 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanchen Zhang
AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
Apr 04, 2024
Large language models (LLMs) have fueled many intelligent agent tasks, such as web navigation -- but most existing agents perform far from satisfying in real-world webpages due to three factors: (1) the versatility of actions on webpages, (2) HTML text exceeding model processing capacity, and (3) the complexity of decision-making due to the open-domain nature of web. In light of the challenge, we develop AutoWebGLM, a GPT-4-outperforming automated web navigation agent built upon ChatGLM3-6B. Inspired by human browsing patterns, we design an HTML simplification algorithm to represent webpages, preserving vital information succinctly. We employ a hybrid human-AI method to build web browsing data for curriculum training. Then, we bootstrap the model by reinforcement learning and rejection sampling to further facilitate webpage comprehension, browser operations, and efficient task decomposition by itself. For testing, we establish a bilingual benchmark -- AutoWebBench -- for real-world web browsing tasks. We evaluate AutoWebGLM across diverse web navigation benchmarks, revealing its improvements but also underlying challenges to tackle real environments. Related code, model, and data will be released at \url{https://github.com/THUDM/AutoWebGLM}.
AgentBench: Evaluating LLMs as Agents
Aug 07, 2023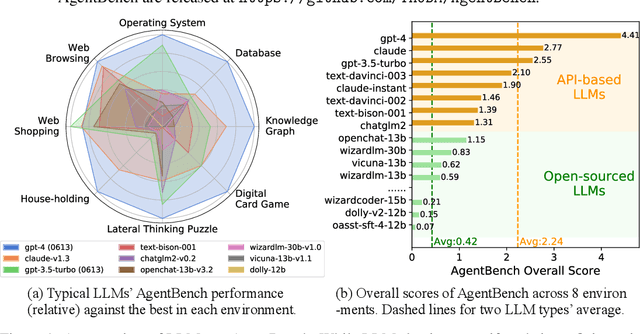
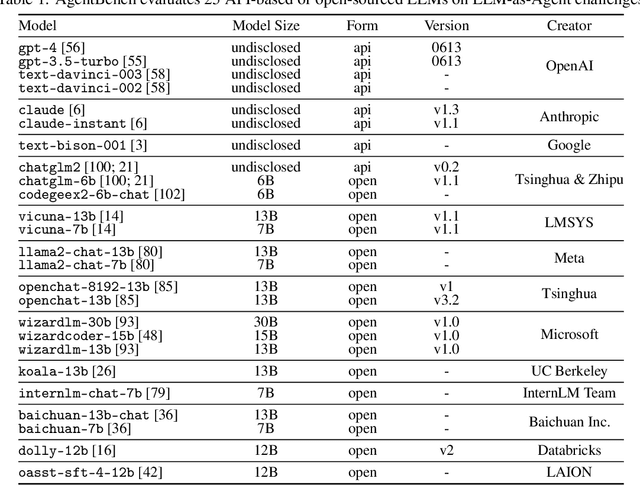
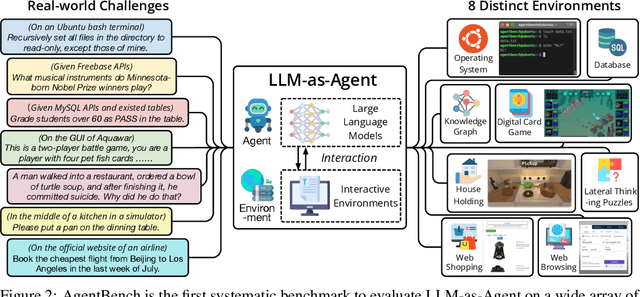
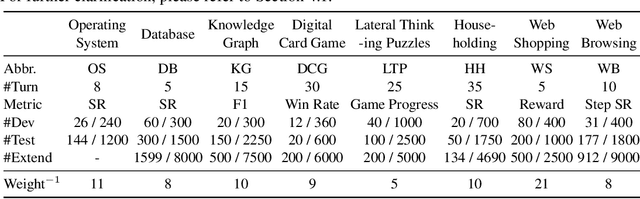
Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation. Datasets, environments, and an integrated evaluation package for AgentBench are released at https://github.com/THUDM/AgentBench