 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaohong Liu
Charting the Path Forward: CT Image Quality Assessment -- An In-Depth Review
Apr 30, 2024
Computed Tomography (CT) is a frequently utilized imaging technology that is employed in the clinical diagnosis of many disorders. However, clinical diagnosis, data storage, and management are posed huge challenges by a huge volume of non-homogeneous CT data in terms of imaging quality. As a result, the quality assessment of CT images is a crucial problem that demands consideration. The history, advancements in research, and current developments in CT image quality assessment (IQA) are examined in this paper. In this review, we collected and researched more than 500 CT-IQA publications published before August 2023. And we provide the visualization analysis of keywords and co-citations in the knowledge graph of these papers. Prospects and obstacles for the continued development of CT-IQA are also covered. At present, significant research branches in the CT-IQA domain include Phantom study, Artificial intelligence deep-learning reconstruction algorithm, Dose reduction opportunity, and Virtual monoenergetic reconstruction. Artificial intelligence (AI)-based CT-IQA also becomes a trend. It increases the accuracy of the CT scanning apparatus, amplifies the impact of the CT system reconstruction algorithm, and creates an effective algorithm for post-processing CT images. AI-based medical IQA offers excellent application opportunities in clinical work. AI can provide uniform quality assessment criteria and more comprehensive guidance amongst various healthcare facilities, and encourage them to identify one another's images. It will help lower the number of unnecessary tests and associated costs, and enhance the quality of medical imaging and assessment efficiency.
G-Refine: A General Quality Refiner for Text-to-Image Generation
Apr 29, 2024With the evolution of Text-to-Image (T2I) models, the quality defects of AI-Generated Images (AIGIs) pose a significant barrier to their widespread adoption. In terms of both perception and alignment, existing models cannot always guarantee high-quality results. To mitigate this limitation, we introduce G-Refine, a general image quality refiner designed to enhance low-quality images without compromising the integrity of high-quality ones. The model is composed of three interconnected modules: a perception quality indicator, an alignment quality indicator, and a general quality enhancement module. Based on the mechanisms of the Human Visual System (HVS) and syntax trees, the first two indicators can respectively identify the perception and alignment deficiencies, and the last module can apply targeted quality enhancement accordingly. Extensive experimentation reveals that when compared to alternative optimization methods, AIGIs after G-Refine outperform in 10+ quality metrics across 4 databases. This improvement significantly contributes to the practical application of contemporary T2I models, paving the way for their broader adoption. The code will be released on https://github.com/Q-Future/Q-Refine.
LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM
Apr 28, 2024Although large multi-modality models (LMMs) have seen extensive exploration and application in various quality assessment studies, their integration into Point Cloud Quality Assessment (PCQA) remains unexplored. Given LMMs' exceptional performance and robustness in low-level vision and quality assessment tasks, this study aims to investigate the feasibility of imparting PCQA knowledge to LMMs through text supervision. To achieve this, we transform quality labels into textual descriptions during the fine-tuning phase, enabling LMMs to derive quality rating logits from 2D projections of point clouds. To compensate for the loss of perception in the 3D domain, structural features are extracted as well. These quality logits and structural features are then combined and regressed into quality scores. Our experimental results affirm the effectiveness of our approach, showcasing a novel integration of LMMs into PCQA that enhances model understanding and assessment accuracy. We hope our contributions can inspire subsequent investigations into the fusion of LMMs with PCQA, fostering advancements in 3D visual quality analysis and beyond.
NTIRE 2024 Quality Assessment of AI-Generated Content Challenge
Apr 25, 2024This paper reports on the NTIRE 2024 Quality Assessment of AI-Generated Content Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2024. This challenge is to address a major challenge in the field of image and video processing, namely, Image Quality Assessment (IQA) and Video Quality Assessment (VQA) for AI-Generated Content (AIGC). The challenge is divided into the image track and the video track. The image track uses the AIGIQA-20K, which contains 20,000 AI-Generated Images (AIGIs) generated by 15 popular generative models. The image track has a total of 318 registered participants. A total of 1,646 submissions are received in the development phase, and 221 submissions are received in the test phase. Finally, 16 participating teams submitted their models and fact sheets. The video track uses the T2VQA-DB, which contains 10,000 AI-Generated Videos (AIGVs) generated by 9 popular Text-to-Video (T2V) models. A total of 196 participants have registered in the video track. A total of 991 submissions are received in the development phase, and 185 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. Some methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on AIGC.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
THQA: A Perceptual Quality Assessment Database for Talking Heads
Apr 13, 2024In the realm of media technology, digital humans have gained prominence due to rapid advancements in computer technology. However, the manual modeling and control required for the majority of digital humans pose significant obstacles to efficient development. The speech-driven methods offer a novel avenue for manipulating the mouth shape and expressions of digital humans. Despite the proliferation of driving methods, the quality of many generated talking head (TH) videos remains a concern, impacting user visual experiences. To tackle this issue, this paper introduces the Talking Head Quality Assessment (THQA) database, featuring 800 TH videos generated through 8 diverse speech-driven methods. Extensive experiments affirm the THQA database's richness in character and speech features. Subsequent subjective quality assessment experiments analyze correlations between scoring results and speech-driven methods, ages, and genders. In addition, experimental results show that mainstream image and video quality assessment methods have limitations for the THQA database, underscoring the imperative for further research to enhance TH video quality assessment. The THQA database is publicly accessible at https://github.com/zyj-2000/THQA.
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Apr 10, 2024Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at \url{https://github.com/mulns/PerVFI}
AIGIQA-20K: A Large Database for AI-Generated Image Quality Assessment
Apr 04, 2024With the rapid advancements in AI-Generated Content (AIGC), AI-Generated Images (AIGIs) have been widely applied in entertainment, education, and social media. However, due to the significant variance in quality among different AIGIs, there is an urgent need for models that consistently match human subjective ratings. To address this issue, we organized a challenge towards AIGC quality assessment on NTIRE 2024 that extensively considers 15 popular generative models, utilizing dynamic hyper-parameters (including classifier-free guidance, iteration epochs, and output image resolution), and gather subjective scores that consider perceptual quality and text-to-image alignment altogether comprehensively involving 21 subjects. This approach culminates in the creation of the largest fine-grained AIGI subjective quality database to date with 20,000 AIGIs and 420,000 subjective ratings, known as AIGIQA-20K. Furthermore, we conduct benchmark experiments on this database to assess the correspondence between 16 mainstream AIGI quality models and human perception. We anticipate that this large-scale quality database will inspire robust quality indicators for AIGIs and propel the evolution of AIGC for vision. The database is released on https://www.modelscope.cn/datasets/lcysyzxdxc/AIGCQA-30K-Image.
AIGCOIQA2024: Perceptual Quality Assessment of AI Generated Omnidirectional Images
Apr 01, 2024In recent years, the rapid advancement of Artificial Intelligence Generated Content (AIGC) has attracted widespread attention. Among the AIGC, AI generated omnidirectional images hold significant potential for Virtual Reality (VR) and Augmented Reality (AR) applications, hence omnidirectional AIGC techniques have also been widely studied. AI-generated omnidirectional images exhibit unique distortions compared to natural omnidirectional images, however, there is no dedicated Image Quality Assessment (IQA) criteria for assessing them. This study addresses this gap by establishing a large-scale AI generated omnidirectional image IQA database named AIGCOIQA2024 and constructing a comprehensive benchmark. We first generate 300 omnidirectional images based on 5 AIGC models utilizing 25 text prompts. A subjective IQA experiment is conducted subsequently to assess human visual preferences from three perspectives including quality, comfortability, and correspondence. Finally, we conduct a benchmark experiment to evaluate the performance of state-of-the-art IQA models on our database. The database will be released to facilitate future research.
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Mar 28, 2024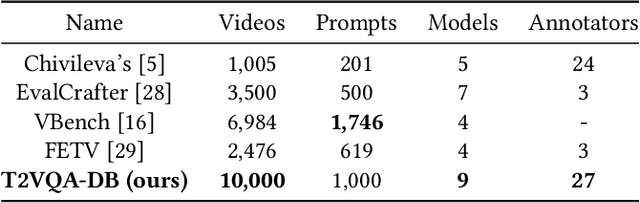

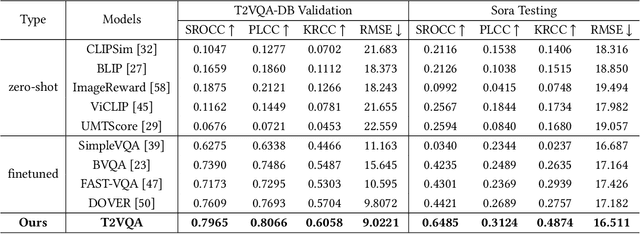
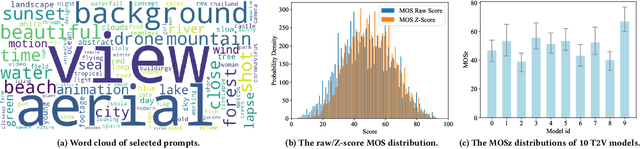
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.