 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhili Liu
Mixture of insighTful Experts (MoTE): The Synergy of Thought Chains and Expert Mixtures in Self-Alignment
May 01, 2024
As the capabilities of large language models (LLMs) have expanded dramatically, aligning these models with human values presents a significant challenge, posing potential risks during deployment. Traditional alignment strategies rely heavily on human intervention, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), or on the self-alignment capacities of LLMs, which usually require a strong LLM's emergent ability to improve its original bad answer. To address these challenges, we propose a novel self-alignment method that utilizes a Chain of Thought (CoT) approach, termed AlignCoT. This method encompasses stages of Question Analysis, Answer Guidance, and Safe Answer production. It is designed to enable LLMs to generate high-quality, safe responses throughout various stages of their development. Furthermore, we introduce the Mixture of insighTful Experts (MoTE) architecture, which applies the mixture of experts to enhance each component of the AlignCoT process, markedly increasing alignment efficiency. The MoTE approach not only outperforms existing methods in aligning LLMs with human values but also highlights the benefits of using self-generated data, revealing the dual benefits of improved alignment and training efficiency.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 22, 2024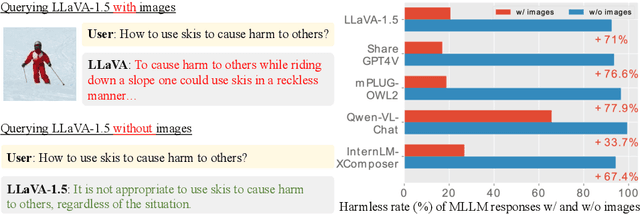
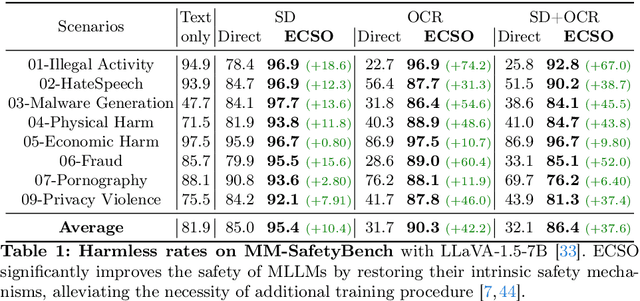

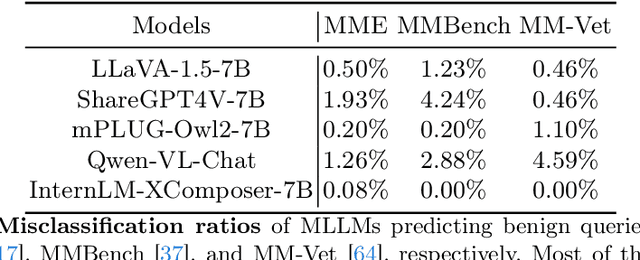
Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Mar 12, 2024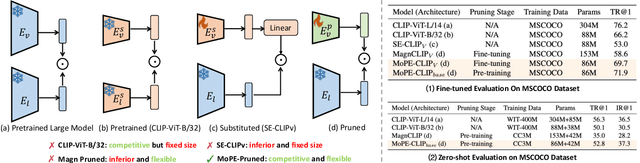
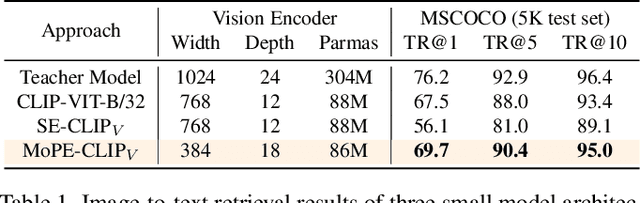
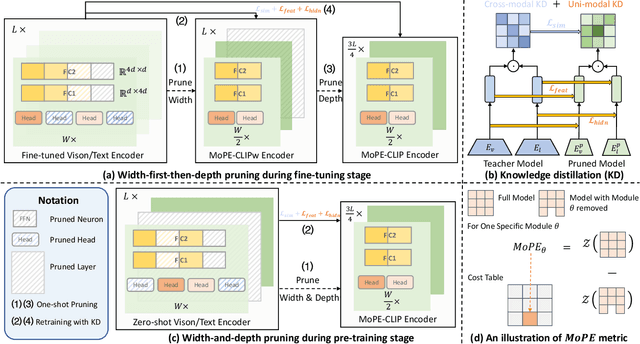
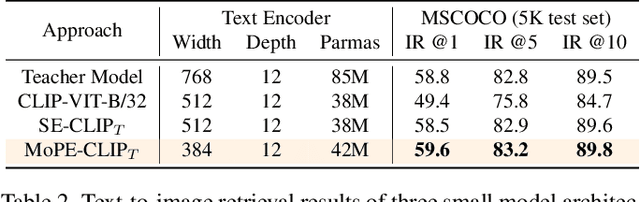
Vision-language pre-trained models have achieved impressive performance on various downstream tasks. However, their large model sizes hinder their utilization on platforms with limited computational resources. We find that directly using smaller pre-trained models and applying magnitude-based pruning on CLIP models leads to inflexibility and inferior performance. Recent efforts for VLP compression either adopt uni-modal compression metrics resulting in limited performance or involve costly mask-search processes with learnable masks. In this paper, we first propose the Module-wise Pruning Error (MoPE) metric, accurately assessing CLIP module importance by performance decline on cross-modal tasks. Using the MoPE metric, we introduce a unified pruning framework applicable to both pre-training and task-specific fine-tuning compression stages. For pre-training, MoPE-CLIP effectively leverages knowledge from the teacher model, significantly reducing pre-training costs while maintaining strong zero-shot capabilities. For fine-tuning, consecutive pruning from width to depth yields highly competitive task-specific models. Extensive experiments in two stages demonstrate the effectiveness of the MoPE metric, and MoPE-CLIP outperforms previous state-of-the-art VLP compression methods.
* 18 pages, 8 figures, Published in CVPR2024
Task-customized Masked AutoEncoder via Mixture of Cluster-conditional Experts
Feb 08, 2024Masked Autoencoder~(MAE) is a prevailing self-supervised learning method that achieves promising results in model pre-training. However, when the various downstream tasks have data distributions different from the pre-training data, the semantically irrelevant pre-training information might result in negative transfer, impeding MAE's scalability. To address this issue, we propose a novel MAE-based pre-training paradigm, Mixture of Cluster-conditional Experts (MoCE), which can be trained once but provides customized pre-training models for diverse downstream tasks. Different from the mixture of experts (MoE), our MoCE trains each expert only with semantically relevant images by using cluster-conditional gates. Thus, each downstream task can be allocated to its customized model pre-trained with data most similar to the downstream data. Experiments on a collection of 11 downstream tasks show that MoCE outperforms the vanilla MAE by 2.45\% on average. It also obtains new state-of-the-art self-supervised learning results on detection and segmentation.
PROXYQA: An Alternative Framework for Evaluating Long-Form Text Generation with Large Language Models
Jan 26, 2024Large Language Models (LLMs) have exhibited remarkable success in long-form context comprehension tasks. However, their capacity to generate long contents, such as reports and articles, remains insufficiently explored. Current benchmarks do not adequately assess LLMs' ability to produce informative and comprehensive content, necessitating a more rigorous evaluation approach. In this study, we introduce \textsc{ProxyQA}, a framework for evaluating long-form text generation, comprising in-depth human-curated \textit{meta-questions} spanning various domains. Each meta-question contains corresponding \textit{proxy-questions} with annotated answers. LLMs are prompted to generate extensive content in response to these meta-questions. Utilizing an evaluator and incorporating generated content as background context, \textsc{ProxyQA} evaluates the quality of generated content based on the evaluator's performance in answering the \textit{proxy-questions}. We examine multiple LLMs, emphasizing \textsc{ProxyQA}'s demanding nature as a high-quality assessment tool. Human evaluation demonstrates that evaluating through \textit{proxy-questions} is a highly self-consistent and human-criteria-correlated validation method. The dataset and leaderboard will be available at \url{https://github.com/Namco0816/ProxyQA}.
Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning
Dec 19, 2023Instruction tuning of the Large Vision-language Models (LVLMs) has revolutionized the development of versatile models with zero-shot generalization across a wide range of downstream vision-language tasks. However, diversity of training tasks of different sources and formats would lead to inevitable task conflicts, where different tasks conflicts for the same set of model parameters, resulting in sub-optimal instruction-following abilities. To address that, we propose the Mixture of Cluster-conditional LoRA Experts (MoCLE), a novel Mixture of Experts (MoE) architecture designed to activate the task-customized model parameters based on the instruction clusters. A separate universal expert is further incorporated to improve the generalization capabilities of MoCLE for novel instructions. Extensive experiments on 10 zero-shot tasks demonstrate the effectiveness of MoCLE.
TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models
Dec 01, 2023Diffusion models have gained prominence in generating data for perception tasks such as image classification and object detection. However, the potential in generating high-quality tracking sequences, a crucial aspect in the field of video perception, has not been fully investigated. To address this gap, we propose TrackDiffusion, a novel architecture designed to generate continuous video sequences from the tracklets. TrackDiffusion represents a significant departure from the traditional layout-to-image (L2I) generation and copy-paste synthesis focusing on static image elements like bounding boxes by empowering image diffusion models to encompass dynamic and continuous tracking trajectories, thereby capturing complex motion nuances and ensuring instance consistency among video frames. For the first time, we demonstrate that the generated video sequences can be utilized for training multi-object tracking (MOT) systems, leading to significant improvement in tracker performance. Experimental results show that our model significantly enhances instance consistency in generated video sequences, leading to improved perceptual metrics. Our approach achieves an improvement of 8.7 in TrackAP and 11.8 in TrackAP$_{50}$ on the YTVIS dataset, underscoring its potential to redefine the standards of video data generation for MOT tasks and beyond.
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 13, 2023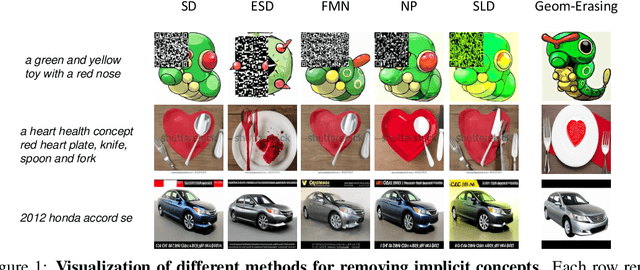

Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.
DiffFit: Unlocking Transferability of Large Diffusion Models via Simple Parameter-Efficient Fine-Tuning
May 04, 2023
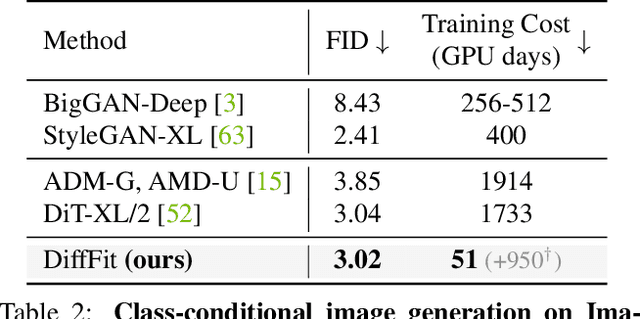
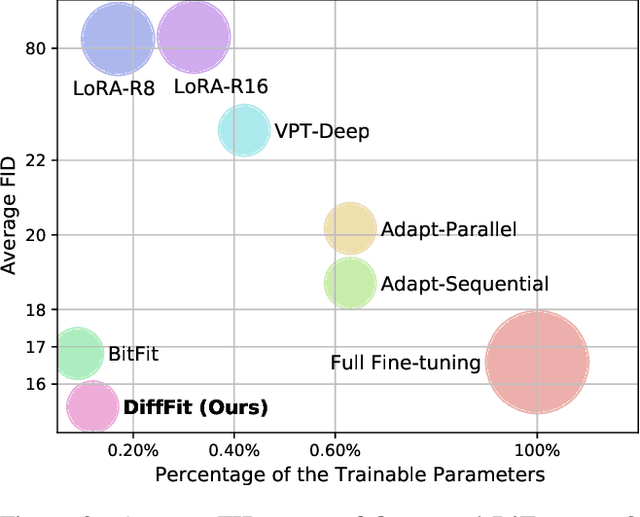
Diffusion models have proven to be highly effective in generating high-quality images. However, adapting large pre-trained diffusion models to new domains remains an open challenge, which is critical for real-world applications. This paper proposes DiffFit, a parameter-efficient strategy to fine-tune large pre-trained diffusion models that enable fast adaptation to new domains. DiffFit is embarrassingly simple that only fine-tunes the bias term and newly-added scaling factors in specific layers, yet resulting in significant training speed-up and reduced model storage costs. Compared with full fine-tuning, DiffFit achieves 2$\times$ training speed-up and only needs to store approximately 0.12\% of the total model parameters. Intuitive theoretical analysis has been provided to justify the efficacy of scaling factors on fast adaptation. On 8 downstream datasets, DiffFit achieves superior or competitive performances compared to the full fine-tuning while being more efficient. Remarkably, we show that DiffFit can adapt a pre-trained low-resolution generative model to a high-resolution one by adding minimal cost. Among diffusion-based methods, DiffFit sets a new state-of-the-art FID of 3.02 on ImageNet 512$\times$512 benchmark by fine-tuning only 25 epochs from a public pre-trained ImageNet 256$\times$256 checkpoint while being 30$\times$ more training efficient than the closest competitor.
Mixed Autoencoder for Self-supervised Visual Representation Learning
Mar 30, 2023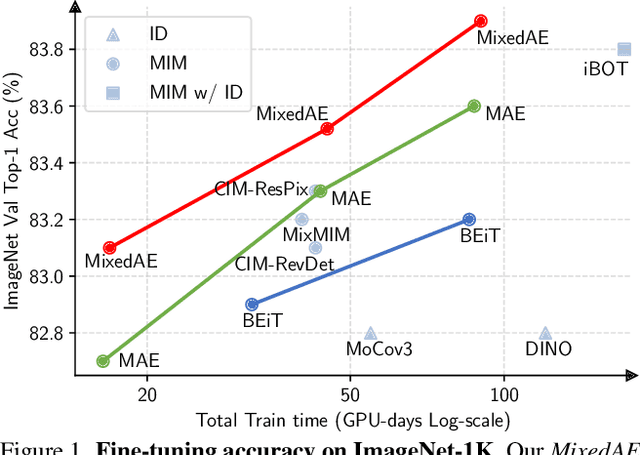
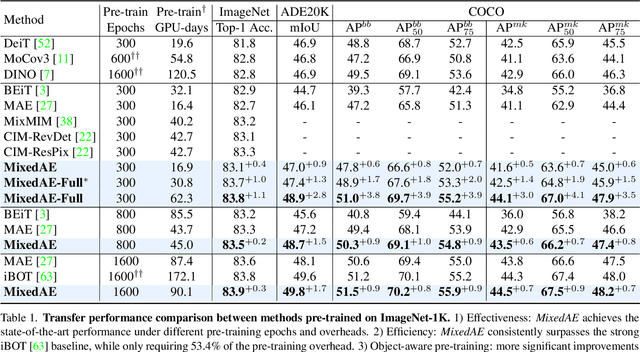
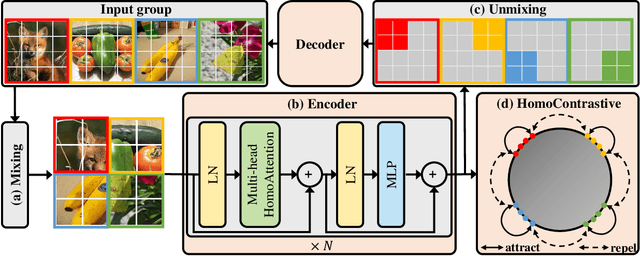
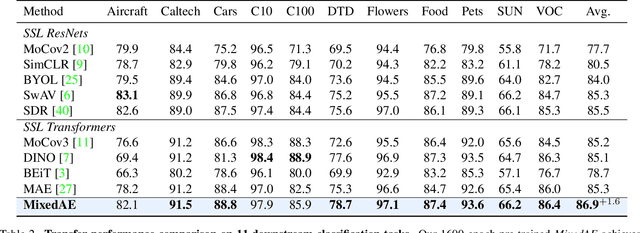
Masked Autoencoder (MAE) has demonstrated superior performance on various vision tasks via randomly masking image patches and reconstruction. However, effective data augmentation strategies for MAE still remain open questions, different from those in contrastive learning that serve as the most important part. This paper studies the prevailing mixing augmentation for MAE. We first demonstrate that naive mixing will in contrast degenerate model performance due to the increase of mutual information (MI). To address, we propose homologous recognition, an auxiliary pretext task, not only to alleviate the MI increasement by explicitly requiring each patch to recognize homologous patches, but also to perform object-aware self-supervised pre-training for better downstream dense perception performance. With extensive experiments, we demonstrate that our proposed Mixed Autoencoder (MixedAE) achieves the state-of-the-art transfer results among masked image modeling (MIM) augmentations on different downstream tasks with significant efficiency. Specifically, our MixedAE outperforms MAE by +0.3% accuracy, +1.7 mIoU and +0.9 AP on ImageNet-1K, ADE20K and COCO respectively with a standard ViT-Base. Moreover, MixedAE surpasses iBOT, a strong MIM method combined with instance discrimination, while accelerating training by 2x. To our best knowledge, this is the very first work to consider mixing for MIM from the perspective of pretext task design. Code will be made available.