 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiyu Liu
Learning Planning Abstractions from Language
May 06, 2024
This paper presents a framework for learning state and action abstractions in sequential decision-making domains. Our framework, planning abstraction from language (PARL), utilizes language-annotated demonstrations to automatically discover a symbolic and abstract action space and induce a latent state abstraction based on it. PARL consists of three stages: 1) recovering object-level and action concepts, 2) learning state abstractions, abstract action feasibility, and transition models, and 3) applying low-level policies for abstract actions. During inference, given the task description, PARL first makes abstract action plans using the latent transition and feasibility functions, then refines the high-level plan using low-level policies. PARL generalizes across scenarios involving novel object instances and environments, unseen concept compositions, and tasks that require longer planning horizons than settings it is trained on.
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Apr 30, 20243D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
Foundation Models in Robotics: Applications, Challenges, and the Future
Dec 13, 2023
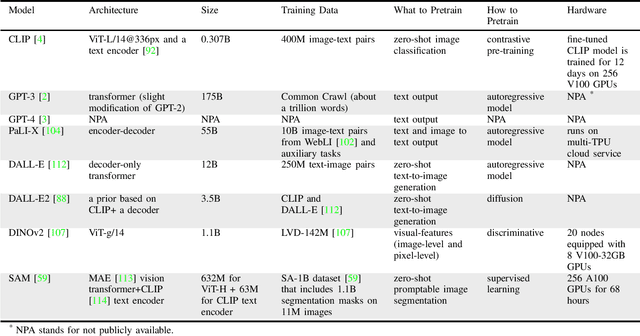
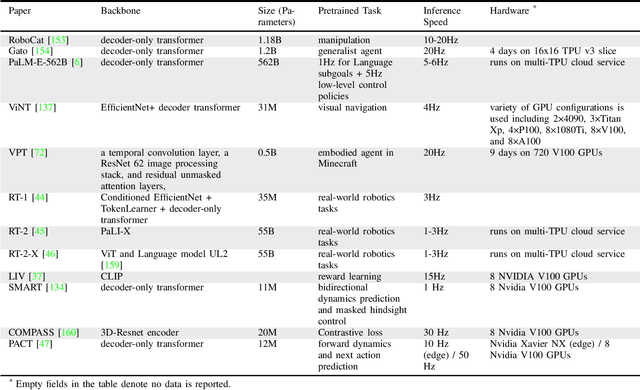
We survey applications of pretrained foundation models in robotics. Traditional deep learning models in robotics are trained on small datasets tailored for specific tasks, which limits their adaptability across diverse applications. In contrast, foundation models pretrained on internet-scale data appear to have superior generalization capabilities, and in some instances display an emergent ability to find zero-shot solutions to problems that are not present in the training data. Foundation models may hold the potential to enhance various components of the robot autonomy stack, from perception to decision-making and control. For example, large language models can generate code or provide common sense reasoning, while vision-language models enable open-vocabulary visual recognition. However, significant open research challenges remain, particularly around the scarcity of robot-relevant training data, safety guarantees and uncertainty quantification, and real-time execution. In this survey, we study recent papers that have used or built foundation models to solve robotics problems. We explore how foundation models contribute to improving robot capabilities in the domains of perception, decision-making, and control. We discuss the challenges hindering the adoption of foundation models in robot autonomy and provide opportunities and potential pathways for future advancements. The GitHub project corresponding to this paper (Preliminary release. We are committed to further enhancing and updating this work to ensure its quality and relevance) can be found here: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
GraspGPT: Leveraging Semantic Knowledge from a Large Language Model for Task-Oriented Grasping
Jul 30, 2023



Task-oriented grasping (TOG) refers to the problem of predicting grasps on an object that enable subsequent manipulation tasks. To model the complex relationships between objects, tasks, and grasps, existing methods incorporate semantic knowledge as priors into TOG pipelines. However, the existing semantic knowledge is typically constructed based on closed-world concept sets, restraining the generalization to novel concepts out of the pre-defined sets. To address this issue, we propose GraspGPT, a large language model (LLM) based TOG framework that leverages the open-end semantic knowledge from an LLM to achieve zero-shot generalization to novel concepts. We conduct experiments on Language Augmented TaskGrasp (LA-TaskGrasp) dataset and demonstrate that GraspGPT outperforms existing TOG methods on different held-out settings when generalizing to novel concepts out of the training set. The effectiveness of GraspGPT is further validated in real-robot experiments. Our code, data, appendix, and video are publicly available at https://sites.google.com/view/graspgpt/.
Latent Space Planning for Multi-Object Manipulation with Environment-Aware Relational Classifiers
May 18, 2023



Objects rarely sit in isolation in everyday human environments. If we want robots to operate and perform tasks in our human environments, they must understand how the objects they manipulate will interact with structural elements of the environment for all but the simplest of tasks. As such, we'd like our robots to reason about how multiple objects and environmental elements relate to one another and how those relations may change as the robot interacts with the world. We examine the problem of predicting inter-object and object-environment relations between previously unseen objects and novel environments purely from partial-view point clouds. Our approach enables robots to plan and execute sequences to complete multi-object manipulation tasks defined from logical relations. This removes the burden of providing explicit, continuous object states as goals to the robot. We explore several different neural network architectures for this task. We find the best performing model to be a novel transformer-based neural network that both predicts object-environment relations and learns a latent-space dynamics function. We achieve reliable sim-to-real transfer without any fine-tuning. Our experiments show that our model understands how changes in observed environmental geometry relate to semantic relations between objects. We show more videos on our website: https://sites.google.com/view/erelationaldynamics.
Task-Oriented Grasp Prediction with Visual-Language Inputs
Feb 28, 2023



To perform household tasks, assistive robots receive commands in the form of user language instructions for tool manipulation. The initial stage involves selecting the intended tool (i.e., object grounding) and grasping it in a task-oriented manner (i.e., task grounding). Nevertheless, prior researches on visual-language grasping (VLG) focus on object grounding, while disregarding the fine-grained impact of tasks on object grasping. Task-incompatible grasping of a tool will inevitably limit the success of subsequent manipulation steps. Motivated by this problem, this paper proposes GraspCLIP, which addresses the challenge of task grounding in addition to object grounding to enable task-oriented grasp prediction with visual-language inputs. Evaluation on a custom dataset demonstrates that GraspCLIP achieves superior performance over established baselines with object grounding only. The effectiveness of the proposed method is further validated on an assistive robotic arm platform for grasping previously unseen kitchen tools given the task specification. Our presentation video is available at: https://www.youtube.com/watch?v=e1wfYQPeAXU.
StructDiffusion: Object-Centric Diffusion for Semantic Rearrangement of Novel Objects
Nov 08, 2022



Robots operating in human environments must be able to rearrange objects into semantically-meaningful configurations, even if these objects are previously unseen. In this work, we focus on the problem of building physically-valid structures without step-by-step instructions. We propose StructDiffusion, which combines a diffusion model and an object-centric transformer to construct structures out of a single RGB-D image based on high-level language goals, such as "set the table." Our method shows how diffusion models can be used for complex multi-step 3D planning tasks. StructDiffusion improves success rate on assembling physically-valid structures out of unseen objects by on average 16% over an existing multi-modal transformer model, while allowing us to use one multi-task model to produce a wider range of different structures. We show experiments on held-out objects in both simulation and on real-world rearrangement tasks. For videos and additional results, check out our website: http://weiyuliu.com/StructDiffusion/.
StructFormer: Learning Spatial Structure for Language-Guided Semantic Rearrangement of Novel Objects
Oct 19, 2021



Geometric organization of objects into semantically meaningful arrangements pervades the built world. As such, assistive robots operating in warehouses, offices, and homes would greatly benefit from the ability to recognize and rearrange objects into these semantically meaningful structures. To be useful, these robots must contend with previously unseen objects and receive instructions without significant programming. While previous works have examined recognizing pairwise semantic relations and sequential manipulation to change these simple relations none have shown the ability to arrange objects into complex structures such as circles or table settings. To address this problem we propose a novel transformer-based neural network, StructFormer, which takes as input a partial-view point cloud of the current object arrangement and a structured language command encoding the desired object configuration. We show through rigorous experiments that StructFormer enables a physical robot to rearrange novel objects into semantically meaningful structures with multi-object relational constraints inferred from the language command.
Towards Robust One-shot Task Execution using Knowledge Graph Embeddings
May 10, 2021



Requiring multiple demonstrations of a task plan presents a burden to end-users of robots. However, robustly executing tasks plans from a single end-user demonstration is an ongoing challenge in robotics. We address the problem of one-shot task execution, in which a robot must generalize a single demonstration or prototypical example of a task plan to a new execution environment. Our approach integrates task plans with domain knowledge to infer task plan constituents for new execution environments. Our experimental evaluations show that our knowledge representation makes more relevant generalizations that result in significantly higher success rates over tested baselines. We validated the approach on a physical platform, which resulted in the successful generalization of initial task plans to 38 of 50 execution environments with errors resulting from autonomous robot operation included.
Same Object, Different Grasps: Data and Semantic Knowledge for Task-Oriented Grasping
Nov 13, 2020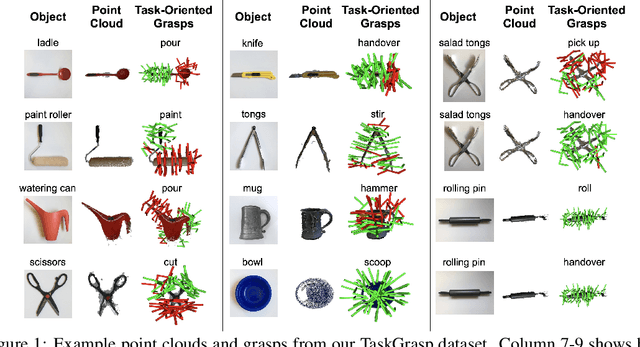

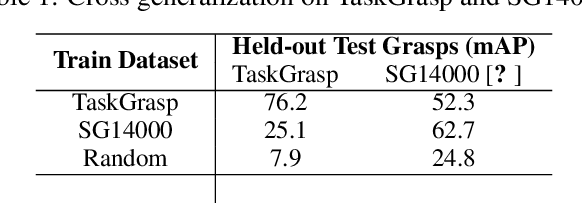

Despite the enormous progress and generalization in robotic grasping in recent years, existing methods have yet to scale and generalize task-oriented grasping to the same extent. This is largely due to the scale of the datasets both in terms of the number of objects and tasks studied. We address these concerns with the TaskGrasp dataset which is more diverse both in terms of objects and tasks, and an order of magnitude larger than previous datasets. The dataset contains 250K task-oriented grasps for 56 tasks and 191 objects along with their RGB-D information. We take advantage of this new breadth and diversity in the data and present the GCNGrasp framework which uses the semantic knowledge of objects and tasks encoded in a knowledge graph to generalize to new object instances, classes and even new tasks. Our framework shows a significant improvement of around 12% on held-out settings compared to baseline methods which do not use semantics. We demonstrate that our dataset and model are applicable for the real world by executing task-oriented grasps on a real robot on unknown objects. Code, data and supplementary video could be found at https://sites.google.com/view/taskgrasp