 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeihuizi Jia
Defending Against Weight-Poisoning Backdoor Attacks for Parameter-Efficient Fine-Tuning
Feb 25, 2024
Recently, various parameter-efficient fine-tuning (PEFT) strategies for application to language models have been proposed and successfully implemented. However, this raises the question of whether PEFT, which only updates a limited set of model parameters, constitutes security vulnerabilities when confronted with weight-poisoning backdoor attacks. In this study, we show that PEFT is more susceptible to weight-poisoning backdoor attacks compared to the full-parameter fine-tuning method, with pre-defined triggers remaining exploitable and pre-defined targets maintaining high confidence, even after fine-tuning. Motivated by this insight, we developed a Poisoned Sample Identification Module (PSIM) leveraging PEFT, which identifies poisoned samples through confidence, providing robust defense against weight-poisoning backdoor attacks. Specifically, we leverage PEFT to train the PSIM with randomly reset sample labels. During the inference process, extreme confidence serves as an indicator for poisoned samples, while others are clean. We conduct experiments on text classification tasks, five fine-tuning strategies, and three weight-poisoning backdoor attack methods. Experiments show near 100% success rates for weight-poisoning backdoor attacks when utilizing PEFT. Furthermore, our defensive approach exhibits overall competitive performance in mitigating weight-poisoning backdoor attacks.
Universal Vulnerabilities in Large Language Models: In-context Learning Backdoor Attacks
Jan 20, 2024In-context learning, a paradigm bridging the gap between pre-training and fine-tuning, has demonstrated high efficacy in several NLP tasks, especially in few-shot settings. Unlike traditional fine-tuning methods, in-context learning adapts pre-trained models to unseen tasks without updating any parameters. Despite being widely applied, in-context learning is vulnerable to malicious attacks. In this work, we raise security concerns regarding this paradigm. Our studies demonstrate that an attacker can manipulate the behavior of large language models by poisoning the demonstration context, without the need for fine-tuning the model. Specifically, we have designed a new backdoor attack method, named ICLAttack, to target large language models based on in-context learning. Our method encompasses two types of attacks: poisoning demonstration examples and poisoning prompts, which can make models behave in accordance with predefined intentions. ICLAttack does not require additional fine-tuning to implant a backdoor, thus preserving the model's generality. Furthermore, the poisoned examples are correctly labeled, enhancing the natural stealth of our attack method. Extensive experimental results across several language models, ranging in size from 1.3B to 40B parameters, demonstrate the effectiveness of our attack method, exemplified by a high average attack success rate of 95.0% across the three datasets on OPT models. Our findings highlight the vulnerabilities of language models, and we hope this work will raise awareness of the possible security threats associated with in-context learning.
MNER-QG: An End-to-End MRC framework for Multimodal Named Entity Recognition with Query Grounding
Nov 27, 2022

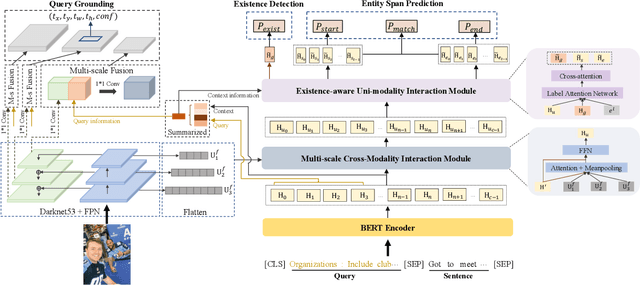
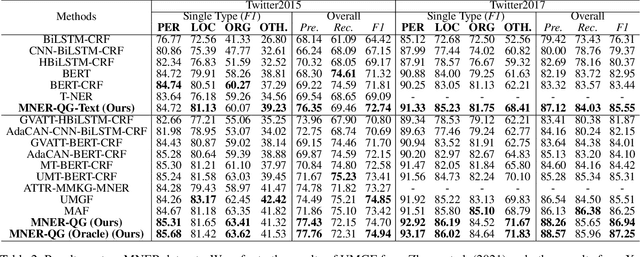
Multimodal named entity recognition (MNER) is a critical step in information extraction, which aims to detect entity spans and classify them to corresponding entity types given a sentence-image pair. Existing methods either (1) obtain named entities with coarse-grained visual clues from attention mechanisms, or (2) first detect fine-grained visual regions with toolkits and then recognize named entities. However, they suffer from improper alignment between entity types and visual regions or error propagation in the two-stage manner, which finally imports irrelevant visual information into texts. In this paper, we propose a novel end-to-end framework named MNER-QG that can simultaneously perform MRC-based multimodal named entity recognition and query grounding. Specifically, with the assistance of queries, MNER-QG can provide prior knowledge of entity types and visual regions, and further enhance representations of both texts and images. To conduct the query grounding task, we provide manual annotations and weak supervisions that are obtained via training a highly flexible visual grounding model with transfer learning. We conduct extensive experiments on two public MNER datasets, Twitter2015 and Twitter2017. Experimental results show that MNER-QG outperforms the current state-of-the-art models on the MNER task, and also improves the query grounding performance.