 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRongkun Zheng
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024
We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
TMT-VIS: Taxonomy-aware Multi-dataset Joint Training for Video Instance Segmentation
Dec 12, 2023
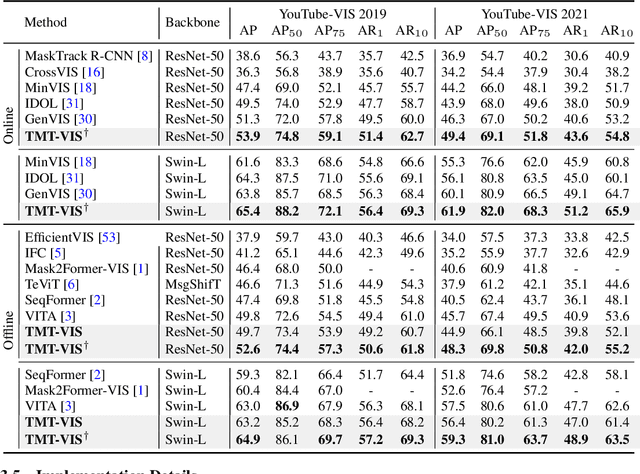
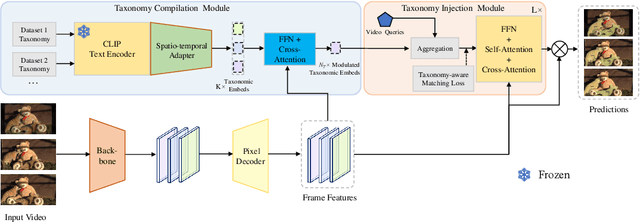
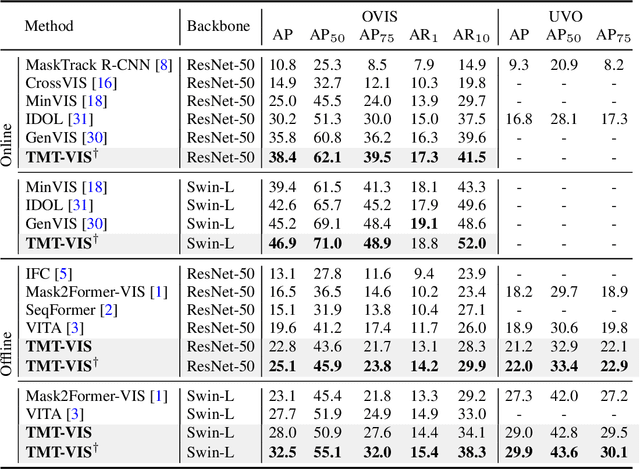
Training on large-scale datasets can boost the performance of video instance segmentation while the annotated datasets for VIS are hard to scale up due to the high labor cost. What we possess are numerous isolated filed-specific datasets, thus, it is appealing to jointly train models across the aggregation of datasets to enhance data volume and diversity. However, due to the heterogeneity in category space, as mask precision increases with the data volume, simply utilizing multiple datasets will dilute the attention of models on different taxonomies. Thus, increasing the data scale and enriching taxonomy space while improving classification precision is important. In this work, we analyze that providing extra taxonomy information can help models concentrate on specific taxonomy, and propose our model named Taxonomy-aware Multi-dataset Joint Training for Video Instance Segmentation (TMT-VIS) to address this vital challenge. Specifically, we design a two-stage taxonomy aggregation module that first compiles taxonomy information from input videos and then aggregates these taxonomy priors into instance queries before the transformer decoder. We conduct extensive experimental evaluations on four popular and challenging benchmarks, including YouTube-VIS 2019, YouTube-VIS 2021, OVIS, and UVO. Our model shows significant improvement over the baseline solutions, and sets new state-of-the-art records on all benchmarks. These appealing and encouraging results demonstrate the effectiveness and generality of our approach. The code is available at https://github.com/rkzheng99/TMT-VIS(https://github.com/rkzheng99/TMT-VIS)