 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Li
Graph Neural Networks for Wireless Networks: Graph Representation, Architecture and Evaluation
Apr 18, 2024
Graph neural networks (GNNs) have been regarded as the basic model to facilitate deep learning (DL) to revolutionize resource allocation in wireless networks. GNN-based models are shown to be able to learn the structural information about graphs representing the wireless networks to adapt to the time-varying channel state information and dynamics of network topology. This article aims to provide a comprehensive overview of applying GNNs to optimize wireless networks via answering three fundamental questions, i.e., how to input the wireless network data into GNNs, how to improve the performance of GNNs, and how to evaluate GNNs. Particularly, two graph representations are given to transform wireless network parameters into graph-structured data. Then, we focus on the architecture design of the GNN-based models via introducing the basic message passing as well as model improvement methods including multi-head attention mechanism and residual structure. At last, we give task-oriented evaluation metrics for DL-enabled wireless resource allocation. We also highlight certain challenges and potential research directions for the application of GNNs in wireless networks.
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Apr 02, 2024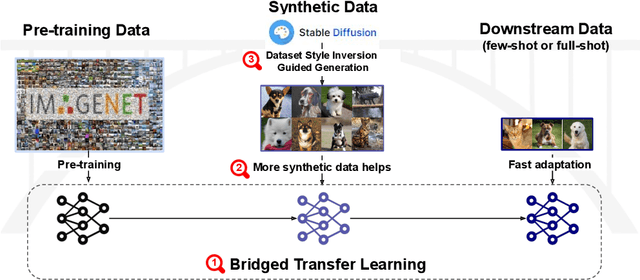
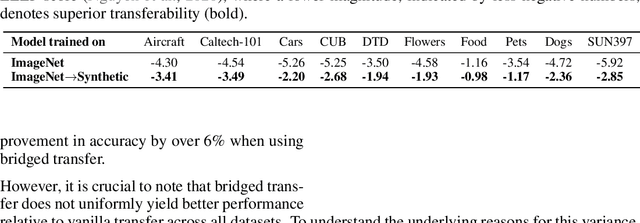
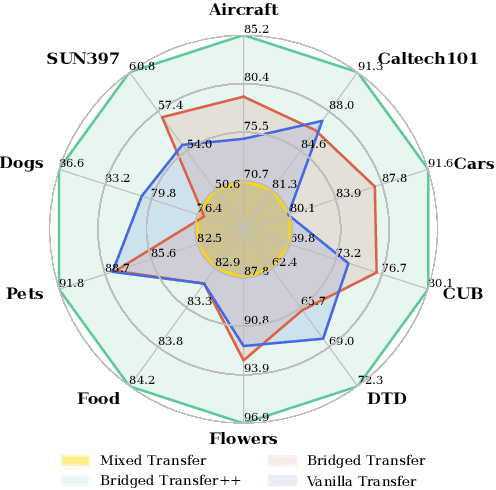

Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior
Apr 02, 2024The environmental perception of autonomous vehicles in normal conditions have achieved considerable success in the past decade. However, various unfavourable conditions such as fog, low-light, and motion blur will degrade image quality and pose tremendous threats to the safety of autonomous driving. That is, when applied to degraded images, state-of-the-art visual models often suffer performance decline due to the feature content loss and artifact interference caused by statistical and structural properties disruption of captured images. To address this problem, this work proposes a novel Deep Channel Prior (DCP) for degraded visual recognition. Specifically, we observe that, in the deep representation space of pre-trained models, the channel correlations of degraded features with the same degradation type have uniform distribution even if they have different content and semantics, which can facilitate the mapping relationship learning between degraded and clear representations in high-sparsity feature space. Based on this, a novel plug-and-play Unsupervised Feature Enhancement Module (UFEM) is proposed to achieve unsupervised feature correction, where the multi-adversarial mechanism is introduced in the first stage of UFEM to achieve the latent content restoration and artifact removal in high-sparsity feature space. Then, the generated features are transferred to the second stage for global correlation modulation under the guidance of DCP to obtain high-quality and recognition-friendly features. Evaluations of three tasks and eight benchmark datasets demonstrate that our proposed method can comprehensively improve the performance of pre-trained models in real degradation conditions. The source code is available at https://github.com/liyuhang166/Deep_Channel_Prior
Multiplane Quantitative Phase Imaging Using a Wavelength-Multiplexed Diffractive Optical Processor
Mar 16, 2024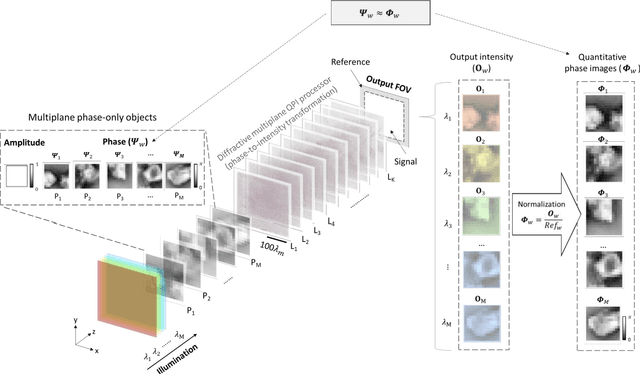

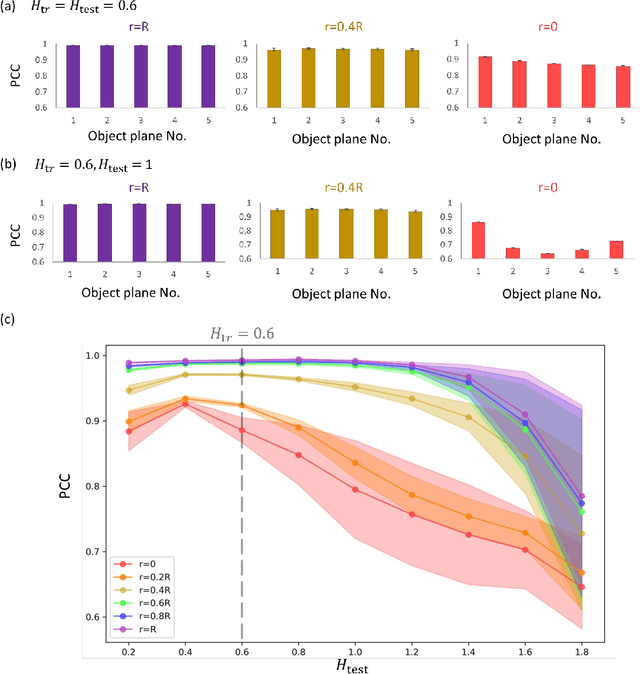
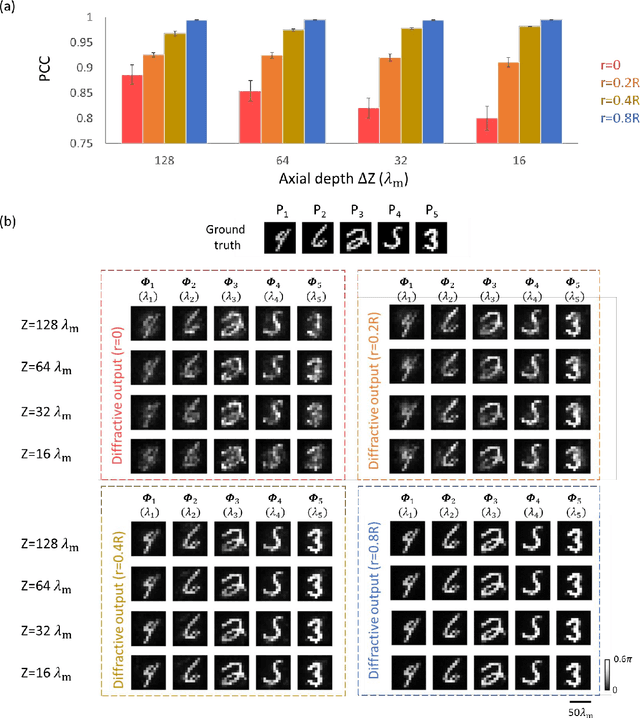
Quantitative phase imaging (QPI) is a label-free technique that provides optical path length information for transparent specimens, finding utility in biology, materials science, and engineering. Here, we present quantitative phase imaging of a 3D stack of phase-only objects using a wavelength-multiplexed diffractive optical processor. Utilizing multiple spatially engineered diffractive layers trained through deep learning, this diffractive processor can transform the phase distributions of multiple 2D objects at various axial positions into intensity patterns, each encoded at a unique wavelength channel. These wavelength-multiplexed patterns are projected onto a single field-of-view (FOV) at the output plane of the diffractive processor, enabling the capture of quantitative phase distributions of input objects located at different axial planes using an intensity-only image sensor. Based on numerical simulations, we show that our diffractive processor could simultaneously achieve all-optical quantitative phase imaging across several distinct axial planes at the input by scanning the illumination wavelength. A proof-of-concept experiment with a 3D-fabricated diffractive processor further validated our approach, showcasing successful imaging of two distinct phase objects at different axial positions by scanning the illumination wavelength in the terahertz spectrum. Diffractive network-based multiplane QPI designs can open up new avenues for compact on-chip phase imaging and sensing devices.
One-stage Prompt-based Continual Learning
Feb 25, 2024Prompt-based Continual Learning (PCL) has gained considerable attention as a promising continual learning solution as it achieves state-of-the-art performance while preventing privacy violation and memory overhead issues. Nonetheless, existing PCL approaches face significant computational burdens because of two Vision Transformer (ViT) feed-forward stages; one is for the query ViT that generates a prompt query to select prompts inside a prompt pool; the other one is a backbone ViT that mixes information between selected prompts and image tokens. To address this, we introduce a one-stage PCL framework by directly using the intermediate layer's token embedding as a prompt query. This design removes the need for an additional feed-forward stage for query ViT, resulting in ~50% computational cost reduction for both training and inference with marginal accuracy drop < 1%. We further introduce a Query-Pool Regularization (QR) loss that regulates the relationship between the prompt query and the prompt pool to improve representation power. The QR loss is only applied during training time, so there is no computational overhead at inference from the QR loss. With the QR loss, our approach maintains ~ 50% computational cost reduction during inference as well as outperforms the prior two-stage PCL methods by ~1.4% on public class-incremental continual learning benchmarks including CIFAR-100, ImageNet-R, and DomainNet.
Multiplexed all-optical permutation operations using a reconfigurable diffractive optical network
Feb 04, 2024Large-scale and high-dimensional permutation operations are important for various applications in e.g., telecommunications and encryption. Here, we demonstrate the use of all-optical diffractive computing to execute a set of high-dimensional permutation operations between an input and output field-of-view through layer rotations in a diffractive optical network. In this reconfigurable multiplexed material designed by deep learning, every diffractive layer has four orientations: 0, 90, 180, and 270 degrees. Each unique combination of these rotatable layers represents a distinct rotation state of the diffractive design tailored for a specific permutation operation. Therefore, a K-layer rotatable diffractive material is capable of all-optically performing up to 4^K independent permutation operations. The original input information can be decrypted by applying the specific inverse permutation matrix to output patterns, while applying other inverse operations will lead to loss of information. We demonstrated the feasibility of this reconfigurable multiplexed diffractive design by approximating 256 randomly selected permutation matrices using K=4 rotatable diffractive layers. We also experimentally validated this reconfigurable diffractive network using terahertz radiation and 3D-printed diffractive layers, providing a decent match to our numerical results. The presented rotation-multiplexed diffractive processor design is particularly useful due to its mechanical reconfigurability, offering multifunctional representation through a single fabrication process.
All-optical complex field imaging using diffractive processors
Jan 30, 2024Complex field imaging, which captures both the amplitude and phase information of input optical fields or objects, can offer rich structural insights into samples, such as their absorption and refractive index distributions. However, conventional image sensors are intensity-based and inherently lack the capability to directly measure the phase distribution of a field. This limitation can be overcome using interferometric or holographic methods, often supplemented by iterative phase retrieval algorithms, leading to a considerable increase in hardware complexity and computational demand. Here, we present a complex field imager design that enables snapshot imaging of both the amplitude and quantitative phase information of input fields using an intensity-based sensor array without any digital processing. Our design utilizes successive deep learning-optimized diffractive surfaces that are structured to collectively modulate the input complex field, forming two independent imaging channels that perform amplitude-to-amplitude and phase-to-intensity transformations between the input and output planes within a compact optical design, axially spanning ~100 wavelengths. The intensity distributions of the output fields at these two channels on the sensor plane directly correspond to the amplitude and quantitative phase profiles of the input complex field, eliminating the need for any digital image reconstruction algorithms. We experimentally validated the efficacy of our complex field diffractive imager designs through 3D-printed prototypes operating at the terahertz spectrum, with the output amplitude and phase channel images closely aligning with our numerical simulations. We envision that this complex field imager will have various applications in security, biomedical imaging, sensing and material science, among others.
Subwavelength Imaging using a Solid-Immersion Diffractive Optical Processor
Jan 17, 2024Phase imaging is widely used in biomedical imaging, sensing, and material characterization, among other fields. However, direct imaging of phase objects with subwavelength resolution remains a challenge. Here, we demonstrate subwavelength imaging of phase and amplitude objects based on all-optical diffractive encoding and decoding. To resolve subwavelength features of an object, the diffractive imager uses a thin, high-index solid-immersion layer to transmit high-frequency information of the object to a spatially-optimized diffractive encoder, which converts/encodes high-frequency information of the input into low-frequency spatial modes for transmission through air. The subsequent diffractive decoder layers (in air) are jointly designed with the encoder using deep-learning-based optimization, and communicate with the encoder layer to create magnified images of input objects at its output, revealing subwavelength features that would otherwise be washed away due to diffraction limit. We demonstrate that this all-optical collaboration between a diffractive solid-immersion encoder and the following decoder layers in air can resolve subwavelength phase and amplitude features of input objects in a highly compact design. To experimentally demonstrate its proof-of-concept, we used terahertz radiation and developed a fabrication method for creating monolithic multi-layer diffractive processors. Through these monolithically fabricated diffractive encoder-decoder pairs, we demonstrated phase-to-intensity transformations and all-optically reconstructed subwavelength phase features of input objects by directly transforming them into magnified intensity features at the output. This solid-immersion-based diffractive imager, with its compact and cost-effective design, can find wide-ranging applications in bioimaging, endoscopy, sensing and materials characterization.
Information hiding cameras: optical concealment of object information into ordinary images
Jan 15, 2024Data protection methods like cryptography, despite being effective, inadvertently signal the presence of secret communication, thereby drawing undue attention. Here, we introduce an optical information hiding camera integrated with an electronic decoder, optimized jointly through deep learning. This information hiding-decoding system employs a diffractive optical processor as its front-end, which transforms and hides input images in the form of ordinary-looking patterns that deceive/mislead human observers. This information hiding transformation is valid for infinitely many combinations of secret messages, all of which are transformed into ordinary-looking output patterns, achieved all-optically through passive light-matter interactions within the optical processor. By processing these ordinary-looking output images, a jointly-trained electronic decoder neural network accurately reconstructs the original information hidden within the deceptive output pattern. We numerically demonstrated our approach by designing an information hiding diffractive camera along with a jointly-optimized convolutional decoder neural network. The efficacy of this system was demonstrated under various lighting conditions and noise levels, showing its robustness. We further extended this information hiding camera to multi-spectral operation, allowing the concealment and decoding of multiple images at different wavelengths, all performed simultaneously in a single feed-forward operation. The feasibility of our framework was also demonstrated experimentally using THz radiation. This optical encoder-electronic decoder-based co-design provides a novel information hiding camera interface that is both high-speed and energy-efficient, offering an intriguing solution for visual information security.
TT-SNN: Tensor Train Decomposition for Efficient Spiking Neural Network Training
Jan 15, 2024Spiking Neural Networks (SNNs) have gained significant attention as a potentially energy-efficient alternative for standard neural networks with their sparse binary activation. However, SNNs suffer from memory and computation overhead due to spatio-temporal dynamics and multiple backpropagation computations across timesteps during training. To address this issue, we introduce Tensor Train Decomposition for Spiking Neural Networks (TT-SNN), a method that reduces model size through trainable weight decomposition, resulting in reduced storage, FLOPs, and latency. In addition, we propose a parallel computation pipeline as an alternative to the typical sequential tensor computation, which can be flexibly integrated into various existing SNN architectures. To the best of our knowledge, this is the first of its kind application of tensor decomposition in SNNs. We validate our method using both static and dynamic datasets, CIFAR10/100 and N-Caltech101, respectively. We also propose a TT-SNN-tailored training accelerator to fully harness the parallelism in TT-SNN. Our results demonstrate substantial reductions in parameter size (7.98X), FLOPs (9.25X), training time (17.7%), and training energy (28.3%) during training for the N-Caltech101 dataset, with negligible accuracy degradation.