 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDamien Teney
Neural Redshift: Random Networks are not Random Functions
Mar 05, 2024
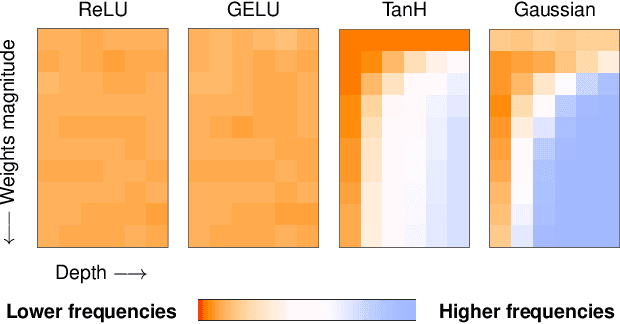

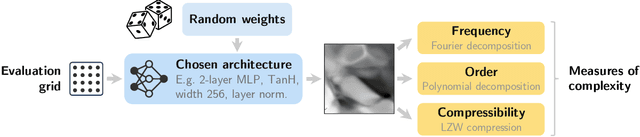

Our understanding of the generalization capabilities of neural networks (NNs) is still incomplete. Prevailing explanations are based on implicit biases of gradient descent (GD) but they cannot account for the capabilities of models from gradient-free methods nor the simplicity bias recently observed in untrained networks. This paper seeks other sources of generalization in NNs. Findings. To understand the inductive biases provided by architectures independently from GD, we examine untrained, random-weight networks. Even simple MLPs show strong inductive biases: uniform sampling in weight space yields a very biased distribution of functions in terms of complexity. But unlike common wisdom, NNs do not have an inherent "simplicity bias". This property depends on components such as ReLUs, residual connections, and layer normalizations. Alternative architectures can be built with a bias for any level of complexity. Transformers also inherit all these properties from their building blocks. Implications. We provide a fresh explanation for the success of deep learning independent from gradient-based training. It points at promising avenues for controlling the solutions implemented by trained models.
Zero-shot Retrieval: Augmenting Pre-trained Models with Search Engines
Nov 29, 2023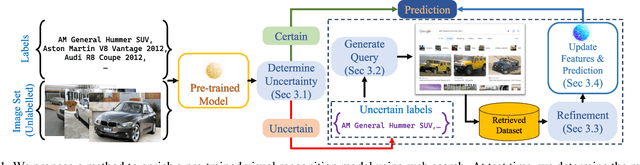
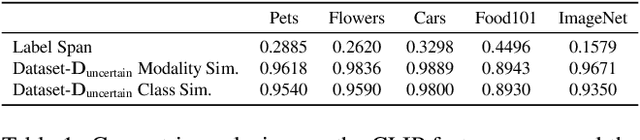
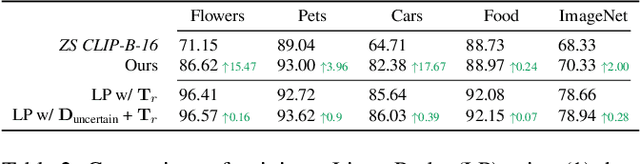
Large pre-trained models can dramatically reduce the amount of task-specific data required to solve a problem, but they often fail to capture domain-specific nuances out of the box. The Web likely contains the information necessary to excel on any specific application, but identifying the right data a priori is challenging. This paper shows how to leverage recent advances in NLP and multi-modal learning to augment a pre-trained model with search engine retrieval. We propose to retrieve useful data from the Web at test time based on test cases that the model is uncertain about. Different from existing retrieval-augmented approaches, we then update the model to address this underlying uncertainty. We demonstrate substantial improvements in zero-shot performance, e.g. a remarkable increase of 15 percentage points in accuracy on the Stanford Cars and Flowers datasets. We also present extensive experiments that explore the impact of noisy retrieval and different learning strategies.
Shortcut Bias Mitigation via Ensemble Diversity Using Diffusion Probabilistic Models
Nov 23, 2023Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to a phenomenon known as simplicity bias, where a model relies on erroneous, easy-to-learn cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting Diffusion Probabilistic Models (DPMs) for shortcut bias mitigation. We show that at particular training intervals, DPMs can generate images with novel feature combinations, even when trained on images displaying correlated input features. We leverage this crucial property to generate synthetic counterfactuals to increase model diversity via ensemble disagreement. We show that DPM-guided diversification is sufficient to remove dependence on primary shortcut cues, without a need for additional supervised signals. We further empirically quantify its efficacy on several diversification objectives, and finally show improved generalization and diversification performance on par with prior work that relies on auxiliary data collection.
ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning
Oct 08, 2023
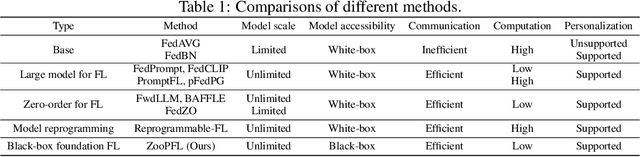
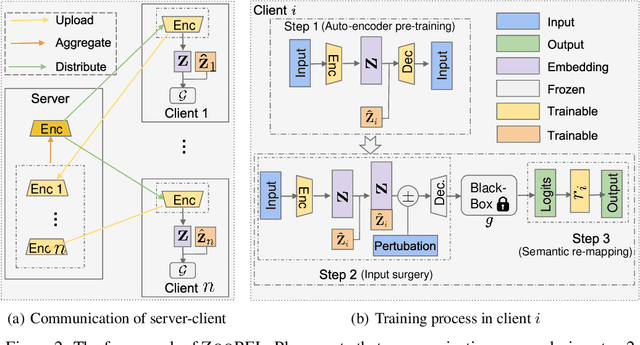
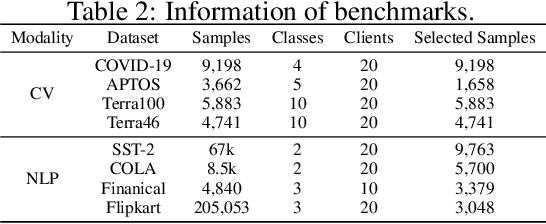
When personalized federated learning (FL) meets large foundation models, new challenges arise from various limitations in resources. In addition to typical limitations such as data, computation, and communication costs, access to the models is also often limited. This paper endeavors to solve both the challenges of limited resources and personalization. i.e., distribution shifts between clients. To do so, we propose a method named ZOOPFL that uses Zeroth-Order Optimization for Personalized Federated Learning. ZOOPFL avoids direct interference with the foundation models and instead learns to adapt its inputs through zeroth-order optimization. In addition, we employ simple yet effective linear projections to remap its predictions for personalization. To reduce the computation costs and enhance personalization, we propose input surgery to incorporate an auto-encoder with low-dimensional and client-specific embeddings. We provide theoretical support for ZOOPFL to analyze its convergence. Extensive empirical experiments on computer vision and natural language processing tasks using popular foundation models demonstrate its effectiveness for FL on black-box foundation models.
Leveraging Diffusion Disentangled Representations to Mitigate Shortcuts in Underspecified Visual Tasks
Oct 03, 2023Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to shortcut learning phenomena, where a model may rely on erroneous, easy-to-learn, cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting the generation of synthetic counterfactuals using Diffusion Probabilistic Models (DPMs). We discover that DPMs have the inherent capability to represent multiple visual cues independently, even when they are largely correlated in the training data. We leverage this characteristic to encourage model diversity and empirically show the efficacy of the approach with respect to several diversification objectives. We show that diffusion-guided diversification can lead models to avert attention from shortcut cues, achieving ensemble diversity performance comparable to previous methods requiring additional data collection.
Learning Diverse Features in Vision Transformers for Improved Generalization
Aug 30, 2023Deep learning models often rely only on a small set of features even when there is a rich set of predictive signals in the training data. This makes models brittle and sensitive to distribution shifts. In this work, we first examine vision transformers (ViTs) and find that they tend to extract robust and spurious features with distinct attention heads. As a result of this modularity, their performance under distribution shifts can be significantly improved at test time by pruning heads corresponding to spurious features, which we demonstrate using an "oracle selection" on validation data. Second, we propose a method to further enhance the diversity and complementarity of the learned features by encouraging orthogonality of the attention heads' input gradients. We observe improved out-of-distribution performance on diagnostic benchmarks (MNIST-CIFAR, Waterbirds) as a consequence of the enhanced diversity of features and the pruning of undesirable heads.
Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder
Jun 05, 2023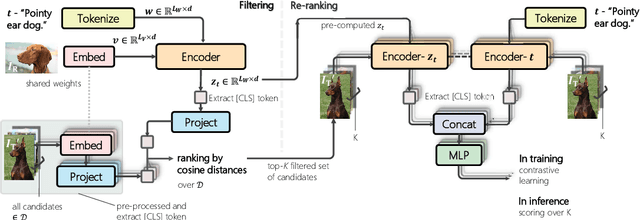
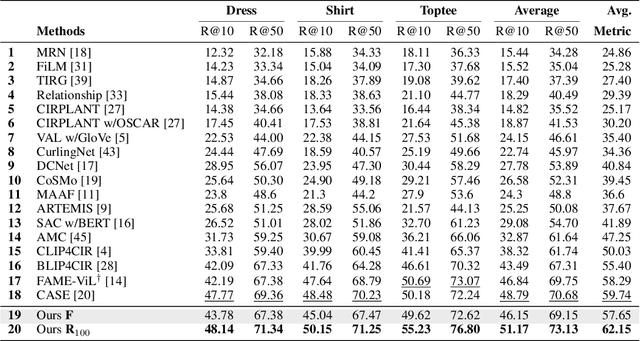
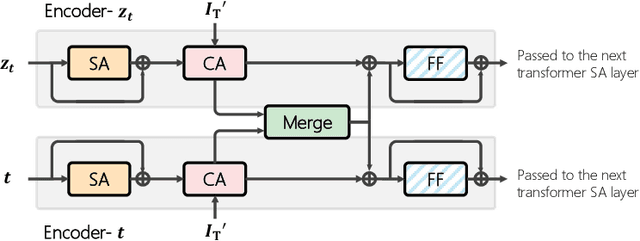
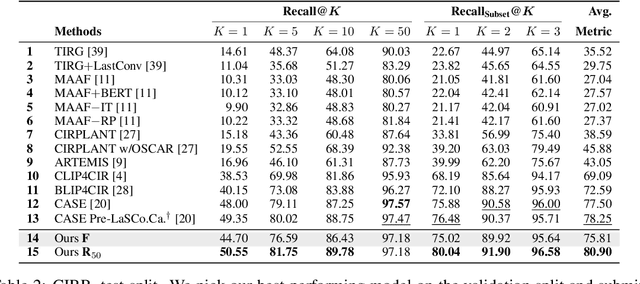
Composed image retrieval aims to find an image that best matches a given multi-modal user query consisting of a reference image and text pair. Existing methods commonly pre-compute image embeddings over the entire corpus and compare these to a reference image embedding modified by the query text at test time. Such a pipeline is very efficient at test time since fast vector distances can be used to evaluate candidates, but modifying the reference image embedding guided only by a short textual description can be difficult, especially independent of potential candidates. An alternative approach is to allow interactions between the query and every possible candidate, i.e., reference-text-candidate triplets, and pick the best from the entire set. Though this approach is more discriminative, for large-scale datasets the computational cost is prohibitive since pre-computation of candidate embeddings is no longer possible. We propose to combine the merits of both schemes using a two-stage model. Our first stage adopts the conventional vector distancing metric and performs a fast pruning among candidates. Meanwhile, our second stage employs a dual-encoder architecture, which effectively attends to the input triplet of reference-text-candidate and re-ranks the candidates. Both stages utilize a vision-and-language pre-trained network, which has proven beneficial for various downstream tasks. Our method consistently outperforms state-of-the-art approaches on standard benchmarks for the task.
Selective Mixup Helps with Distribution Shifts, But Not (Only) because of Mixup
Jun 02, 2023
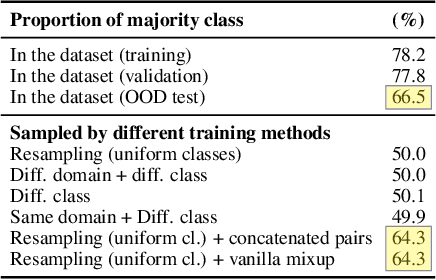
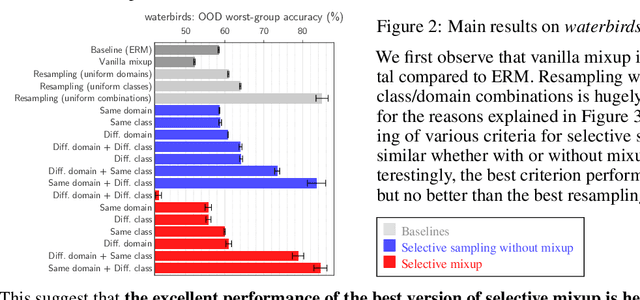

Mixup is a highly successful technique to improve generalization of neural networks by augmenting the training data with combinations of random pairs. Selective mixup is a family of methods that apply mixup to specific pairs, e.g. only combining examples across classes or domains. These methods have claimed remarkable improvements on benchmarks with distribution shifts, but their mechanisms and limitations remain poorly understood. We examine an overlooked aspect of selective mixup that explains its success in a completely new light. We find that the non-random selection of pairs affects the training distribution and improve generalization by means completely unrelated to the mixing. For example in binary classification, mixup across classes implicitly resamples the data for a uniform class distribution - a classical solution to label shift. We show empirically that this implicit resampling explains much of the improvements in prior work. Theoretically, these results rely on a regression toward the mean, an accidental property that we identify in several datasets. We have found a new equivalence between two successful methods: selective mixup and resampling. We identify limits of the former, confirm the effectiveness of the latter, and find better combinations of their respective benefits.
A Symbolic Framework for Systematic Evaluation of Mathematical Reasoning with Transformers
May 21, 2023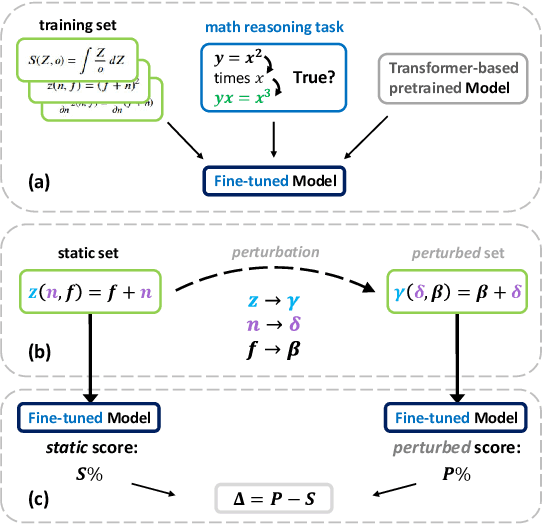
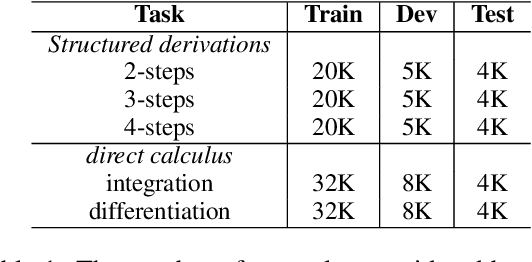

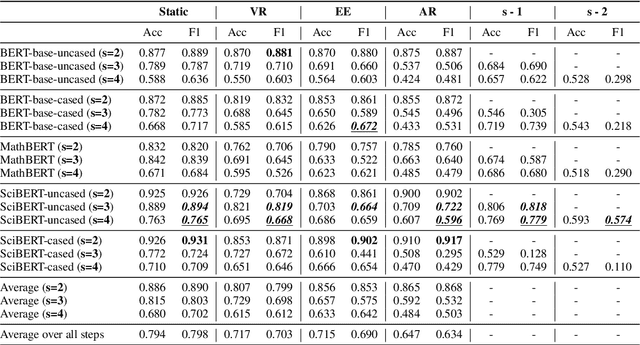
Whether Transformers can learn to apply symbolic rules and generalise to out-of-distribution examples is an open research question. In this paper, we devise a data generation method for producing intricate mathematical derivations, and systematically perturb them with respect to syntax, structure, and semantics. Our task-agnostic approach generates equations, annotations, and inter-equation dependencies, employing symbolic algebra for scalable data production and augmentation. We then instantiate a general experimental framework on next-equation prediction, assessing systematic mathematical reasoning and generalisation of Transformer encoders on a total of 200K examples. The experiments reveal that perturbations heavily affect performance and can reduce F1 scores of $97\%$ to below $17\%$, suggesting that inference is dominated by surface-level patterns unrelated to a deeper understanding of mathematical operators. These findings underscore the importance of rigorous, large-scale evaluation frameworks for revealing fundamental limitations of existing models.
Bi-directional Training for Composed Image Retrieval via Text Prompt Learning
Mar 29, 2023
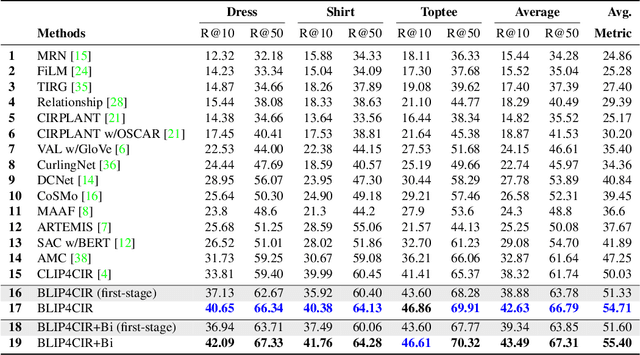

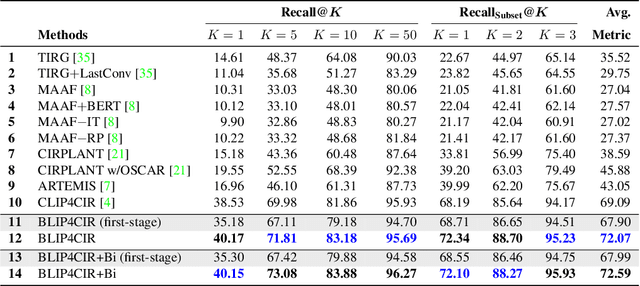
Composed image retrieval searches for a target image based on a multi-modal user query comprised of a reference image and modification text describing the desired changes. Existing approaches to solving this challenging task learn a mapping from the (reference image, modification text)-pair to an image embedding that is then matched against a large image corpus. One area that has not yet been explored is the reverse direction, which asks the question, what reference image when modified as describe by the text would produce the given target image? In this work we propose a bi-directional training scheme that leverages such reversed queries and can be applied to existing composed image retrieval architectures. To encode the bi-directional query we prepend a learnable token to the modification text that designates the direction of the query and then finetune the parameters of the text embedding module. We make no other changes to the network architecture. Experiments on two standard datasets show that our novel approach achieves improved performance over a baseline BLIP-based model that itself already achieves state-of-the-art performance.