 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShahRukh Athar
Rig3DGS: Creating Controllable Portraits from Casual Monocular Videos
Feb 06, 2024
Creating controllable 3D human portraits from casual smartphone videos is highly desirable due to their immense value in AR/VR applications. The recent development of 3D Gaussian Splatting (3DGS) has shown improvements in rendering quality and training efficiency. However, it still remains a challenge to accurately model and disentangle head movements and facial expressions from a single-view capture to achieve high-quality renderings. In this paper, we introduce Rig3DGS to address this challenge. We represent the entire scene, including the dynamic subject, using a set of 3D Gaussians in a canonical space. Using a set of control signals, such as head pose and expressions, we transform them to the 3D space with learned deformations to generate the desired rendering. Our key innovation is a carefully designed deformation method which is guided by a learnable prior derived from a 3D morphable model. This approach is highly efficient in training and effective in controlling facial expressions, head positions, and view synthesis across various captures. We demonstrate the effectiveness of our learned deformation through extensive quantitative and qualitative experiments. The project page can be found at http://shahrukhathar.github.io/2024/02/05/Rig3DGS.html
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
Controllable Dynamic Appearance for Neural 3D Portraits
Sep 21, 2023
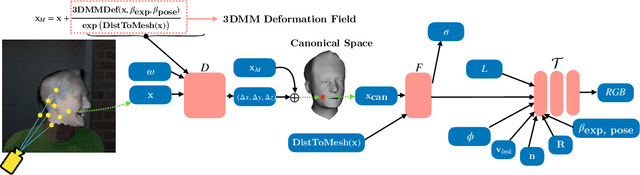
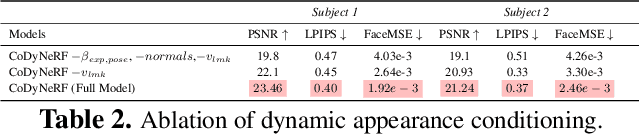
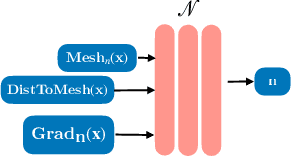
Recent advances in Neural Radiance Fields (NeRFs) have made it possible to reconstruct and reanimate dynamic portrait scenes with control over head-pose, facial expressions and viewing direction. However, training such models assumes photometric consistency over the deformed region e.g. the face must be evenly lit as it deforms with changing head-pose and facial expression. Such photometric consistency across frames of a video is hard to maintain, even in studio environments, thus making the created reanimatable neural portraits prone to artifacts during reanimation. In this work, we propose CoDyNeRF, a system that enables the creation of fully controllable 3D portraits in real-world capture conditions. CoDyNeRF learns to approximate illumination dependent effects via a dynamic appearance model in the canonical space that is conditioned on predicted surface normals and the facial expressions and head-pose deformations. The surface normals prediction is guided using 3DMM normals that act as a coarse prior for the normals of the human head, where direct prediction of normals is hard due to rigid and non-rigid deformations induced by head-pose and facial expression changes. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls, and realistic lighting effects. The project page can be found here: http://shahrukhathar.github.io/2023/08/22/CoDyNeRF.html
RigNeRF: Fully Controllable Neural 3D Portraits
Jun 13, 2022



Volumetric neural rendering methods, such as neural radiance fields (NeRFs), have enabled photo-realistic novel view synthesis. However, in their standard form, NeRFs do not support the editing of objects, such as a human head, within a scene. In this work, we propose RigNeRF, a system that goes beyond just novel view synthesis and enables full control of head pose and facial expressions learned from a single portrait video. We model changes in head pose and facial expressions using a deformation field that is guided by a 3D morphable face model (3DMM). The 3DMM effectively acts as a prior for RigNeRF that learns to predict only residuals to the 3DMM deformations and allows us to render novel (rigid) poses and (non-rigid) expressions that were not present in the input sequence. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls. The project page can be found here: http://shahrukhathar.github.io/2022/06/06/RigNeRF.html
SIDER: Single-Image Neural Optimization for Facial Geometric Detail Recovery
Aug 11, 2021



We present SIDER(Single-Image neural optimization for facial geometric DEtail Recovery), a novel photometric optimization method that recovers detailed facial geometry from a single image in an unsupervised manner. Inspired by classical techniques of coarse-to-fine optimization and recent advances in implicit neural representations of 3D shape, SIDER combines a geometry prior based on statistical models and Signed Distance Functions (SDFs) to recover facial details from single images. First, it estimates a coarse geometry using a morphable model represented as an SDF. Next, it reconstructs facial geometry details by optimizing a photometric loss with respect to the ground truth image. In contrast to prior work, SIDER does not rely on any dataset priors and does not require additional supervision from multiple views, lighting changes or ground truth 3D shape. Extensive qualitative and quantitative evaluation demonstrates that our method achieves state-of-the-art on facial geometric detail recovery, using only a single in-the-wild image.
FLAME-in-NeRF : Neural control of Radiance Fields for Free View Face Animation
Aug 10, 2021



This paper presents a neural rendering method for controllable portrait video synthesis. Recent advances in volumetric neural rendering, such as neural radiance fields (NeRF), has enabled the photorealistic novel view synthesis of static scenes with impressive results. However, modeling dynamic and controllable objects as part of a scene with such scene representations is still challenging. In this work, we design a system that enables both novel view synthesis for portrait video, including the human subject and the scene background, and explicit control of the facial expressions through a low-dimensional expression representation. We leverage the expression space of a 3D morphable face model (3DMM) to represent the distribution of human facial expressions, and use it to condition the NeRF volumetric function. Furthermore, we impose a spatial prior brought by 3DMM fitting to guide the network to learn disentangled control for scene appearance and facial actions. We demonstrate the effectiveness of our method on free view synthesis of portrait videos with expression controls. To train a scene, our method only requires a short video of a subject captured by a mobile device.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 23, 2020



Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
Variational Transfer Learning for Fine-grained Few-shot Visual Recognition
Oct 12, 2020



Fine-grained few-shot recognition often suffers from the problem of training data scarcity for novel categories.The network tends to overfit and does not generalize well to unseen classes due to insufficient training data. Many methods have been proposed to synthesize additional data to support the training. In this paper, we focus one enlarging the intra-class variance of the unseen class to improve few-shot classification performance. We assume that the distribution of intra-class variance generalizes across the base class and the novel class. Thus, the intra-class variance of the base set can be transferred to the novel set for feature augmentation. Specifically, we first model the distribution of intra-class variance on the base set via variational inference. Then the learned distribution is transferred to the novel set to generate additional features, which are used together with the original ones to train a classifier. Experimental results show a significant boost over the state-of-the-art methods on the challenging fine-grained few-shot image classification benchmarks.
Self-supervised Deformation Modeling for Facial Expression Editing
Nov 05, 2019



Recent advances in deep generative models have demonstrated impressive results in photo-realistic facial image synthesis and editing. Facial expressions are inherently the result of muscle movement. However, existing neural network-based approaches usually only rely on texture generation to edit expressions and largely neglect the motion information. In this work, we propose a novel end-to-end network that disentangles the task of facial editing into two steps: a " "motion-editing" step and a "texture-editing" step. In the "motion-editing" step, we explicitly model facial movement through image deformation, warping the image into the desired expression. In the "texture-editing" step, we generate necessary textures, such as teeth and shading effects, for a photo-realistic result. Our physically-based task-disentanglement system design allows each step to learn a focused task, removing the need of generating texture to hallucinate motion. Our system is trained in a self-supervised manner, requiring no ground truth deformation annotation. Using Action Units [8] as the representation for facial expression, our method improves the state-of-the-art facial expression editing performance in both qualitative and quantitative evaluations.
Latent Convolutional Models
Nov 02, 2018



We present a new latent model of natural images that can be learned on large-scale datasets. The learning process provides a latent embedding for every image in the training dataset, as well as a deep convolutional network that maps the latent space to the image space. After training, the new model provides a strong and universal image prior for a variety of image restoration tasks such as large-hole inpainting, superresolution, and colorization. To model high-resolution natural images, our approach uses latent spaces of very high dimensionality (one to two orders of magnitude higher than previous latent image models). To tackle this high dimensionality, we use latent spaces with a special manifold structure (convolutional manifolds) parameterized by a ConvNet of a certain architecture. In the experiments, we compare the learned latent models with latent models learned by autoencoders, advanced variants of generative adversarial networks, and a strong baseline system using simpler parameterization of the latent space. Our model outperforms the competing approaches over a range of restoration tasks.