 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenzhong Chen
Joint Reference Frame Synthesis and Post Filter Enhancement for Versatile Video Coding
Apr 28, 2024
This paper presents the joint reference frame synthesis (RFS) and post-processing filter enhancement (PFE) for Versatile Video Coding (VVC), aiming to explore the combination of different neural network-based video coding (NNVC) tools to better utilize the hierarchical bi-directional coding structure of VVC. Both RFS and PFE utilize the Space-Time Enhancement Network (STENet), which receives two input frames with artifacts and produces two enhanced frames with suppressed artifacts, along with an intermediate synthesized frame. STENet comprises two pipelines, the synthesis pipeline and the enhancement pipeline, tailored for different purposes. During RFS, two reconstructed frames are sent into STENet's synthesis pipeline to synthesize a virtual reference frame, similar to the current to-be-coded frame. The synthesized frame serves as an additional reference frame inserted into the reference picture list (RPL). During PFE, two reconstructed frames are fed into STENet's enhancement pipeline to alleviate their artifacts and distortions, resulting in enhanced frames with reduced artifacts and distortions. To reduce inference complexity, we propose joint inference of RFS and PFE (JISE), achieved through a single execution of STENet. Integrated into the VVC reference software VTM-15.0, RFS, PFE, and JISE are coordinated within a novel Space-Time Enhancement Window (STEW) under Random Access (RA) configuration. The proposed method could achieve -7.34%/-17.21%/-16.65% PSNR-based BD-rate on average for three components under RA configuration.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
Space-Time Video Super-resolution with Neural Operator
Apr 09, 2024This paper addresses the task of space-time video super-resolution (ST-VSR). Existing methods generally suffer from inaccurate motion estimation and motion compensation (MEMC) problems for large motions. Inspired by recent progress in physics-informed neural networks, we model the challenges of MEMC in ST-VSR as a mapping between two continuous function spaces. Specifically, our approach transforms independent low-resolution representations in the coarse-grained continuous function space into refined representations with enriched spatiotemporal details in the fine-grained continuous function space. To achieve efficient and accurate MEMC, we design a Galerkin-type attention function to perform frame alignment and temporal interpolation. Due to the linear complexity of the Galerkin-type attention mechanism, our model avoids patch partitioning and offers global receptive fields, enabling precise estimation of large motions. The experimental results show that the proposed method surpasses state-of-the-art techniques in both fixed-size and continuous space-time video super-resolution tasks.
SubjectDrive: Scaling Generative Data in Autonomous Driving via Subject Control
Mar 28, 2024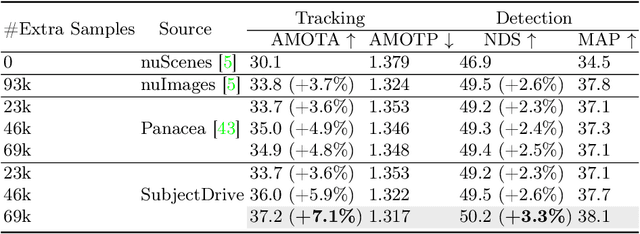
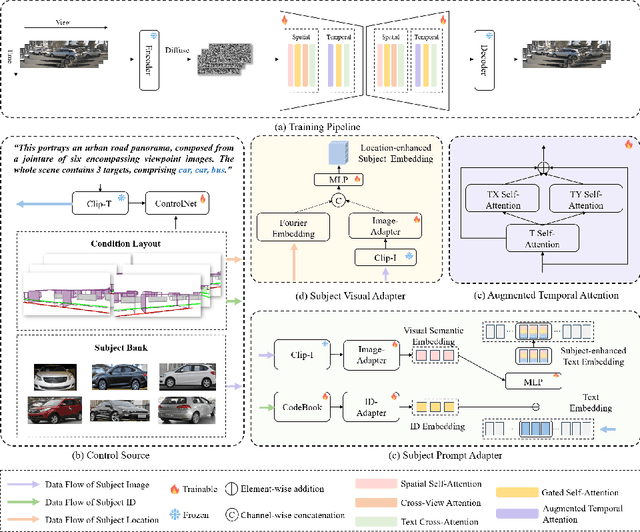
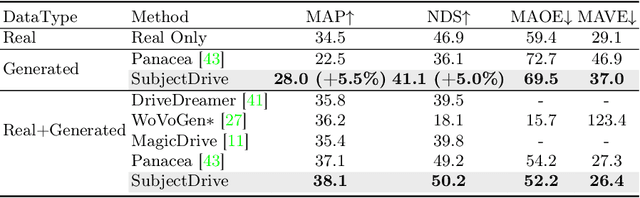

Autonomous driving progress relies on large-scale annotated datasets. In this work, we explore the potential of generative models to produce vast quantities of freely-labeled data for autonomous driving applications and present SubjectDrive, the first model proven to scale generative data production in a way that could continuously improve autonomous driving applications. We investigate the impact of scaling up the quantity of generative data on the performance of downstream perception models and find that enhancing data diversity plays a crucial role in effectively scaling generative data production. Therefore, we have developed a novel model equipped with a subject control mechanism, which allows the generative model to leverage diverse external data sources for producing varied and useful data. Extensive evaluations confirm SubjectDrive's efficacy in generating scalable autonomous driving training data, marking a significant step toward revolutionizing data production methods in this field.
Transferable Learned Image Compression-Resistant Adversarial Perturbations
Jan 06, 2024Adversarial attacks can readily disrupt the image classification system, revealing the vulnerability of DNN-based recognition tasks. While existing adversarial perturbations are primarily applied to uncompressed images or compressed images by the traditional image compression method, i.e., JPEG, limited studies have investigated the robustness of models for image classification in the context of DNN-based image compression. With the rapid evolution of advanced image compression, DNN-based learned image compression has emerged as the promising approach for transmitting images in many security-critical applications, such as cloud-based face recognition and autonomous driving, due to its superior performance over traditional compression. Therefore, there is a pressing need to fully investigate the robustness of a classification system post-processed by learned image compression. To bridge this research gap, we explore the adversarial attack on a new pipeline that targets image classification models that utilize learned image compressors as pre-processing modules. Furthermore, to enhance the transferability of perturbations across various quality levels and architectures of learned image compression models, we introduce a saliency score-based sampling method to enable the fast generation of transferable perturbation. Extensive experiments with popular attack methods demonstrate the enhanced transferability of our proposed method when attacking images that have been post-processed with different learned image compression models.
Corner-to-Center Long-range Context Model for Efficient Learned Image Compression
Nov 29, 2023In the framework of learned image compression, the context model plays a pivotal role in capturing the dependencies among latent representations. To reduce the decoding time resulting from the serial autoregressive context model, the parallel context model has been proposed as an alternative that necessitates only two passes during the decoding phase, thus facilitating efficient image compression in real-world scenarios. However, performance degradation occurs due to its incomplete casual context. To tackle this issue, we conduct an in-depth analysis of the performance degradation observed in existing parallel context models, focusing on two aspects: the Quantity and Quality of information utilized for context prediction and decoding. Based on such analysis, we propose the \textbf{Corner-to-Center transformer-based Context Model (C$^3$M)} designed to enhance context and latent predictions and improve rate-distortion performance. Specifically, we leverage the logarithmic-based prediction order to predict more context features from corner to center progressively. In addition, to enlarge the receptive field in the analysis and synthesis transformation, we use the Long-range Crossing Attention Module (LCAM) in the encoder/decoder to capture the long-range semantic information by assigning the different window shapes in different channels. Extensive experimental evaluations show that the proposed method is effective and outperforms the state-of-the-art parallel methods. Finally, according to the subjective analysis, we suggest that improving the detailed representation in transformer-based image compression is a promising direction to be explored.
UnifiedSSR: A Unified Framework of Sequential Search and Recommendation
Oct 21, 2023
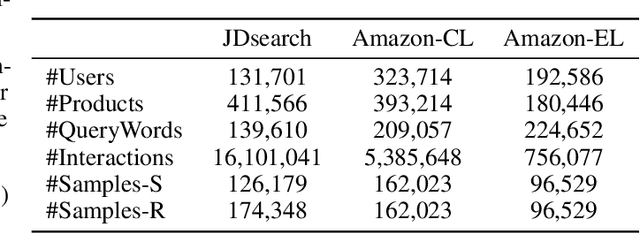
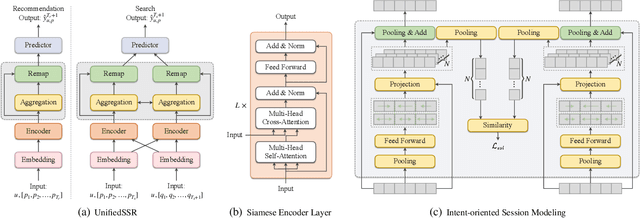
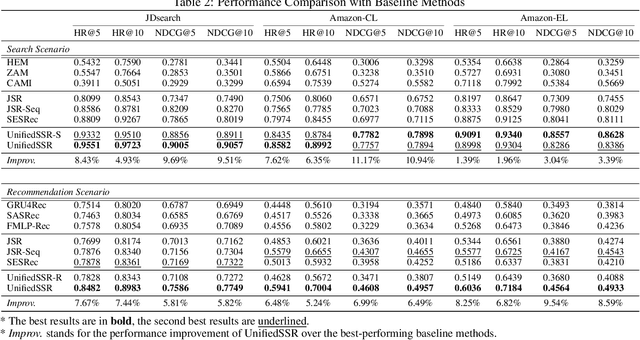
In this work, we propose a Unified framework of Sequential Search and Recommendation (UnifiedSSR) for joint learning of user behavior history in both search and recommendation scenarios. Specifically, we consider user-interacted products in the recommendation scenario, user-interacted products and user-issued queries in the search scenario as three distinct types of user behaviors. We propose a dual-branch network to encode the pair of interacted product history and issued query history in the search scenario in parallel. This allows for cross-scenario modeling by deactivating the query branch for the recommendation scenario. Through the parameter sharing between dual branches, as well as between product branches in two scenarios, we incorporate cross-view and cross-scenario associations of user behaviors, providing a comprehensive understanding of user behavior patterns. To further enhance user behavior modeling by capturing the underlying dynamic intent, an Intent-oriented Session Modeling module is designed for inferring intent-oriented semantic sessions from the contextual information in behavior sequences. In particular, we consider self-supervised learning signals from two perspectives for intent-oriented semantic session locating, which encourage session discrimination within each behavior sequence and session alignment between dual behavior sequences. Extensive experiments on three public datasets demonstrate that UnifiedSSR consistently outperforms state-of-the-art methods for both search and recommendation.
Learning Many-to-Many Mapping for Unpaired Real-World Image Super-resolution and Downscaling
Oct 08, 2023
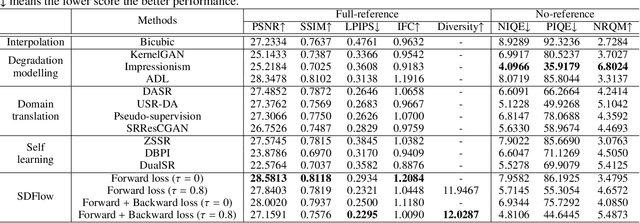

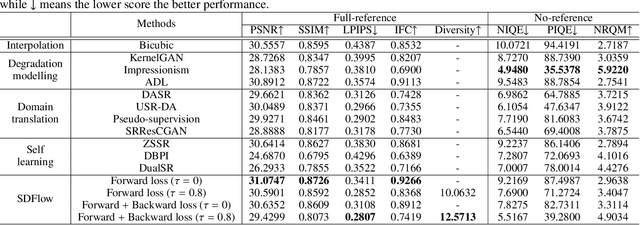
Learning based single image super-resolution (SISR) for real-world images has been an active research topic yet a challenging task, due to the lack of paired low-resolution (LR) and high-resolution (HR) training images. Most of the existing unsupervised real-world SISR methods adopt a two-stage training strategy by synthesizing realistic LR images from their HR counterparts first, then training the super-resolution (SR) models in a supervised manner. However, the training of image degradation and SR models in this strategy are separate, ignoring the inherent mutual dependency between downscaling and its inverse upscaling process. Additionally, the ill-posed nature of image degradation is not fully considered. In this paper, we propose an image downscaling and SR model dubbed as SDFlow, which simultaneously learns a bidirectional many-to-many mapping between real-world LR and HR images unsupervisedly. The main idea of SDFlow is to decouple image content and degradation information in the latent space, where content information distribution of LR and HR images is matched in a common latent space. Degradation information of the LR images and the high-frequency information of the HR images are fitted to an easy-to-sample conditional distribution. Experimental results on real-world image SR datasets indicate that SDFlow can generate diverse realistic LR and SR images both quantitatively and qualitatively.
Dynamic Kernel-Based Adaptive Spatial Aggregation for Learned Image Compression
Aug 17, 2023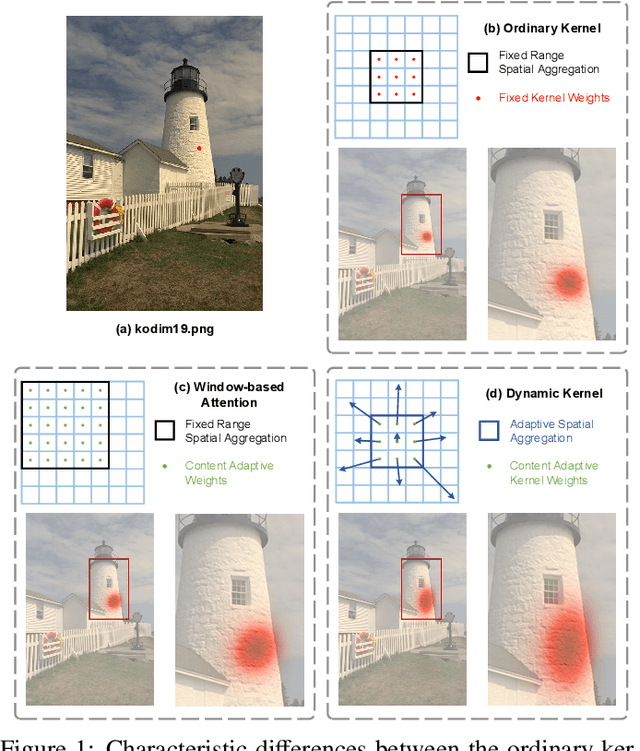
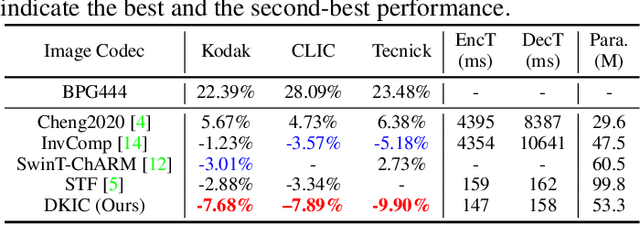
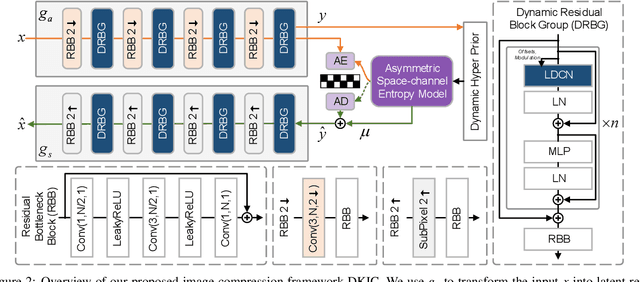
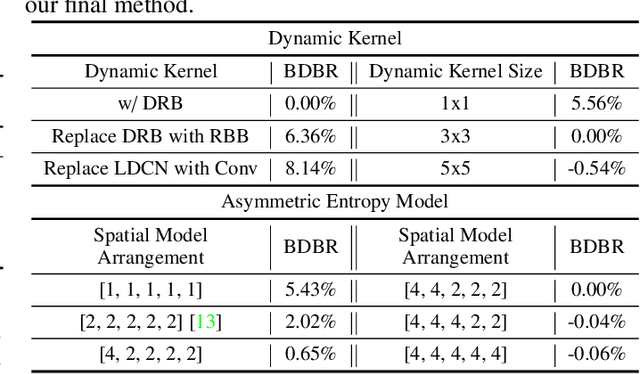
Learned image compression methods have shown superior rate-distortion performance and remarkable potential compared to traditional compression methods. Most existing learned approaches use stacked convolution or window-based self-attention for transform coding, which aggregate spatial information in a fixed range. In this paper, we focus on extending spatial aggregation capability and propose a dynamic kernel-based transform coding. The proposed adaptive aggregation generates kernel offsets to capture valid information in the content-conditioned range to help transform. With the adaptive aggregation strategy and the sharing weights mechanism, our method can achieve promising transform capability with acceptable model complexity. Besides, according to the recent progress of entropy model, we define a generalized coarse-to-fine entropy model, considering the coarse global context, the channel-wise, and the spatial context. Based on it, we introduce dynamic kernel in hyper-prior to generate more expressive global context. Furthermore, we propose an asymmetric spatial-channel entropy model according to the investigation of the spatial characteristics of the grouped latents. The asymmetric entropy model aims to reduce statistical redundancy while maintaining coding efficiency. Experimental results demonstrate that our method achieves superior rate-distortion performance on three benchmarks compared to the state-of-the-art learning-based methods.