 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValentin Deschaintre
TexSliders: Diffusion-Based Texture Editing in CLIP Space
May 01, 2024
Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary.
RGB$\leftrightarrow$X: Image decomposition and synthesis using material- and lighting-aware diffusion models
May 01, 2024The three areas of realistic forward rendering, per-pixel inverse rendering, and generative image synthesis may seem like separate and unrelated sub-fields of graphics and vision. However, recent work has demonstrated improved estimation of per-pixel intrinsic channels (albedo, roughness, metallicity) based on a diffusion architecture; we call this the RGB$\rightarrow$X problem. We further show that the reverse problem of synthesizing realistic images given intrinsic channels, X$\rightarrow$RGB, can also be addressed in a diffusion framework. Focusing on the image domain of interior scenes, we introduce an improved diffusion model for RGB$\rightarrow$X, which also estimates lighting, as well as the first diffusion X$\rightarrow$RGB model capable of synthesizing realistic images from (full or partial) intrinsic channels. Our X$\rightarrow$RGB model explores a middle ground between traditional rendering and generative models: we can specify only certain appearance properties that should be followed, and give freedom to the model to hallucinate a plausible version of the rest. This flexibility makes it possible to use a mix of heterogeneous training datasets, which differ in the available channels. We use multiple existing datasets and extend them with our own synthetic and real data, resulting in a model capable of extracting scene properties better than previous work and of generating highly realistic images of interior scenes.
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Apr 18, 2024We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
MatAtlas: Text-driven Consistent Geometry Texturing and Material Assignment
Apr 03, 2024We present MatAtlas, a method for consistent text-guided 3D model texturing. Following recent progress we leverage a large scale text-to-image generation model (e.g., Stable Diffusion) as a prior to texture a 3D model. We carefully design an RGB texturing pipeline that leverages a grid pattern diffusion, driven by depth and edges. By proposing a multi-step texture refinement process, we significantly improve the quality and 3D consistency of the texturing output. To further address the problem of baked-in lighting, we move beyond RGB colors and pursue assigning parametric materials to the assets. Given the high-quality initial RGB texture, we propose a novel material retrieval method capitalized on Large Language Models (LLM), enabling editabiliy and relightability. We evaluate our method on a wide variety of geometries and show that our method significantly outperform prior arts. We also analyze the role of each component through a detailed ablation study.
MatSynth: A Modern PBR Materials Dataset
Jan 11, 2024We introduce MatSynth, a dataset of $4,000+$ CC0 ultra-high resolution PBR materials. Materials are crucial components of virtual relightable assets, defining the interaction of light at the surface of geometries. Given their importance, significant research effort was dedicated to their representation, creation and acquisition. However, in the past 6 years, most research in material acquisiton or generation relied either on the same unique dataset, or on company-owned huge library of procedural materials. With this dataset we propose a significantly larger, more diverse, and higher resolution set of materials than previously publicly available. We carefully discuss the data collection process and demonstrate the benefits of this dataset on material acquisition and generation applications. The complete data further contains metadata with each material's origin, license, category, tags, creation method and, when available, descriptions and physical size, as well as 3M+ renderings of the augmented materials, in 1K, under various environment lightings. The MatSynth dataset is released through the project page at: https://www.gvecchio.com/matsynth.
ControlMat: A Controlled Generative Approach to Material Capture
Sep 04, 2023Material reconstruction from a photograph is a key component of 3D content creation democratization. We propose to formulate this ill-posed problem as a controlled synthesis one, leveraging the recent progress in generative deep networks. We present ControlMat, a method which, given a single photograph with uncontrolled illumination as input, conditions a diffusion model to generate plausible, tileable, high-resolution physically-based digital materials. We carefully analyze the behavior of diffusion models for multi-channel outputs, adapt the sampling process to fuse multi-scale information and introduce rolled diffusion to enable both tileability and patched diffusion for high-resolution outputs. Our generative approach further permits exploration of a variety of materials which could correspond to the input image, mitigating the unknown lighting conditions. We show that our approach outperforms recent inference and latent-space-optimization methods, and carefully validate our diffusion process design choices. Supplemental materials and additional details are available at: https://gvecchio.com/controlmat/.
The Visual Language of Fabrics
Jul 25, 2023



We introduce text2fabric, a novel dataset that links free-text descriptions to various fabric materials. The dataset comprises 15,000 natural language descriptions associated to 3,000 corresponding images of fabric materials. Traditionally, material descriptions come in the form of tags/keywords, which limits their expressivity, induces pre-existing knowledge of the appropriate vocabulary, and ultimately leads to a chopped description system. Therefore, we study the use of free-text as a more appropriate way to describe material appearance, taking the use case of fabrics as a common item that non-experts may often deal with. Based on the analysis of the dataset, we identify a compact lexicon, set of attributes and key structure that emerge from the descriptions. This allows us to accurately understand how people describe fabrics and draw directions for generalization to other types of materials. We also show that our dataset enables specializing large vision-language models such as CLIP, creating a meaningful latent space for fabric appearance, and significantly improving applications such as fine-grained material retrieval and automatic captioning.
PSDR-Room: Single Photo to Scene using Differentiable Rendering
Jul 06, 2023
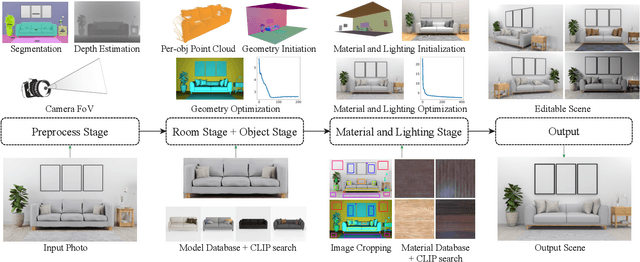
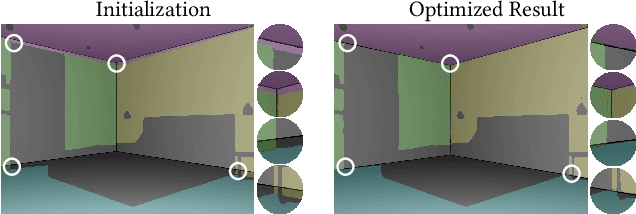
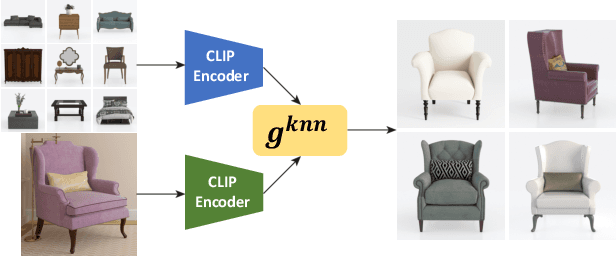
A 3D digital scene contains many components: lights, materials and geometries, interacting to reach the desired appearance. Staging such a scene is time-consuming and requires both artistic and technical skills. In this work, we propose PSDR-Room, a system allowing to optimize lighting as well as the pose and materials of individual objects to match a target image of a room scene, with minimal user input. To this end, we leverage a recent path-space differentiable rendering approach that provides unbiased gradients of the rendering with respect to geometry, lighting, and procedural materials, allowing us to optimize all of these components using gradient descent to visually match the input photo appearance. We use recent single-image scene understanding methods to initialize the optimization and search for appropriate 3D models and materials. We evaluate our method on real photographs of indoor scenes and demonstrate the editability of the resulting scene components.
PhotoMat: A Material Generator Learned from Single Flash Photos
May 23, 2023
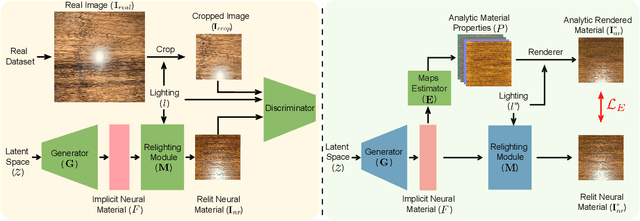


Authoring high-quality digital materials is key to realism in 3D rendering. Previous generative models for materials have been trained exclusively on synthetic data; such data is limited in availability and has a visual gap to real materials. We circumvent this limitation by proposing PhotoMat: the first material generator trained exclusively on real photos of material samples captured using a cell phone camera with flash. Supervision on individual material maps is not available in this setting. Instead, we train a generator for a neural material representation that is rendered with a learned relighting module to create arbitrarily lit RGB images; these are compared against real photos using a discriminator. We then train a material maps estimator to decode material reflectance properties from the neural material representation. We train PhotoMat with a new dataset of 12,000 material photos captured with handheld phone cameras under flash lighting. We demonstrate that our generated materials have better visual quality than previous material generators trained on synthetic data. Moreover, we can fit analytical material models to closely match these generated neural materials, thus allowing for further editing and use in 3D rendering.
Materialistic: Selecting Similar Materials in Images
May 22, 2023
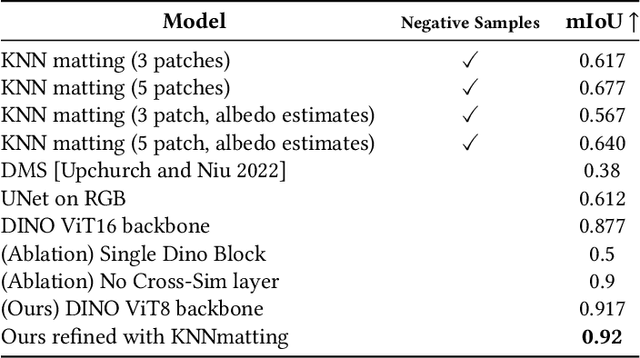
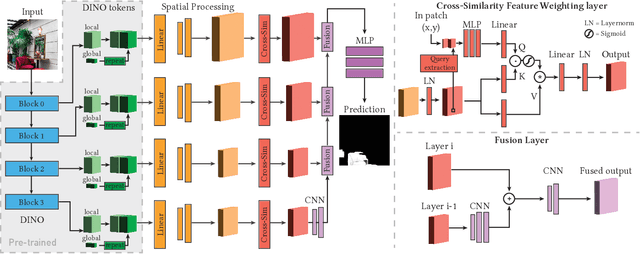

Separating an image into meaningful underlying components is a crucial first step for both editing and understanding images. We present a method capable of selecting the regions of a photograph exhibiting the same material as an artist-chosen area. Our proposed approach is robust to shading, specular highlights, and cast shadows, enabling selection in real images. As we do not rely on semantic segmentation (different woods or metal should not be selected together), we formulate the problem as a similarity-based grouping problem based on a user-provided image location. In particular, we propose to leverage the unsupervised DINO features coupled with a proposed Cross-Similarity module and an MLP head to extract material similarities in an image. We train our model on a new synthetic image dataset, that we release. We show that our method generalizes well to real-world images. We carefully analyze our model's behavior on varying material properties and lighting. Additionally, we evaluate it against a hand-annotated benchmark of 50 real photographs. We further demonstrate our model on a set of applications, including material editing, in-video selection, and retrieval of object photographs with similar materials.