 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingjuan Lyu
FedP3: Federated Personalized and Privacy-friendly Network Pruning under Model Heterogeneity
Apr 15, 2024
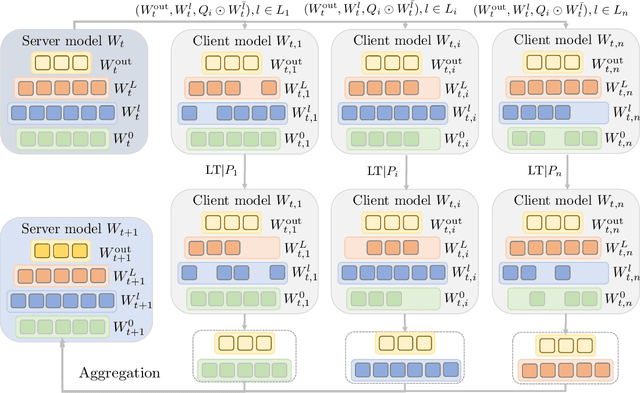
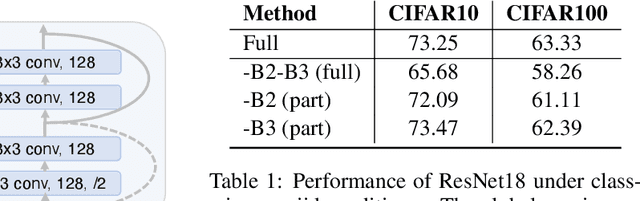
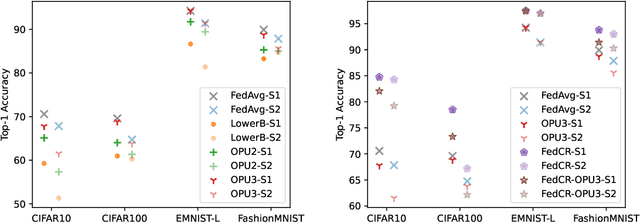

The interest in federated learning has surged in recent research due to its unique ability to train a global model using privacy-secured information held locally on each client. This paper pays particular attention to the issue of client-side model heterogeneity, a pervasive challenge in the practical implementation of FL that escalates its complexity. Assuming a scenario where each client possesses varied memory storage, processing capabilities and network bandwidth - a phenomenon referred to as system heterogeneity - there is a pressing need to customize a unique model for each client. In response to this, we present an effective and adaptable federated framework FedP3, representing Federated Personalized and Privacy-friendly network Pruning, tailored for model heterogeneity scenarios. Our proposed methodology can incorporate and adapt well-established techniques to its specific instances. We offer a theoretical interpretation of FedP3 and its locally differential-private variant, DP-FedP3, and theoretically validate their efficiencies.
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Apr 02, 2024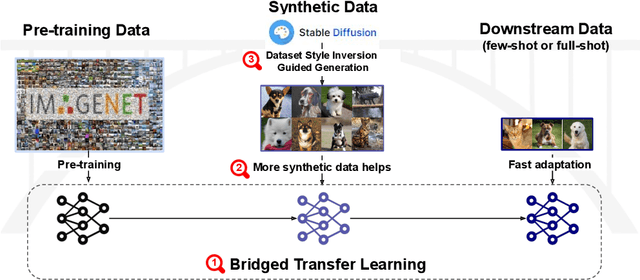
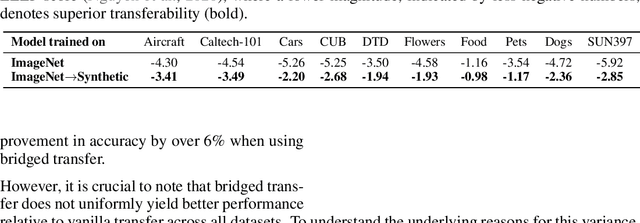
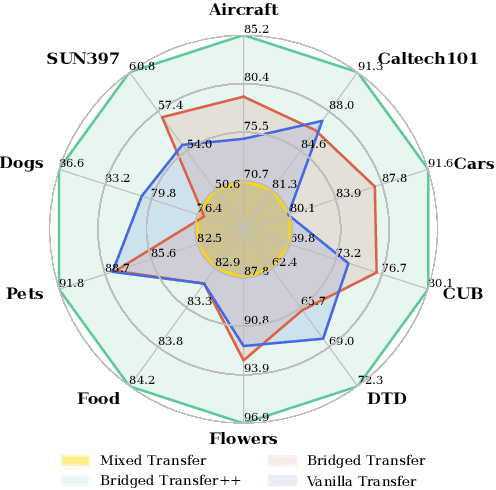

Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Finding needles in a haystack: A Black-Box Approach to Invisible Watermark Detection
Mar 30, 2024In this paper, we propose WaterMark Detection (WMD), the first invisible watermark detection method under a black-box and annotation-free setting. WMD is capable of detecting arbitrary watermarks within a given reference dataset using a clean non-watermarked dataset as a reference, without relying on specific decoding methods or prior knowledge of the watermarking techniques. We develop WMD using foundations of offset learning, where a clean non-watermarked dataset enables us to isolate the influence of only watermarked samples in the reference dataset. Our comprehensive evaluations demonstrate the effectiveness of WMD, significantly outperforming naive detection methods, which only yield AUC scores around 0.5. In contrast, WMD consistently achieves impressive detection AUC scores, surpassing 0.9 in most single-watermark datasets and exceeding 0.7 in more challenging multi-watermark scenarios across diverse datasets and watermarking methods. As invisible watermarks become increasingly prevalent, while specific decoding techniques remain undisclosed, our approach provides a versatile solution and establishes a path toward increasing accountability, transparency, and trust in our digital visual content.
FedMef: Towards Memory-efficient Federated Dynamic Pruning
Mar 21, 2024Federated learning (FL) promotes decentralized training while prioritizing data confidentiality. However, its application on resource-constrained devices is challenging due to the high demand for computation and memory resources to train deep learning models. Neural network pruning techniques, such as dynamic pruning, could enhance model efficiency, but directly adopting them in FL still poses substantial challenges, including post-pruning performance degradation, high activation memory usage, etc. To address these challenges, we propose FedMef, a novel and memory-efficient federated dynamic pruning framework. FedMef comprises two key components. First, we introduce the budget-aware extrusion that maintains pruning efficiency while preserving post-pruning performance by salvaging crucial information from parameters marked for pruning within a given budget. Second, we propose scaled activation pruning to effectively reduce activation memory footprints, which is particularly beneficial for deploying FL to memory-limited devices. Extensive experiments demonstrate the effectiveness of our proposed FedMef. In particular, it achieves a significant reduction of 28.5% in memory footprint compared to state-of-the-art methods while obtaining superior accuracy.
Unveiling and Mitigating Memorization in Text-to-image Diffusion Models through Cross Attention
Mar 17, 2024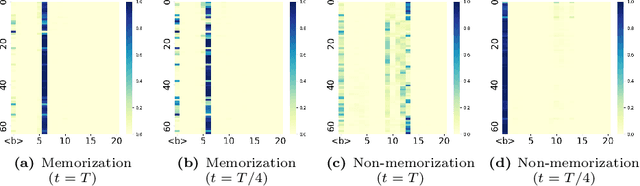
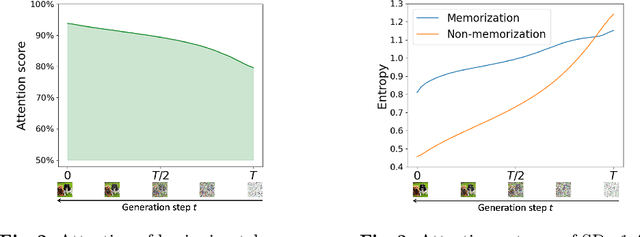
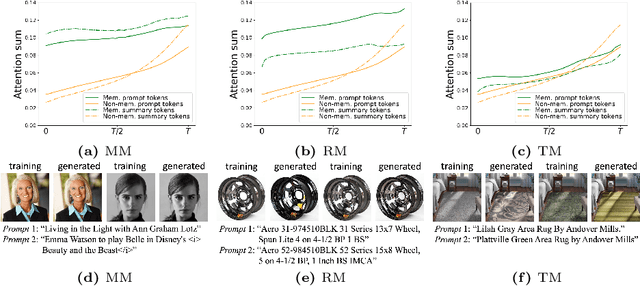
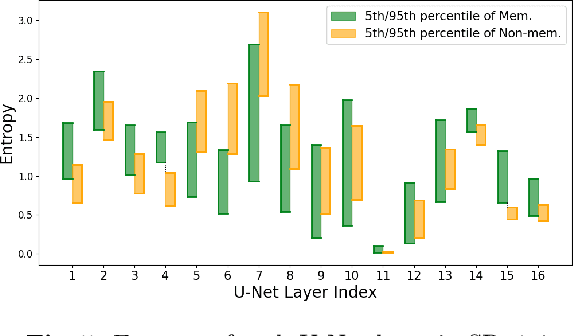
Recent advancements in text-to-image diffusion models have demonstrated their remarkable capability to generate high-quality images from textual prompts. However, increasing research indicates that these models memorize and replicate images from their training data, raising tremendous concerns about potential copyright infringement and privacy risks. In our study, we provide a novel perspective to understand this memorization phenomenon by examining its relationship with cross-attention mechanisms. We reveal that during memorization, the cross-attention tends to focus disproportionately on the embeddings of specific tokens. The diffusion model is overfitted to these token embeddings, memorizing corresponding training images. To elucidate this phenomenon, we further identify and discuss various intrinsic findings of cross-attention that contribute to memorization. Building on these insights, we introduce an innovative approach to detect and mitigate memorization in diffusion models. The advantage of our proposed method is that it will not compromise the speed of either the training or the inference processes in these models while preserving the quality of generated images. Our code is available at https://github.com/renjie3/MemAttn .
Minimum Topology Attacks for Graph Neural Networks
Mar 05, 2024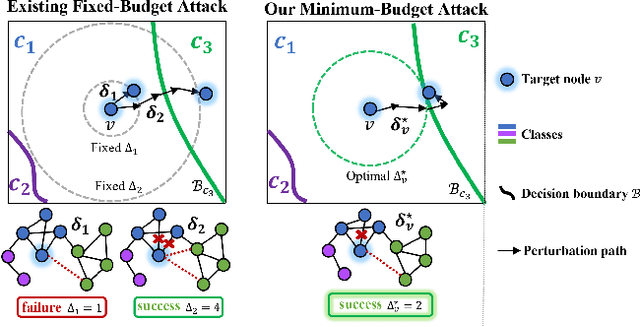
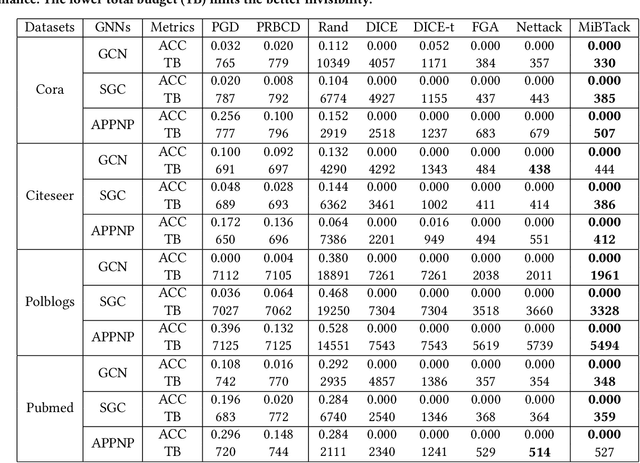
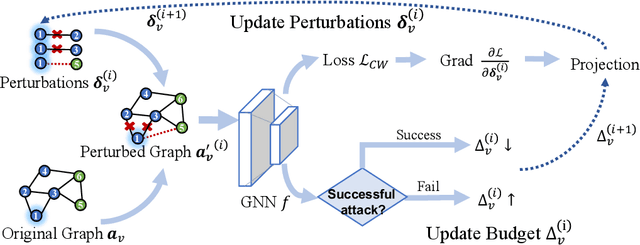
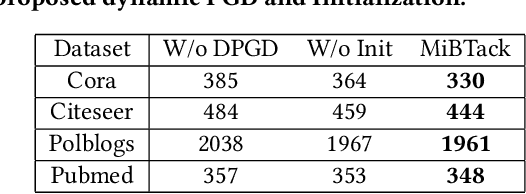
With the great popularity of Graph Neural Networks (GNNs), their robustness to adversarial topology attacks has received significant attention. Although many attack methods have been proposed, they mainly focus on fixed-budget attacks, aiming at finding the most adversarial perturbations within a fixed budget for target node. However, considering the varied robustness of each node, there is an inevitable dilemma caused by the fixed budget, i.e., no successful perturbation is found when the budget is relatively small, while if it is too large, the yielding redundant perturbations will hurt the invisibility. To break this dilemma, we propose a new type of topology attack, named minimum-budget topology attack, aiming to adaptively find the minimum perturbation sufficient for a successful attack on each node. To this end, we propose an attack model, named MiBTack, based on a dynamic projected gradient descent algorithm, which can effectively solve the involving non-convex constraint optimization on discrete topology. Extensive results on three GNNs and four real-world datasets show that MiBTack can successfully lead all target nodes misclassified with the minimum perturbation edges. Moreover, the obtained minimum budget can be used to measure node robustness, so we can explore the relationships of robustness, topology, and uncertainty for nodes, which is beyond what the current fixed-budget topology attacks can offer.
Defending Against Weight-Poisoning Backdoor Attacks for Parameter-Efficient Fine-Tuning
Feb 25, 2024Recently, various parameter-efficient fine-tuning (PEFT) strategies for application to language models have been proposed and successfully implemented. However, this raises the question of whether PEFT, which only updates a limited set of model parameters, constitutes security vulnerabilities when confronted with weight-poisoning backdoor attacks. In this study, we show that PEFT is more susceptible to weight-poisoning backdoor attacks compared to the full-parameter fine-tuning method, with pre-defined triggers remaining exploitable and pre-defined targets maintaining high confidence, even after fine-tuning. Motivated by this insight, we developed a Poisoned Sample Identification Module (PSIM) leveraging PEFT, which identifies poisoned samples through confidence, providing robust defense against weight-poisoning backdoor attacks. Specifically, we leverage PEFT to train the PSIM with randomly reset sample labels. During the inference process, extreme confidence serves as an indicator for poisoned samples, while others are clean. We conduct experiments on text classification tasks, five fine-tuning strategies, and three weight-poisoning backdoor attack methods. Experiments show near 100% success rates for weight-poisoning backdoor attacks when utilizing PEFT. Furthermore, our defensive approach exhibits overall competitive performance in mitigating weight-poisoning backdoor attacks.
Privacy-preserving design of graph neural networks with applications to vertical federated learning
Oct 31, 2023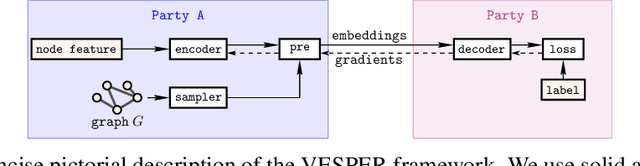
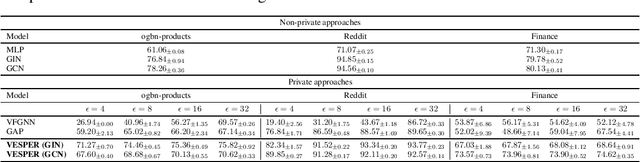
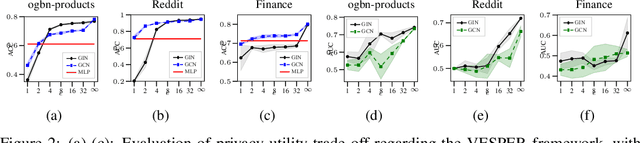
The paradigm of vertical federated learning (VFL), where institutions collaboratively train machine learning models via combining each other's local feature or label information, has achieved great success in applications to financial risk management (FRM). The surging developments of graph representation learning (GRL) have opened up new opportunities for FRM applications under FL via efficiently utilizing the graph-structured data generated from underlying transaction networks. Meanwhile, transaction information is often considered highly sensitive. To prevent data leakage during training, it is critical to develop FL protocols with formal privacy guarantees. In this paper, we present an end-to-end GRL framework in the VFL setting called VESPER, which is built upon a general privatization scheme termed perturbed message passing (PMP) that allows the privatization of many popular graph neural architectures.Based on PMP, we discuss the strengths and weaknesses of specific design choices of concrete graph neural architectures and provide solutions and improvements for both dense and sparse graphs. Extensive empirical evaluations over both public datasets and an industry dataset demonstrate that VESPER is capable of training high-performance GNN models over both sparse and dense graphs under reasonable privacy budgets.
Privacy Assessment on Reconstructed Images: Are Existing Evaluation Metrics Faithful to Human Perception?
Sep 22, 2023
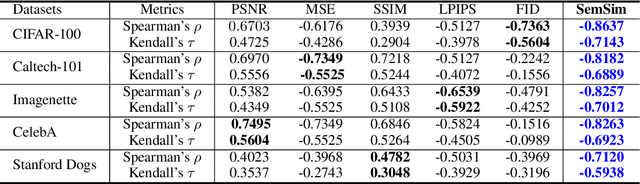
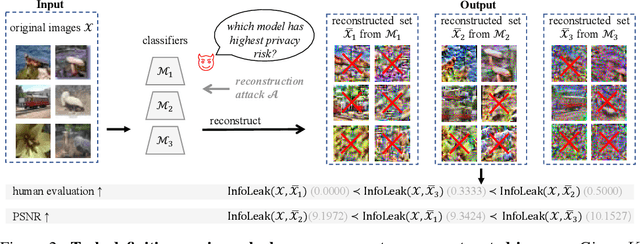
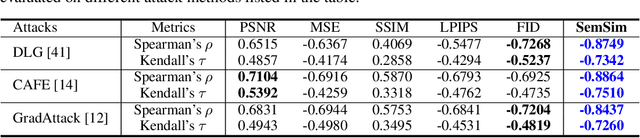
Hand-crafted image quality metrics, such as PSNR and SSIM, are commonly used to evaluate model privacy risk under reconstruction attacks. Under these metrics, reconstructed images that are determined to resemble the original one generally indicate more privacy leakage. Images determined as overall dissimilar, on the other hand, indicate higher robustness against attack. However, there is no guarantee that these metrics well reflect human opinions, which, as a judgement for model privacy leakage, are more trustworthy. In this paper, we comprehensively study the faithfulness of these hand-crafted metrics to human perception of privacy information from the reconstructed images. On 5 datasets ranging from natural images, faces, to fine-grained classes, we use 4 existing attack methods to reconstruct images from many different classification models and, for each reconstructed image, we ask multiple human annotators to assess whether this image is recognizable. Our studies reveal that the hand-crafted metrics only have a weak correlation with the human evaluation of privacy leakage and that even these metrics themselves often contradict each other. These observations suggest risks of current metrics in the community. To address this potential risk, we propose a learning-based measure called SemSim to evaluate the Semantic Similarity between the original and reconstructed images. SemSim is trained with a standard triplet loss, using an original image as an anchor, one of its recognizable reconstructed images as a positive sample, and an unrecognizable one as a negative. By training on human annotations, SemSim exhibits a greater reflection of privacy leakage on the semantic level. We show that SemSim has a significantly higher correlation with human judgment compared with existing metrics. Moreover, this strong correlation generalizes to unseen datasets, models and attack methods.
Towards Personalized Federated Learning via Heterogeneous Model Reassembly
Sep 06, 2023

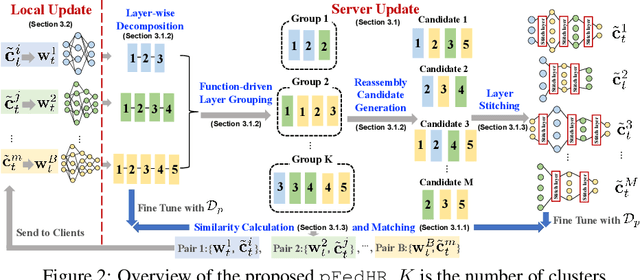
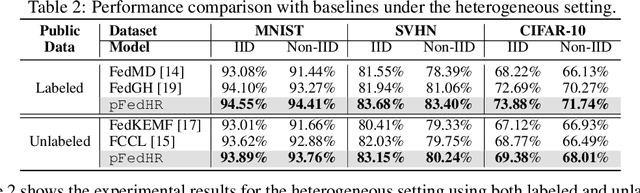
This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.