the algorithms, the solution may be much worse than the provided guarantee in expectation. In this paper, we first empirically verify that this is indeed the case. Then, we provide the first \textit{high-probability} analysis of the existing methods for stochastic CSF maximization, namely PGA, boosted PGA, SCG, and SCG++. Finally, we provide an improved high-probability bound for SCG, under slightly stronger assumptions, with a better convergence rate than that of the expected solution. Through extensive experiments on non-concave quadratic programming (NQP) and optimal budget allocation, we confirm the validity of our bounds and show that even in the worst-case, PGA converges to $OPT/2$, and boosted PGA, SCG, SCG++ converge to $(1 - 1/e)OPT$, but at a slower rate than that of the expected solution.
Iterative Teacher-Aware Learning
Oct 17, 2021



In human pedagogy, teachers and students can interact adaptively to maximize communication efficiency. The teacher adjusts her teaching method for different students, and the student, after getting familiar with the teacher's instruction mechanism, can infer the teacher's intention to learn faster. Recently, the benefits of integrating this cooperative pedagogy into machine concept learning in discrete spaces have been proved by multiple works. However, how cooperative pedagogy can facilitate machine parameter learning hasn't been thoroughly studied. In this paper, we propose a gradient optimization based teacher-aware learner who can incorporate teacher's cooperative intention into the likelihood function and learn provably faster compared with the naive learning algorithms used in previous machine teaching works. We give theoretical proof that the iterative teacher-aware learning (ITAL) process leads to local and global improvements. We then validate our algorithms with extensive experiments on various tasks including regression, classification, and inverse reinforcement learning using synthetic and real data. We also show the advantage of modeling teacher-awareness when agents are learning from human teachers.