 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiangmo Zhao
Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior
Apr 02, 2024
The environmental perception of autonomous vehicles in normal conditions have achieved considerable success in the past decade. However, various unfavourable conditions such as fog, low-light, and motion blur will degrade image quality and pose tremendous threats to the safety of autonomous driving. That is, when applied to degraded images, state-of-the-art visual models often suffer performance decline due to the feature content loss and artifact interference caused by statistical and structural properties disruption of captured images. To address this problem, this work proposes a novel Deep Channel Prior (DCP) for degraded visual recognition. Specifically, we observe that, in the deep representation space of pre-trained models, the channel correlations of degraded features with the same degradation type have uniform distribution even if they have different content and semantics, which can facilitate the mapping relationship learning between degraded and clear representations in high-sparsity feature space. Based on this, a novel plug-and-play Unsupervised Feature Enhancement Module (UFEM) is proposed to achieve unsupervised feature correction, where the multi-adversarial mechanism is introduced in the first stage of UFEM to achieve the latent content restoration and artifact removal in high-sparsity feature space. Then, the generated features are transferred to the second stage for global correlation modulation under the guidance of DCP to obtain high-quality and recognition-friendly features. Evaluations of three tasks and eight benchmark datasets demonstrate that our proposed method can comprehensively improve the performance of pre-trained models in real degradation conditions. The source code is available at https://github.com/liyuhang166/Deep_Channel_Prior
Enhancing Traffic Object Detection in Variable Illumination with RGB-Event Fusion
Nov 01, 2023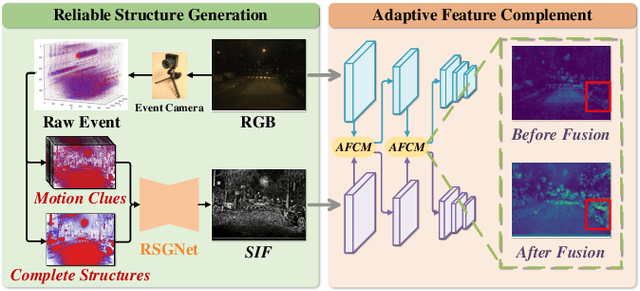

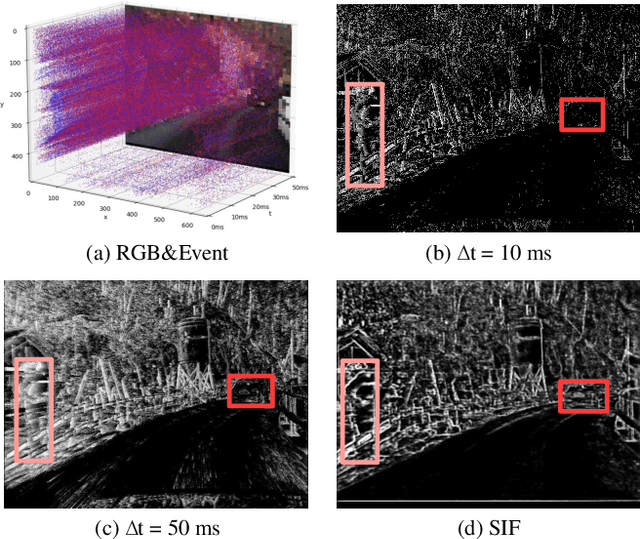
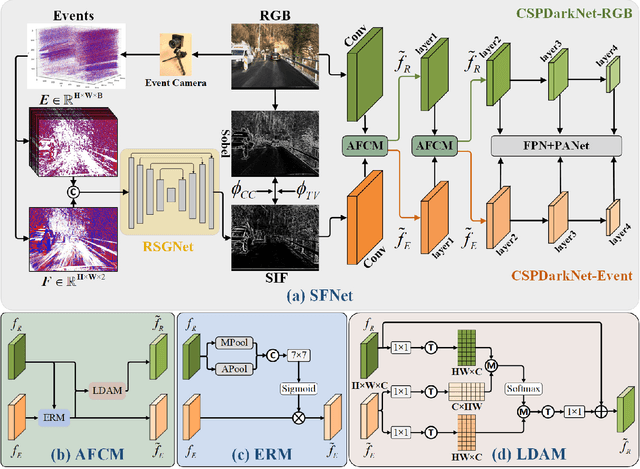
Traffic object detection under variable illumination is challenging due to the information loss caused by the limited dynamic range of conventional frame-based cameras. To address this issue, we introduce bio-inspired event cameras and propose a novel Structure-aware Fusion Network (SFNet) that extracts sharp and complete object structures from the event stream to compensate for the lost information in images through cross-modality fusion, enabling the network to obtain illumination-robust representations for traffic object detection. Specifically, to mitigate the sparsity or blurriness issues arising from diverse motion states of traffic objects in fixed-interval event sampling methods, we propose the Reliable Structure Generation Network (RSGNet) to generate Speed Invariant Frames (SIF), ensuring the integrity and sharpness of object structures. Next, we design a novel Adaptive Feature Complement Module (AFCM) which guides the adaptive fusion of two modality features to compensate for the information loss in the images by perceiving the global lightness distribution of the images, thereby generating illumination-robust representations. Finally, considering the lack of large-scale and high-quality annotations in the existing event-based object detection datasets, we build a DSEC-Det dataset, which consists of 53 sequences with 63,931 images and more than 208,000 labels for 8 classes. Extensive experimental results demonstrate that our proposed SFNet can overcome the perceptual boundaries of conventional cameras and outperform the frame-based method by 8.0% in mAP50 and 5.9% in mAP50:95. Our code and dataset will be available at https://github.com/YN-Yang/SFNet.