 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaven Qinfeng Shi
Identifiable Latent Neural Causal Models
Mar 23, 2024
Causal representation learning seeks to uncover latent, high-level causal representations from low-level observed data. It is particularly good at predictions under unseen distribution shifts, because these shifts can generally be interpreted as consequences of interventions. Hence leveraging {seen} distribution shifts becomes a natural strategy to help identifying causal representations, which in turn benefits predictions where distributions are previously {unseen}. Determining the types (or conditions) of such distribution shifts that do contribute to the identifiability of causal representations is critical. This work establishes a {sufficient} and {necessary} condition characterizing the types of distribution shifts for identifiability in the context of latent additive noise models. Furthermore, we present partial identifiability results when only a portion of distribution shifts meets the condition. In addition, we extend our findings to latent post-nonlinear causal models. We translate our findings into a practical algorithm, allowing for the acquisition of reliable latent causal representations. Our algorithm, guided by our underlying theory, has demonstrated outstanding performance across a diverse range of synthetic and real-world datasets. The empirical observations align closely with the theoretical findings, affirming the robustness and effectiveness of our approach.
A Simple-but-effective Baseline for Training-free Class-Agnostic Counting
Mar 03, 2024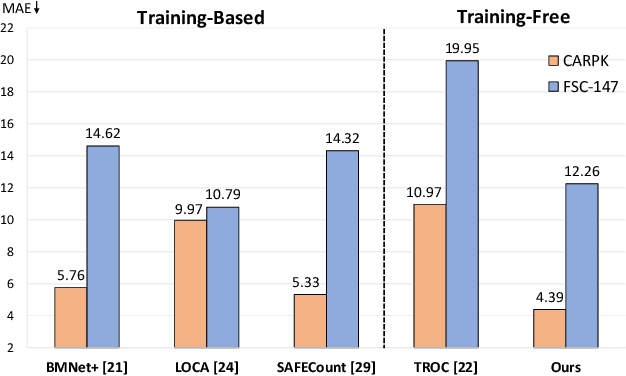
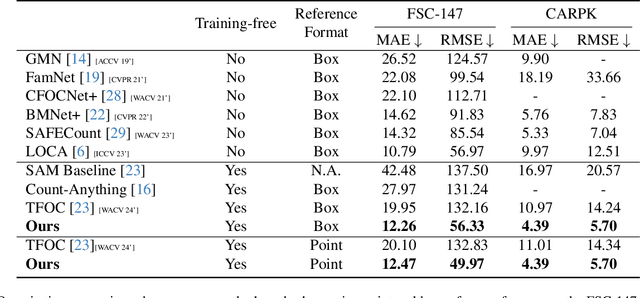
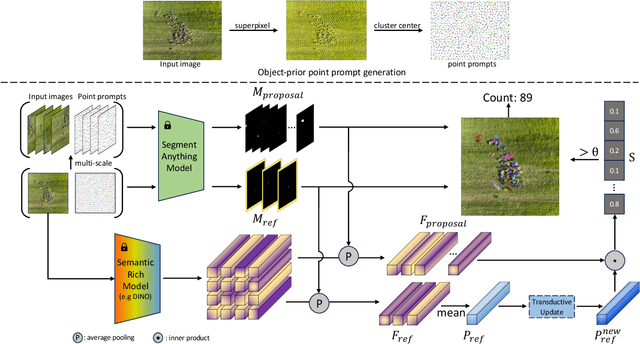
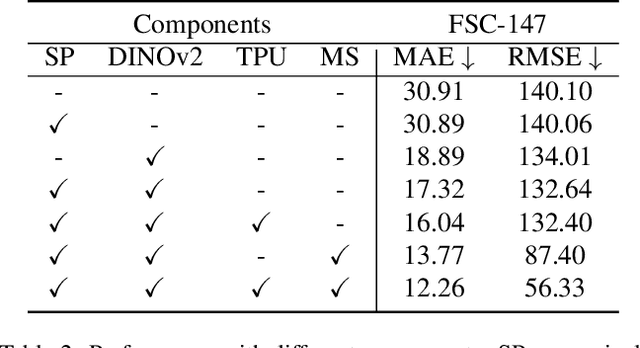
Class-Agnostic Counting (CAC) seeks to accurately count objects in a given image with only a few reference examples. While previous methods achieving this relied on additional training, recent efforts have shown that it's possible to accomplish this without training by utilizing pre-existing foundation models, particularly the Segment Anything Model (SAM), for counting via instance-level segmentation. Although promising, current training-free methods still lag behind their training-based counterparts in terms of performance. In this research, we present a straightforward training-free solution that effectively bridges this performance gap, serving as a strong baseline. The primary contribution of our work lies in the discovery of four key technologies that can enhance performance. Specifically, we suggest employing a superpixel algorithm to generate more precise initial point prompts, utilizing an image encoder with richer semantic knowledge to replace the SAM encoder for representing candidate objects, and adopting a multiscale mechanism and a transductive prototype scheme to update the representation of reference examples. By combining these four technologies, our approach achieves significant improvements over existing training-free methods and delivers performance on par with training-based ones.
Revealing Multimodal Contrastive Representation Learning through Latent Partial Causal Models
Feb 09, 2024Multimodal contrastive representation learning methods have proven successful across a range of domains, partly due to their ability to generate meaningful shared representations of complex phenomena. To enhance the depth of analysis and understanding of these acquired representations, we introduce a unified causal model specifically designed for multimodal data. By examining this model, we show that multimodal contrastive representation learning excels at identifying latent coupled variables within the proposed unified model, up to linear or permutation transformations resulting from different assumptions. Our findings illuminate the potential of pre-trained multimodal models, eg, CLIP, in learning disentangled representations through a surprisingly simple yet highly effective tool: linear independent component analysis. Experiments demonstrate the robustness of our findings, even when the assumptions are violated, and validate the effectiveness of the proposed method in learning disentangled representations.
Zero-shot Retrieval: Augmenting Pre-trained Models with Search Engines
Nov 29, 2023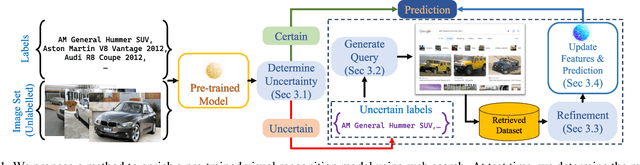
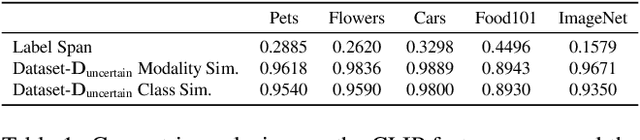
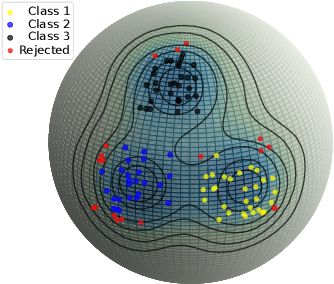
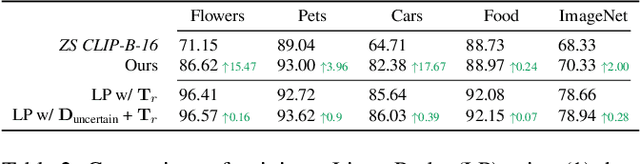
Large pre-trained models can dramatically reduce the amount of task-specific data required to solve a problem, but they often fail to capture domain-specific nuances out of the box. The Web likely contains the information necessary to excel on any specific application, but identifying the right data a priori is challenging. This paper shows how to leverage recent advances in NLP and multi-modal learning to augment a pre-trained model with search engine retrieval. We propose to retrieve useful data from the Web at test time based on test cases that the model is uncertain about. Different from existing retrieval-augmented approaches, we then update the model to address this underlying uncertainty. We demonstrate substantial improvements in zero-shot performance, e.g. a remarkable increase of 15 percentage points in accuracy on the Stanford Cars and Flowers datasets. We also present extensive experiments that explore the impact of noisy retrieval and different learning strategies.
CLAP: Contrastive Learning with Augmented Prompts for Robustness on Pretrained Vision-Language Models
Nov 28, 2023Contrastive vision-language models, e.g., CLIP, have garnered substantial attention for their exceptional generalization capabilities. However, their robustness to perturbations has ignited concerns. Existing strategies typically reinforce their resilience against adversarial examples by enabling the image encoder to "see" these perturbed examples, often necessitating a complete retraining of the image encoder on both natural and adversarial samples. In this study, we propose a new method to enhance robustness solely through text augmentation, eliminating the need for retraining the image encoder on adversarial examples. Our motivation arises from the realization that text and image data inherently occupy a shared latent space, comprising latent content variables and style variables. This insight suggests the feasibility of learning to disentangle these latent content variables using text data exclusively. To accomplish this, we introduce an effective text augmentation method that focuses on modifying the style while preserving the content in the text data. By changing the style part of the text data, we empower the text encoder to emphasize latent content variables, ultimately enhancing the robustness of vision-language models. Our experiments across various datasets demonstrate substantial improvements in the robustness of the pre-trained CLIP model.
Identifiable Latent Polynomial Causal Models Through the Lens of Change
Oct 24, 2023
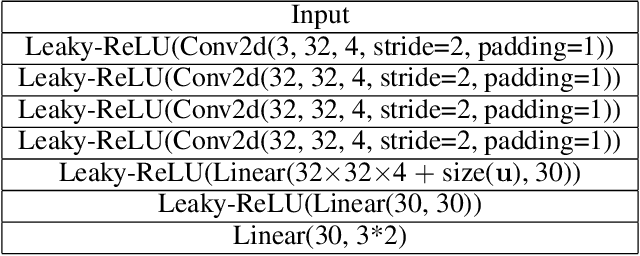
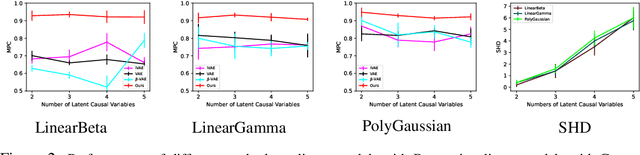
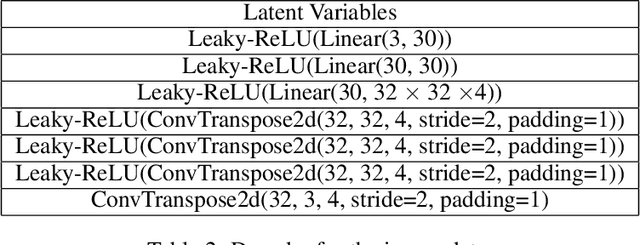
Causal representation learning aims to unveil latent high-level causal representations from observed low-level data. One of its primary tasks is to provide reliable assurance of identifying these latent causal models, known as identifiability. A recent breakthrough explores identifiability by leveraging the change of causal influences among latent causal variables across multiple environments \citep{liu2022identifying}. However, this progress rests on the assumption that the causal relationships among latent causal variables adhere strictly to linear Gaussian models. In this paper, we extend the scope of latent causal models to involve nonlinear causal relationships, represented by polynomial models, and general noise distributions conforming to the exponential family. Additionally, we investigate the necessity of imposing changes on all causal parameters and present partial identifiability results when part of them remains unchanged. Further, we propose a novel empirical estimation method, grounded in our theoretical finding, that enables learning consistent latent causal representations. Our experimental results, obtained from both synthetic and real-world data, validate our theoretical contributions concerning identifiability and consistency.
A Survey on Deep Neural Network Pruning-Taxonomy, Comparison, Analysis, and Recommendations
Aug 13, 2023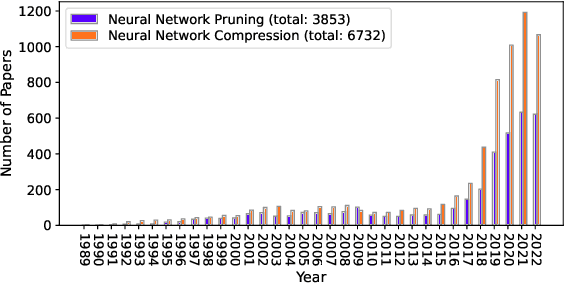

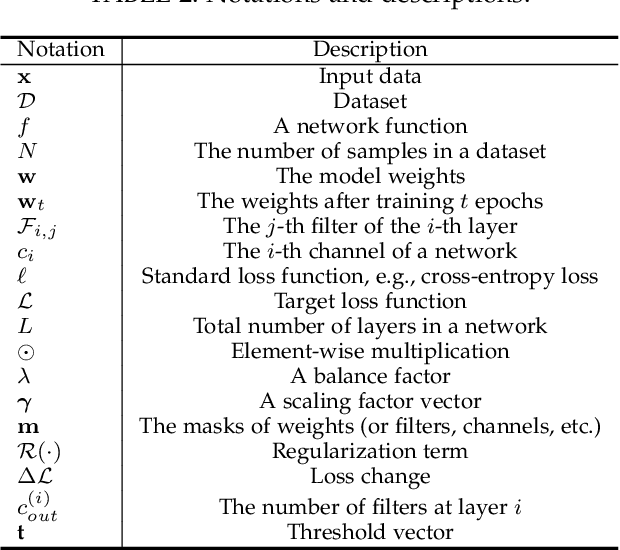
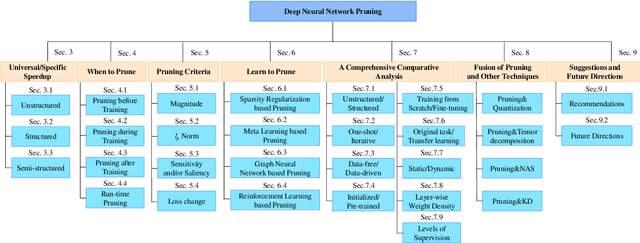
Modern deep neural networks, particularly recent large language models, come with massive model sizes that require significant computational and storage resources. To enable the deployment of modern models on resource-constrained environments and accelerate inference time, researchers have increasingly explored pruning techniques as a popular research direction in neural network compression. However, there is a dearth of up-to-date comprehensive review papers on pruning. To address this issue, in this survey, we provide a comprehensive review of existing research works on deep neural network pruning in a taxonomy of 1) universal/specific speedup, 2) when to prune, 3) how to prune, and 4) fusion of pruning and other compression techniques. We then provide a thorough comparative analysis of seven pairs of contrast settings for pruning (e.g., unstructured/structured) and explore emerging topics, including post-training pruning, different levels of supervision for pruning, and broader applications (e.g., adversarial robustness) to shed light on the commonalities and differences of existing methods and lay the foundation for further method development. To facilitate future research, we build a curated collection of datasets, networks, and evaluations on different applications. Finally, we provide some valuable recommendations on selecting pruning methods and prospect promising research directions. We build a repository at https://github.com/hrcheng1066/awesome-pruning.
Influence Function Based Second-Order Channel Pruning-Evaluating True Loss Changes For Pruning Is Possible Without Retraining
Aug 13, 2023A challenge of channel pruning is designing efficient and effective criteria to select channels to prune. A widely used criterion is minimal performance degeneration. To accurately evaluate the truth performance degeneration requires retraining the survived weights to convergence, which is prohibitively slow. Hence existing pruning methods use previous weights (without retraining) to evaluate the performance degeneration. However, we observe the loss changes differ significantly with and without retraining. It motivates us to develop a technique to evaluate true loss changes without retraining, with which channels to prune can be selected more reliably and confidently. We first derive a closed-form estimator of the true loss change per pruning mask change, using influence functions without retraining. Influence function which is from robust statistics reveals the impacts of a training sample on the model's prediction and is repurposed by us to assess impacts on true loss changes. We then show how to assess the importance of all channels simultaneously and develop a novel global channel pruning algorithm accordingly. We conduct extensive experiments to verify the effectiveness of the proposed algorithm. To the best of our knowledge, we are the first that shows evaluating true loss changes for pruning without retraining is possible. This finding will open up opportunities for a series of new paradigms to emerge that differ from existing pruning methods. The code is available at https://github.com/hrcheng1066/IFSO.
Factor Graph Neural Networks
Aug 02, 2023



In recent years, we have witnessed a surge of Graph Neural Networks (GNNs), most of which can learn powerful representations in an end-to-end fashion with great success in many real-world applications. They have resemblance to Probabilistic Graphical Models (PGMs), but break free from some limitations of PGMs. By aiming to provide expressive methods for representation learning instead of computing marginals or most likely configurations, GNNs provide flexibility in the choice of information flowing rules while maintaining good performance. Despite their success and inspirations, they lack efficient ways to represent and learn higher-order relations among variables/nodes. More expressive higher-order GNNs which operate on k-tuples of nodes need increased computational resources in order to process higher-order tensors. We propose Factor Graph Neural Networks (FGNNs) to effectively capture higher-order relations for inference and learning. To do so, we first derive an efficient approximate Sum-Product loopy belief propagation inference algorithm for discrete higher-order PGMs. We then neuralize the novel message passing scheme into a Factor Graph Neural Network (FGNN) module by allowing richer representations of the message update rules; this facilitates both efficient inference and powerful end-to-end learning. We further show that with a suitable choice of message aggregation operators, our FGNN is also able to represent Max-Product belief propagation, providing a single family of architecture that can represent both Max and Sum-Product loopy belief propagation. Our extensive experimental evaluation on synthetic as well as real datasets demonstrates the potential of the proposed model.
Semantic Role Labeling Guided Out-of-distribution Detection
May 29, 2023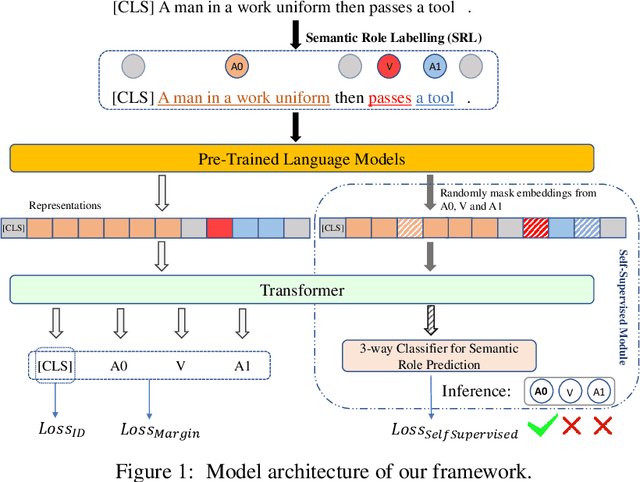
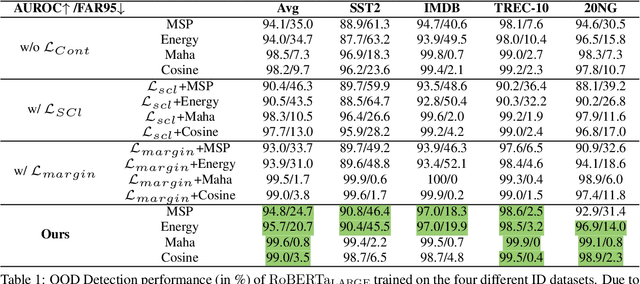
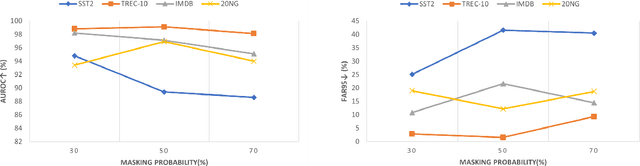
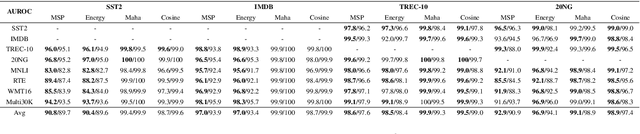
Identifying unexpected domain-shifted instances in natural language processing is crucial in real-world applications. Previous works identify the OOD instance by leveraging a single global feature embedding to represent the sentence, which cannot characterize subtle OOD patterns well. Another major challenge current OOD methods face is learning effective low-dimensional sentence representations to identify the hard OOD instances that are semantically similar to the ID data. In this paper, we propose a new unsupervised OOD detection method, namely Semantic Role Labeling Guided Out-of-distribution Detection (SRLOOD), that separates, extracts, and learns the semantic role labeling (SRL) guided fine-grained local feature representations from different arguments of a sentence and the global feature representations of the full sentence using a margin-based contrastive loss. A novel self-supervised approach is also introduced to enhance such global-local feature learning by predicting the SRL extracted role. The resulting model achieves SOTA performance on four OOD benchmarks, indicating the effectiveness of our approach. Codes will be available upon acceptance.