 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuimin Zeng
Open-Vocabulary Federated Learning with Multimodal Prototyping
Apr 02, 2024
Existing federated learning (FL) studies usually assume the training label space and test label space are identical. However, in real-world applications, this assumption is too ideal to be true. A new user could come up with queries that involve data from unseen classes, and such open-vocabulary queries would directly defect such FL systems. Therefore, in this work, we explicitly focus on the under-explored open-vocabulary challenge in FL. That is, for a new user, the global server shall understand her/his query that involves arbitrary unknown classes. To address this problem, we leverage the pre-trained vision-language models (VLMs). In particular, we present a novel adaptation framework tailored for VLMs in the context of FL, named as Federated Multimodal Prototyping (Fed-MP). Fed-MP adaptively aggregates the local model weights based on light-weight client residuals, and makes predictions based on a novel multimodal prototyping mechanism. Fed-MP exploits the knowledge learned from the seen classes, and robustifies the adapted VLM to unseen categories. Our empirical evaluation on various datasets validates the effectiveness of Fed-MP.
Evidence-Driven Retrieval Augmented Response Generation for Online Misinformation
Mar 22, 2024The proliferation of online misinformation has posed significant threats to public interest. While numerous online users actively participate in the combat against misinformation, many of such responses can be characterized by the lack of politeness and supporting facts. As a solution, text generation approaches are proposed to automatically produce counter-misinformation responses. Nevertheless, existing methods are often trained end-to-end without leveraging external knowledge, resulting in subpar text quality and excessively repetitive responses. In this paper, we propose retrieval augmented response generation for online misinformation (RARG), which collects supporting evidence from scientific sources and generates counter-misinformation responses based on the evidences. In particular, our RARG consists of two stages: (1) evidence collection, where we design a retrieval pipeline to retrieve and rerank evidence documents using a database comprising over 1M academic articles; (2) response generation, in which we align large language models (LLMs) to generate evidence-based responses via reinforcement learning from human feedback (RLHF). We propose a reward function to maximize the utilization of the retrieved evidence while maintaining the quality of the generated text, which yields polite and factual responses that clearly refutes misinformation. To demonstrate the effectiveness of our method, we study the case of COVID-19 and perform extensive experiments with both in- and cross-domain datasets, where RARG consistently outperforms baselines by generating high-quality counter-misinformation responses.
Federated Recommendation via Hybrid Retrieval Augmented Generation
Mar 07, 2024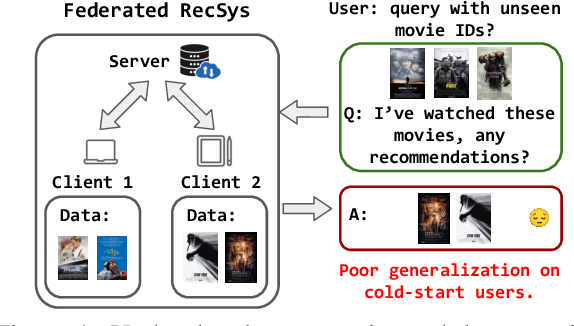
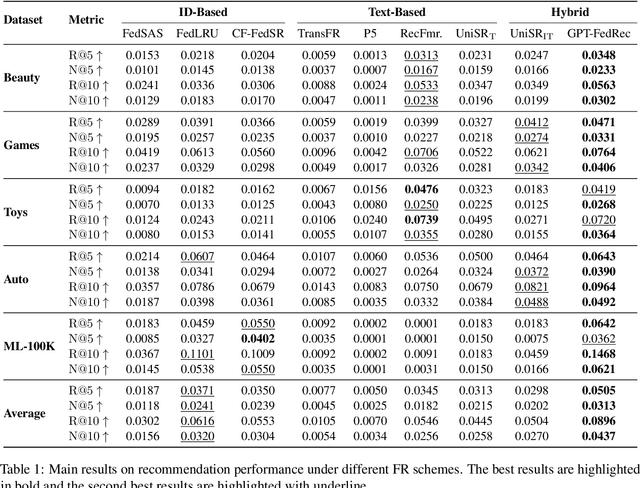
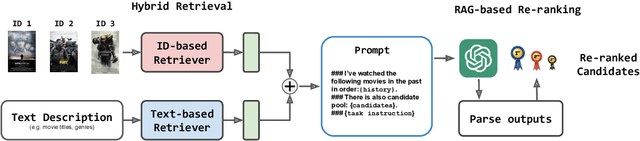
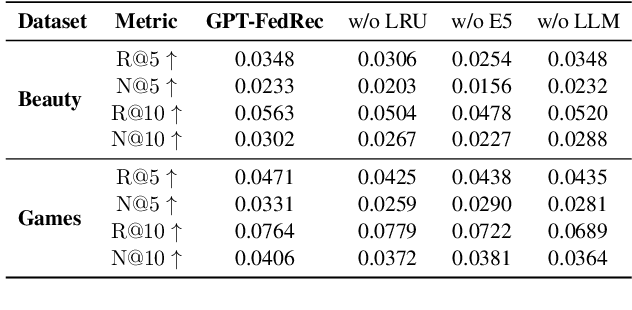
Federated Recommendation (FR) emerges as a novel paradigm that enables privacy-preserving recommendations. However, traditional FR systems usually represent users/items with discrete identities (IDs), suffering from performance degradation due to the data sparsity and heterogeneity in FR. On the other hand, Large Language Models (LLMs) as recommenders have proven effective across various recommendation scenarios. Yet, LLM-based recommenders encounter challenges such as low inference efficiency and potential hallucination, compromising their performance in real-world scenarios. To this end, we propose GPT-FedRec, a federated recommendation framework leveraging ChatGPT and a novel hybrid Retrieval Augmented Generation (RAG) mechanism. GPT-FedRec is a two-stage solution. The first stage is a hybrid retrieval process, mining ID-based user patterns and text-based item features. Next, the retrieved results are converted into text prompts and fed into GPT for re-ranking. Our proposed hybrid retrieval mechanism and LLM-based re-rank aims to extract generalized features from data and exploit pretrained knowledge within LLM, overcoming data sparsity and heterogeneity in FR. In addition, the RAG approach also prevents LLM hallucination, improving the recommendation performance for real-world users. Experimental results on diverse benchmark datasets demonstrate the superior performance of GPT-FedRec against state-of-the-art baseline methods.
Exploring Boundary of GPT-4V on Marine Analysis: A Preliminary Case Study
Jan 04, 2024Large language models (LLMs) have demonstrated a powerful ability to answer various queries as a general-purpose assistant. The continuous multi-modal large language models (MLLM) empower LLMs with the ability to perceive visual signals. The launch of GPT-4 (Generative Pre-trained Transformers) has generated significant interest in the research communities. GPT-4V(ison) has demonstrated significant power in both academia and industry fields, as a focal point in a new artificial intelligence generation. Though significant success was achieved by GPT-4V, exploring MLLMs in domain-specific analysis (e.g., marine analysis) that required domain-specific knowledge and expertise has gained less attention. In this study, we carry out the preliminary and comprehensive case study of utilizing GPT-4V for marine analysis. This report conducts a systematic evaluation of existing GPT-4V, assessing the performance of GPT-4V on marine research and also setting a new standard for future developments in MLLMs. The experimental results of GPT-4V show that the responses generated by GPT-4V are still far away from satisfying the domain-specific requirements of the marine professions. All images and prompts used in this study will be available at https://github.com/hkust-vgd/Marine_GPT-4V_Eval
Linear Recurrent Units for Sequential Recommendation
Oct 03, 2023



State-of-the-art sequential recommendation relies heavily on self-attention-based recommender models. Yet such models are computationally expensive and often too slow for real-time recommendation. Furthermore, the self-attention operation is performed at a sequence-level, thereby making low-cost incremental inference challenging. Inspired by recent advances in efficient language modeling, we propose linear recurrent units for sequential recommendation (LRURec). Similar to recurrent neural networks, LRURec offers rapid inference and can achieve incremental inference on sequential inputs. By decomposing the linear recurrence operation and designing recursive parallelization in our framework, LRURec provides the additional benefits of reduced model size and parallelizable training. Moreover, we optimize the architecture of LRURec by implementing a series of modifications to address the lack of non-linearity and improve training dynamics. To validate the effectiveness of our proposed LRURec, we conduct extensive experiments on multiple real-world datasets and compare its performance against state-of-the-art sequential recommenders. Experimental results demonstrate the effectiveness of LRURec, which consistently outperforms baselines by a significant margin. Results also highlight the efficiency of LRURec with our parallelized training paradigm and fast inference on long sequences, showing its potential to further enhance user experience in sequential recommendation.
Feature Decoupling-Recycling Network for Fast Interactive Segmentation
Aug 08, 2023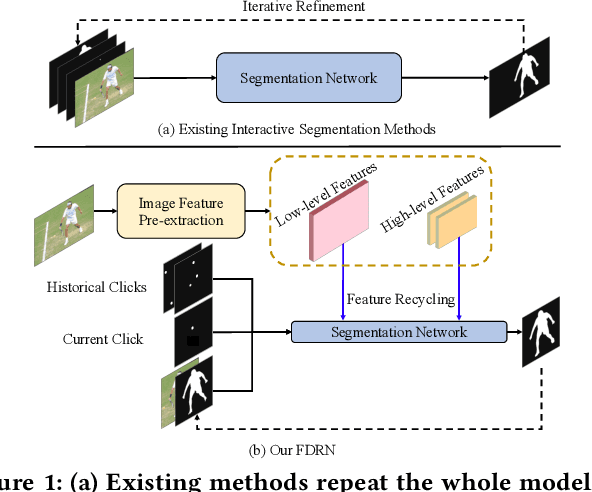
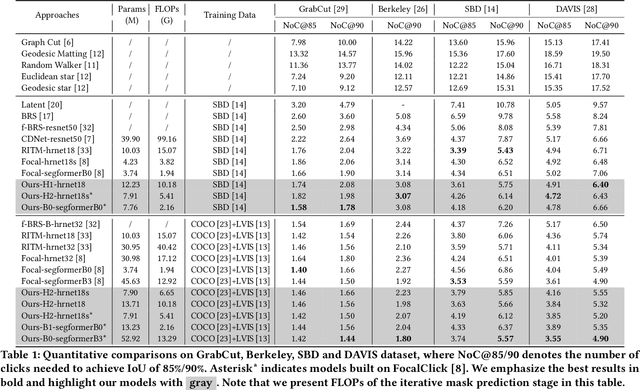
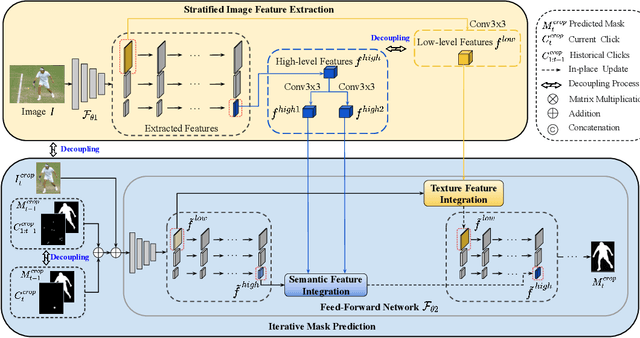
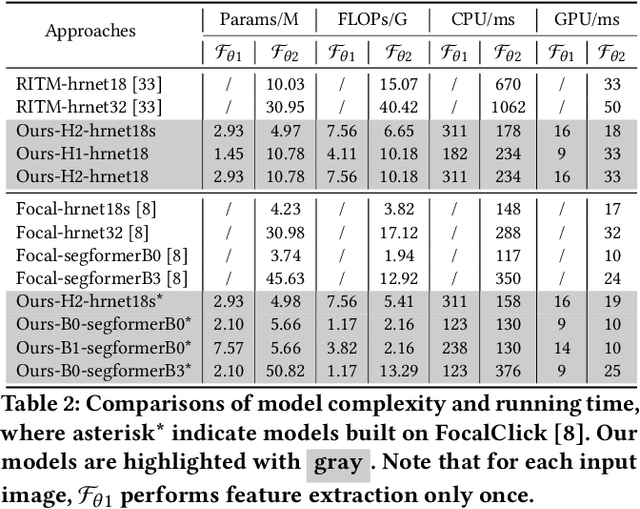
Recent interactive segmentation methods iteratively take source image, user guidance and previously predicted mask as the input without considering the invariant nature of the source image. As a result, extracting features from the source image is repeated in each interaction, resulting in substantial computational redundancy. In this work, we propose the Feature Decoupling-Recycling Network (FDRN), which decouples the modeling components based on their intrinsic discrepancies and then recycles components for each user interaction. Thus, the efficiency of the whole interactive process can be significantly improved. To be specific, we apply the Decoupling-Recycling strategy from three perspectives to address three types of discrepancies, respectively. First, our model decouples the learning of source image semantics from the encoding of user guidance to process two types of input domains separately. Second, FDRN decouples high-level and low-level features from stratified semantic representations to enhance feature learning. Third, during the encoding of user guidance, current user guidance is decoupled from historical guidance to highlight the effect of current user guidance. We conduct extensive experiments on 6 datasets from different domains and modalities, which demonstrate the following merits of our model: 1) superior efficiency than other methods, particularly advantageous in challenging scenarios requiring long-term interactions (up to 4.25x faster), while achieving favorable segmentation performance; 2) strong applicability to various methods serving as a universal enhancement technique; 3) well cross-task generalizability, e.g., to medical image segmentation, and robustness against misleading user guidance.
Zero- and Few-Shot Event Detection via Prompt-Based Meta Learning
May 27, 2023



With emerging online topics as a source for numerous new events, detecting unseen / rare event types presents an elusive challenge for existing event detection methods, where only limited data access is provided for training. To address the data scarcity problem in event detection, we propose MetaEvent, a meta learning-based framework for zero- and few-shot event detection. Specifically, we sample training tasks from existing event types and perform meta training to search for optimal parameters that quickly adapt to unseen tasks. In our framework, we propose to use the cloze-based prompt and a trigger-aware soft verbalizer to efficiently project output to unseen event types. Moreover, we design a contrastive meta objective based on maximum mean discrepancy (MMD) to learn class-separating features. As such, the proposed MetaEvent can perform zero-shot event detection by mapping features to event types without any prior knowledge. In our experiments, we demonstrate the effectiveness of MetaEvent in both zero-shot and few-shot scenarios, where the proposed method achieves state-of-the-art performance in extensive experiments on benchmark datasets FewEvent and MAVEN.
MetaAdapt: Domain Adaptive Few-Shot Misinformation Detection via Meta Learning
May 22, 2023



With emerging topics (e.g., COVID-19) on social media as a source for the spreading misinformation, overcoming the distributional shifts between the original training domain (i.e., source domain) and such target domains remains a non-trivial task for misinformation detection. This presents an elusive challenge for early-stage misinformation detection, where a good amount of data and annotations from the target domain is not available for training. To address the data scarcity issue, we propose MetaAdapt, a meta learning based approach for domain adaptive few-shot misinformation detection. MetaAdapt leverages limited target examples to provide feedback and guide the knowledge transfer from the source to the target domain (i.e., learn to adapt). In particular, we train the initial model with multiple source tasks and compute their similarity scores to the meta task. Based on the similarity scores, we rescale the meta gradients to adaptively learn from the source tasks. As such, MetaAdapt can learn how to adapt the misinformation detection model and exploit the source data for improved performance in the target domain. To demonstrate the efficiency and effectiveness of our method, we perform extensive experiments to compare MetaAdapt with state-of-the-art baselines and large language models (LLMs) such as LLaMA, where MetaAdapt achieves better performance in domain adaptive few-shot misinformation detection with substantially reduced parameters on real-world datasets.
Region-Aware Portrait Retouching with Sparse Interactive Guidance
Apr 24, 2023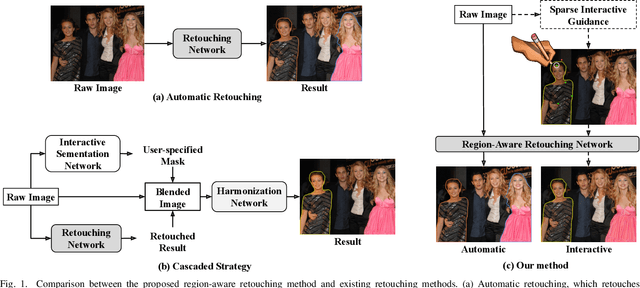


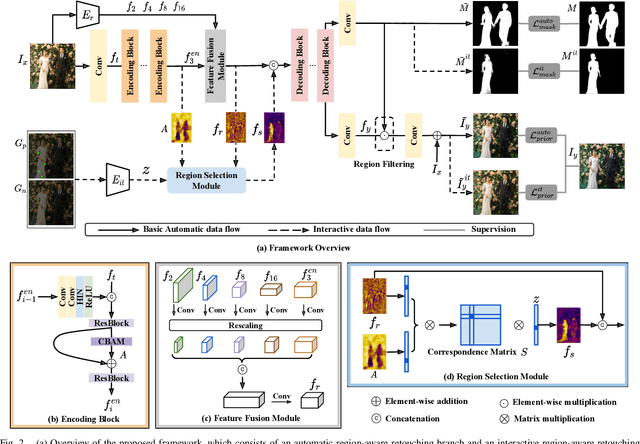
Portrait retouching aims to improve the aesthetic quality of input portrait photos and especially requires human-region priority. The deep learning-based methods largely elevate the retouching efficiency and provide promising retouched results. However, existing portrait retouching methods focus on automatic retouching, which treats all human-regions equally and ignores users' preferences for specific individuals, thus suffering from limited flexibility in interactive scenarios. In this work, we emphasize the importance of users' intents and explore the interactive portrait retouching task. Specifically, we propose a region-aware retouching framework with two branches: an automatic branch and an interactive branch. The automatic branch involves an encoding-decoding process, which searches region candidates and performs automatic region-aware retouching without user guidance. The interactive branch encodes sparse user guidance into a priority condition vector and modulates latent features with a region selection module to further emphasize the user-specified regions. Experimental results show that our interactive branch effectively captures users' intents and generalizes well to unseen scenes with sparse user guidance, while our automatic branch also outperforms the state-of-the-art retouching methods due to improved region-awareness.
QA Domain Adaptation using Hidden Space Augmentation and Self-Supervised Contrastive Adaptation
Oct 19, 2022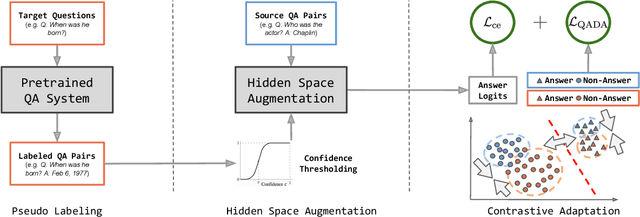
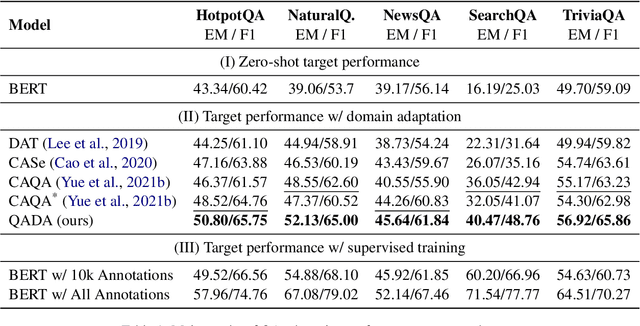
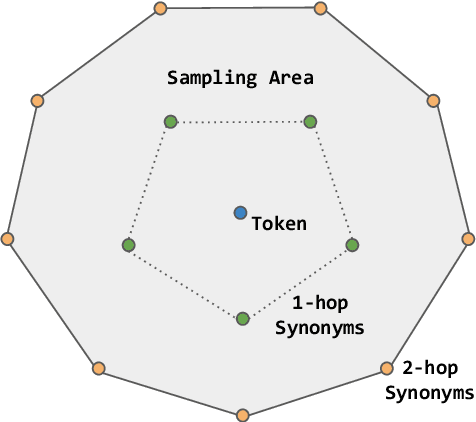
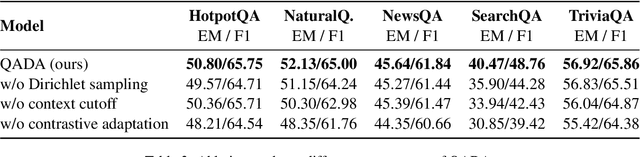
Question answering (QA) has recently shown impressive results for answering questions from customized domains. Yet, a common challenge is to adapt QA models to an unseen target domain. In this paper, we propose a novel self-supervised framework called QADA for QA domain adaptation. QADA introduces a novel data augmentation pipeline used to augment training QA samples. Different from existing methods, we enrich the samples via hidden space augmentation. For questions, we introduce multi-hop synonyms and sample augmented token embeddings with Dirichlet distributions. For contexts, we develop an augmentation method which learns to drop context spans via a custom attentive sampling strategy. Additionally, contrastive learning is integrated in the proposed self-supervised adaptation framework QADA. Unlike existing approaches, we generate pseudo labels and propose to train the model via a novel attention-based contrastive adaptation method. The attention weights are used to build informative features for discrepancy estimation that helps the QA model separate answers and generalize across source and target domains. To the best of our knowledge, our work is the first to leverage hidden space augmentation and attention-based contrastive adaptation for self-supervised domain adaptation in QA. Our evaluation shows that QADA achieves considerable improvements on multiple target datasets over state-of-the-art baselines in QA domain adaptation.