 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Tao
UNIAA: A Unified Multi-modal Image Aesthetic Assessment Baseline and Benchmark
Apr 15, 2024
As an alternative to expensive expert evaluation, Image Aesthetic Assessment (IAA) stands out as a crucial task in computer vision. However, traditional IAA methods are typically constrained to a single data source or task, restricting the universality and broader application. In this work, to better align with human aesthetics, we propose a Unified Multi-modal Image Aesthetic Assessment (UNIAA) framework, including a Multi-modal Large Language Model (MLLM) named UNIAA-LLaVA and a comprehensive benchmark named UNIAA-Bench. We choose MLLMs with both visual perception and language ability for IAA and establish a low-cost paradigm for transforming the existing datasets into unified and high-quality visual instruction tuning data, from which the UNIAA-LLaVA is trained. To further evaluate the IAA capability of MLLMs, we construct the UNIAA-Bench, which consists of three aesthetic levels: Perception, Description, and Assessment. Extensive experiments validate the effectiveness and rationality of UNIAA. UNIAA-LLaVA achieves competitive performance on all levels of UNIAA-Bench, compared with existing MLLMs. Specifically, our model performs better than GPT-4V in aesthetic perception and even approaches the junior-level human. We find MLLMs have great potential in IAA, yet there remains plenty of room for further improvement. The UNIAA-LLaVA and UNIAA-Bench will be released.
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Apr 10, 2024Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at \url{https://github.com/mulns/PerVFI}
Motion Inversion for Video Customization
Mar 29, 2024In this research, we present a novel approach to motion customization in video generation, addressing the widespread gap in the thorough exploration of motion representation within video generative models. Recognizing the unique challenges posed by video's spatiotemporal nature, our method introduces Motion Embeddings, a set of explicit, temporally coherent one-dimensional embeddings derived from a given video. These embeddings are designed to integrate seamlessly with the temporal transformer modules of video diffusion models, modulating self-attention computations across frames without compromising spatial integrity. Our approach offers a compact and efficient solution to motion representation and enables complex manipulations of motion characteristics through vector arithmetic in the embedding space. Furthermore, we identify the Temporal Discrepancy in video generative models, which refers to variations in how different motion modules process temporal relationships between frames. We leverage this understanding to optimize the integration of our motion embeddings. Our contributions include the introduction of a tailored motion embedding for customization tasks, insights into the temporal processing differences in video models, and a demonstration of the practical advantages and effectiveness of our method through extensive experiments.
DVIS++: Improved Decoupled Framework for Universal Video Segmentation
Dec 20, 2023We present the \textbf{D}ecoupled \textbf{VI}deo \textbf{S}egmentation (DVIS) framework, a novel approach for the challenging task of universal video segmentation, including video instance segmentation (VIS), video semantic segmentation (VSS), and video panoptic segmentation (VPS). Unlike previous methods that model video segmentation in an end-to-end manner, our approach decouples video segmentation into three cascaded sub-tasks: segmentation, tracking, and refinement. This decoupling design allows for simpler and more effective modeling of the spatio-temporal representations of objects, especially in complex scenes and long videos. Accordingly, we introduce two novel components: the referring tracker and the temporal refiner. These components track objects frame by frame and model spatio-temporal representations based on pre-aligned features. To improve the tracking capability of DVIS, we propose a denoising training strategy and introduce contrastive learning, resulting in a more robust framework named DVIS++. Furthermore, we evaluate DVIS++ in various settings, including open vocabulary and using a frozen pre-trained backbone. By integrating CLIP with DVIS++, we present OV-DVIS++, the first open-vocabulary universal video segmentation framework. We conduct extensive experiments on six mainstream benchmarks, including the VIS, VSS, and VPS datasets. Using a unified architecture, DVIS++ significantly outperforms state-of-the-art specialized methods on these benchmarks in both close- and open-vocabulary settings. Code:~\url{https://github.com/zhang-tao-whu/DVIS_Plus}.
Stable Segment Anything Model
Dec 05, 2023The Segment Anything Model (SAM) achieves remarkable promptable segmentation given high-quality prompts which, however, often require good skills to specify. To make SAM robust to casual prompts, this paper presents the first comprehensive analysis on SAM's segmentation stability across a diverse spectrum of prompt qualities, notably imprecise bounding boxes and insufficient points. Our key finding reveals that given such low-quality prompts, SAM's mask decoder tends to activate image features that are biased towards the background or confined to specific object parts. To mitigate this issue, our key idea consists of calibrating solely SAM's mask attention by adjusting the sampling locations and amplitudes of image features, while the original SAM model architecture and weights remain unchanged. Consequently, our deformable sampling plugin (DSP) enables SAM to adaptively shift attention to the prompted target regions in a data-driven manner, facilitated by our effective robust training strategy (RTS). During inference, dynamic routing plugin (DRP) is proposed that toggles SAM between the deformable and regular grid sampling modes, conditioned on the input prompt quality. Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0.08 M) and fast adaptation (by 1 training epoch). Extensive experiments across multiple datasets validate the effectiveness and advantages of our approach, underscoring Stable-SAM as a more robust solution for segmenting anything. Codes will be released upon acceptance. https://github.com/fanq15/Stable-SAM
1st Place Solution for the 5th LSVOS Challenge: Video Instance Segmentation
Aug 28, 2023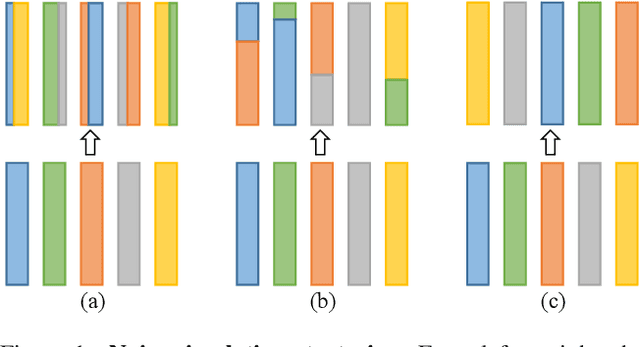
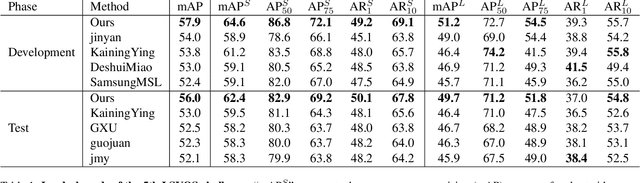
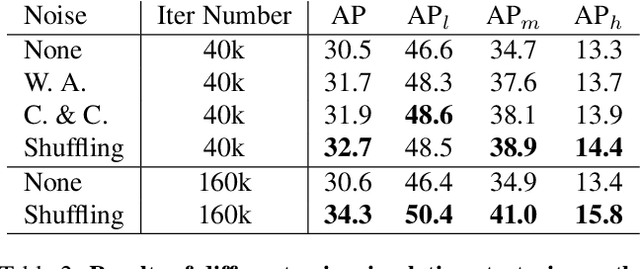
Video instance segmentation is a challenging task that serves as the cornerstone of numerous downstream applications, including video editing and autonomous driving. In this report, we present further improvements to the SOTA VIS method, DVIS. First, we introduce a denoising training strategy for the trainable tracker, allowing it to achieve more stable and accurate object tracking in complex and long videos. Additionally, we explore the role of visual foundation models in video instance segmentation. By utilizing a frozen VIT-L model pre-trained by DINO v2, DVIS demonstrates remarkable performance improvements. With these enhancements, our method achieves 57.9 AP and 56.0 AP in the development and test phases, respectively, and ultimately ranked 1st in the VIS track of the 5th LSVOS Challenge. The code will be available at https://github.com/zhang-tao-whu/DVIS.
Scene-Generalizable Interactive Segmentation of Radiance Fields
Aug 09, 2023
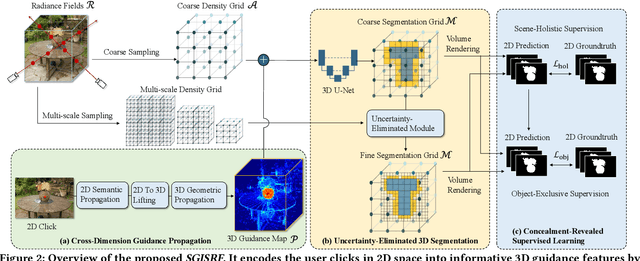
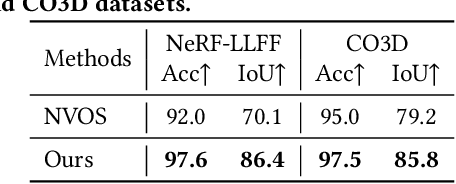
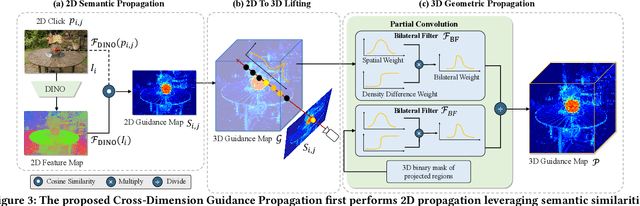
Existing methods for interactive segmentation in radiance fields entail scene-specific optimization and thus cannot generalize across different scenes, which greatly limits their applicability. In this work we make the first attempt at Scene-Generalizable Interactive Segmentation in Radiance Fields (SGISRF) and propose a novel SGISRF method, which can perform 3D object segmentation for novel (unseen) scenes represented by radiance fields, guided by only a few interactive user clicks in a given set of multi-view 2D images. In particular, the proposed SGISRF focuses on addressing three crucial challenges with three specially designed techniques. First, we devise the Cross-Dimension Guidance Propagation to encode the scarce 2D user clicks into informative 3D guidance representations. Second, the Uncertainty-Eliminated 3D Segmentation module is designed to achieve efficient yet effective 3D segmentation. Third, Concealment-Revealed Supervised Learning scheme is proposed to reveal and correct the concealed 3D segmentation errors resulted from the supervision in 2D space with only 2D mask annotations. Extensive experiments on two real-world challenging benchmarks covering diverse scenes demonstrate 1) effectiveness and scene-generalizability of the proposed method, 2) favorable performance compared to classical method requiring scene-specific optimization.
Feature Decoupling-Recycling Network for Fast Interactive Segmentation
Aug 08, 2023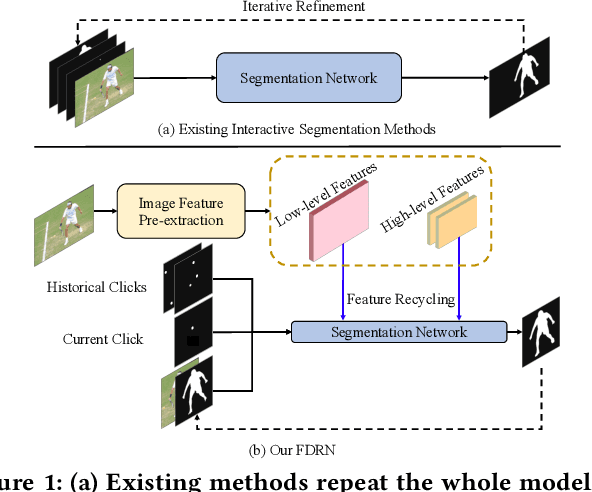
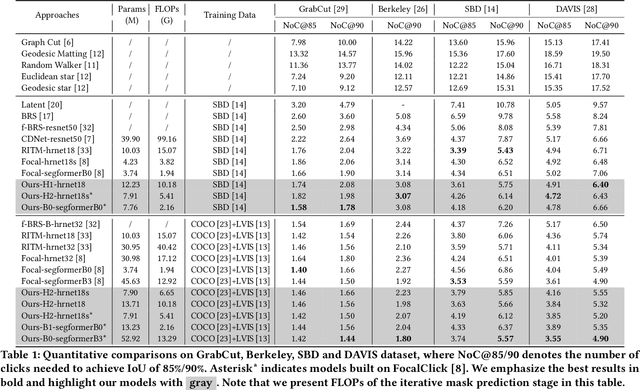
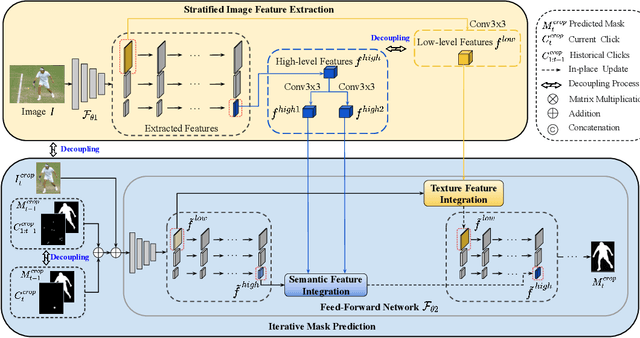
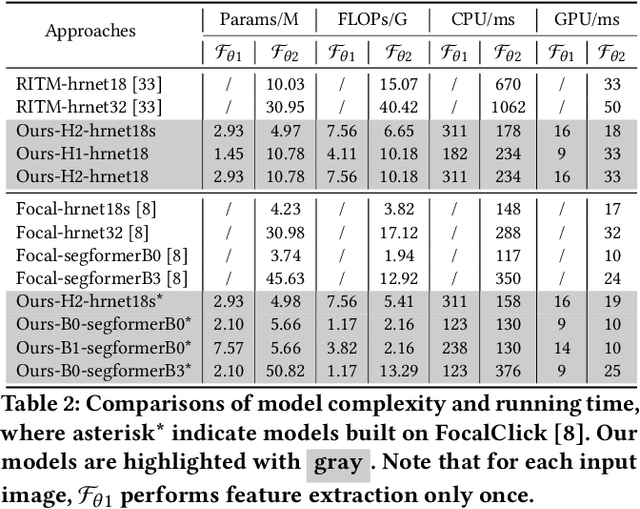
Recent interactive segmentation methods iteratively take source image, user guidance and previously predicted mask as the input without considering the invariant nature of the source image. As a result, extracting features from the source image is repeated in each interaction, resulting in substantial computational redundancy. In this work, we propose the Feature Decoupling-Recycling Network (FDRN), which decouples the modeling components based on their intrinsic discrepancies and then recycles components for each user interaction. Thus, the efficiency of the whole interactive process can be significantly improved. To be specific, we apply the Decoupling-Recycling strategy from three perspectives to address three types of discrepancies, respectively. First, our model decouples the learning of source image semantics from the encoding of user guidance to process two types of input domains separately. Second, FDRN decouples high-level and low-level features from stratified semantic representations to enhance feature learning. Third, during the encoding of user guidance, current user guidance is decoupled from historical guidance to highlight the effect of current user guidance. We conduct extensive experiments on 6 datasets from different domains and modalities, which demonstrate the following merits of our model: 1) superior efficiency than other methods, particularly advantageous in challenging scenarios requiring long-term interactions (up to 4.25x faster), while achieving favorable segmentation performance; 2) strong applicability to various methods serving as a universal enhancement technique; 3) well cross-task generalizability, e.g., to medical image segmentation, and robustness against misleading user guidance.