 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu-Wing Tai
FED-NeRF: Achieve High 3D Consistency and Temporal Coherence for Face Video Editing on Dynamic NeRF
Jan 05, 2024
The success of the GAN-NeRF structure has enabled face editing on NeRF to maintain 3D view consistency. However, achieving simultaneously multi-view consistency and temporal coherence while editing video sequences remains a formidable challenge. This paper proposes a novel face video editing architecture built upon the dynamic face GAN-NeRF structure, which effectively utilizes video sequences to restore the latent code and 3D face geometry. By editing the latent code, multi-view consistent editing on the face can be ensured, as validated by multiview stereo reconstruction on the resulting edited images in our dynamic NeRF. As the estimation of face geometries occurs on a frame-by-frame basis, this may introduce a jittering issue. We propose a stabilizer that maintains temporal coherence by preserving smooth changes of face expressions in consecutive frames. Quantitative and qualitative analyses reveal that our method, as the pioneering 4D face video editor, achieves state-of-the-art performance in comparison to existing 2D or 3D-based approaches independently addressing identity and motion. Codes will be released.
Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
Dec 30, 2023Current Neural Radiance Fields (NeRF) can generate photorealistic novel views. For editing 3D scenes represented by NeRF, with the advent of generative models, this paper proposes Inpaint4DNeRF to capitalize on state-of-the-art stable diffusion models (e.g., ControlNet) for direct generation of the underlying completed background content, regardless of static or dynamic. The key advantages of this generative approach for NeRF inpainting are twofold. First, after rough mask propagation, to complete or fill in previously occluded content, we can individually generate a small subset of completed images with plausible content, called seed images, from which simple 3D geometry proxies can be derived. Second and the remaining problem is thus 3D multiview consistency among all completed images, now guided by the seed images and their 3D proxies. Without other bells and whistles, our generative Inpaint4DNeRF baseline framework is general which can be readily extended to 4D dynamic NeRFs, where temporal consistency can be naturally handled in a similar way as our multiview consistency.
Stable Segment Anything Model
Dec 05, 2023The Segment Anything Model (SAM) achieves remarkable promptable segmentation given high-quality prompts which, however, often require good skills to specify. To make SAM robust to casual prompts, this paper presents the first comprehensive analysis on SAM's segmentation stability across a diverse spectrum of prompt qualities, notably imprecise bounding boxes and insufficient points. Our key finding reveals that given such low-quality prompts, SAM's mask decoder tends to activate image features that are biased towards the background or confined to specific object parts. To mitigate this issue, our key idea consists of calibrating solely SAM's mask attention by adjusting the sampling locations and amplitudes of image features, while the original SAM model architecture and weights remain unchanged. Consequently, our deformable sampling plugin (DSP) enables SAM to adaptively shift attention to the prompted target regions in a data-driven manner, facilitated by our effective robust training strategy (RTS). During inference, dynamic routing plugin (DRP) is proposed that toggles SAM between the deformable and regular grid sampling modes, conditioned on the input prompt quality. Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0.08 M) and fast adaptation (by 1 training epoch). Extensive experiments across multiple datasets validate the effectiveness and advantages of our approach, underscoring Stable-SAM as a more robust solution for segmenting anything. Codes will be released upon acceptance. https://github.com/fanq15/Stable-SAM
Prompt2NeRF-PIL: Fast NeRF Generation via Pretrained Implicit Latent
Dec 05, 2023This paper explores promptable NeRF generation (e.g., text prompt or single image prompt) for direct conditioning and fast generation of NeRF parameters for the underlying 3D scenes, thus undoing complex intermediate steps while providing full 3D generation with conditional control. Unlike previous diffusion-CLIP-based pipelines that involve tedious per-prompt optimizations, Prompt2NeRF-PIL is capable of generating a variety of 3D objects with a single forward pass, leveraging a pre-trained implicit latent space of NeRF parameters. Furthermore, in zero-shot tasks, our experiments demonstrate that the NeRFs produced by our method serve as semantically informative initializations, significantly accelerating the inference process of existing prompt-to-NeRF methods. Specifically, we will show that our approach speeds up the text-to-NeRF model DreamFusion and the 3D reconstruction speed of the image-to-NeRF method Zero-1-to-3 by 3 to 5 times.
SANeRF-HQ: Segment Anything for NeRF in High Quality
Dec 03, 2023Recently, the Segment Anything Model (SAM) has showcased remarkable capabilities of zero-shot segmentation, while NeRF (Neural Radiance Fields) has gained popularity as a method for various 3D problems beyond novel view synthesis. Though there exist initial attempts to incorporate these two methods into 3D segmentation, they face the challenge of accurately and consistently segmenting objects in complex scenarios. In this paper, we introduce the Segment Anything for NeRF in High Quality (SANeRF-HQ) to achieve high quality 3D segmentation of any object in a given scene. SANeRF-HQ utilizes SAM for open-world object segmentation guided by user-supplied prompts, while leveraging NeRF to aggregate information from different viewpoints. To overcome the aforementioned challenges, we employ density field and RGB similarity to enhance the accuracy of segmentation boundary during the aggregation. Emphasizing on segmentation accuracy, we evaluate our method quantitatively on multiple NeRF datasets where high-quality ground-truths are available or manually annotated. SANeRF-HQ shows a significant quality improvement over previous state-of-the-art methods in NeRF object segmentation, provides higher flexibility for object localization, and enables more consistent object segmentation across multiple views. Additional information can be found at https://lyclyc52.github.io/SANeRF-HQ/.
DragVideo: Interactive Drag-style Video Editing
Dec 03, 2023Editing visual content on videos remains a formidable challenge with two main issues: 1) direct and easy user control to produce 2) natural editing results without unsightly distortion and artifacts after changing shape, expression and layout. Inspired by DragGAN, a recent image-based drag-style editing technique, we address above issues by proposing DragVideo, where a similar drag-style user interaction is adopted to edit video content while maintaining temporal consistency. Empowered by recent diffusion models as in DragDiffusion, DragVideo contains the novel Drag-on-Video U-Net (DoVe) editing method, which optimizes diffused video latents generated by video U-Net to achieve the desired control. Specifically, we use Sample-specific LoRA fine-tuning and Mutual Self-Attention control to ensure faithful reconstruction of video from the DoVe method. We also present a series of testing examples for drag-style video editing and conduct extensive experiments across a wide array of challenging editing tasks, such as motion editing, skeleton editing, etc, underscoring DragVideo's versatility and generality. Our codes including the DragVideo web user interface will be released.
C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Nov 29, 2023We present Compound Conditioned ControlNet, C3Net, a novel generative neural architecture taking conditions from multiple modalities and synthesizing multimodal contents simultaneously (e.g., image, text, audio). C3Net adapts the ControlNet architecture to jointly train and make inferences on a production-ready diffusion model and its trainable copies. Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training. Then, it generates multimodal outputs based on the aligned latent space, whose semantic information is combined using a ControlNet-like architecture called Control C3-UNet. Correspondingly, with this system design, our model offers an improved solution for joint-modality generation through learning and explaining multimodal conditions instead of simply taking linear interpolations on the latent space. Meanwhile, as we align conditions to a unified latent space, C3Net only requires one trainable Control C3-UNet to work on multimodal semantic information. Furthermore, our model employs unimodal pretraining on the condition alignment stage, outperforming the non-pretrained alignment even on relatively scarce training data and thus demonstrating high-quality compound condition generation. We contribute the first high-quality tri-modal validation set to validate quantitatively that C3Net outperforms or is on par with first and contemporary state-of-the-art multimodal generation. Our codes and tri-modal dataset will be released.
Deceptive-Human: Prompt-to-NeRF 3D Human Generation with 3D-Consistent Synthetic Images
Nov 27, 2023This paper presents Deceptive-Human, a novel Prompt-to-NeRF framework capitalizing state-of-the-art control diffusion models (e.g., ControlNet) to generate a high-quality controllable 3D human NeRF. Different from direct 3D generative approaches, e.g., DreamFusion and DreamHuman, Deceptive-Human employs a progressive refinement technique to elevate the reconstruction quality. This is achieved by utilizing high-quality synthetic human images generated through the ControlNet with view-consistent loss. Our method is versatile and readily extensible, accommodating multimodal inputs, including a text prompt and additional data such as 3D mesh, poses, and seed images. The resulting 3D human NeRF model empowers the synthesis of highly photorealistic novel views from 360-degree perspectives. The key to our Deceptive-Human for hallucinating multi-view consistent synthetic human images lies in our progressive finetuning strategy. This strategy involves iteratively enhancing views using the provided multimodal inputs at each intermediate step to improve the human NeRF model. Within this iterative refinement process, view-dependent appearances are systematically eliminated to prevent interference with the underlying density estimation. Extensive qualitative and quantitative experimental comparison shows that our deceptive human models achieve state-of-the-art application quality.
EgoPCA: A New Framework for Egocentric Hand-Object Interaction Understanding
Sep 05, 2023
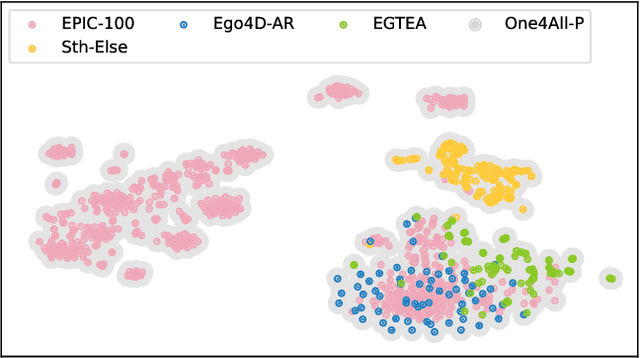
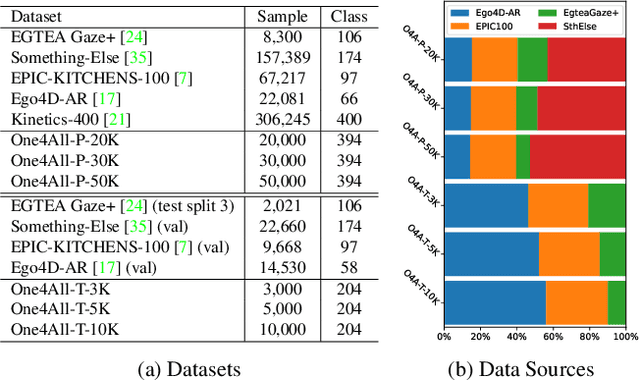
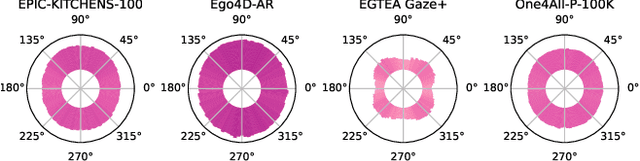
With the surge in attention to Egocentric Hand-Object Interaction (Ego-HOI), large-scale datasets such as Ego4D and EPIC-KITCHENS have been proposed. However, most current research is built on resources derived from third-person video action recognition. This inherent domain gap between first- and third-person action videos, which have not been adequately addressed before, makes current Ego-HOI suboptimal. This paper rethinks and proposes a new framework as an infrastructure to advance Ego-HOI recognition by Probing, Curation and Adaption (EgoPCA). We contribute comprehensive pre-train sets, balanced test sets and a new baseline, which are complete with a training-finetuning strategy. With our new framework, we not only achieve state-of-the-art performance on Ego-HOI benchmarks but also build several new and effective mechanisms and settings to advance further research. We believe our data and the findings will pave a new way for Ego-HOI understanding. Code and data are available at https://mvig-rhos.com/ego_pca