 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunyi Li
G-Refine: A General Quality Refiner for Text-to-Image Generation
Apr 29, 2024
With the evolution of Text-to-Image (T2I) models, the quality defects of AI-Generated Images (AIGIs) pose a significant barrier to their widespread adoption. In terms of both perception and alignment, existing models cannot always guarantee high-quality results. To mitigate this limitation, we introduce G-Refine, a general image quality refiner designed to enhance low-quality images without compromising the integrity of high-quality ones. The model is composed of three interconnected modules: a perception quality indicator, an alignment quality indicator, and a general quality enhancement module. Based on the mechanisms of the Human Visual System (HVS) and syntax trees, the first two indicators can respectively identify the perception and alignment deficiencies, and the last module can apply targeted quality enhancement accordingly. Extensive experimentation reveals that when compared to alternative optimization methods, AIGIs after G-Refine outperform in 10+ quality metrics across 4 databases. This improvement significantly contributes to the practical application of contemporary T2I models, paving the way for their broader adoption. The code will be released on https://github.com/Q-Future/Q-Refine.
LMM-PCQA: Assisting Point Cloud Quality Assessment with LMM
Apr 28, 2024Although large multi-modality models (LMMs) have seen extensive exploration and application in various quality assessment studies, their integration into Point Cloud Quality Assessment (PCQA) remains unexplored. Given LMMs' exceptional performance and robustness in low-level vision and quality assessment tasks, this study aims to investigate the feasibility of imparting PCQA knowledge to LMMs through text supervision. To achieve this, we transform quality labels into textual descriptions during the fine-tuning phase, enabling LMMs to derive quality rating logits from 2D projections of point clouds. To compensate for the loss of perception in the 3D domain, structural features are extracted as well. These quality logits and structural features are then combined and regressed into quality scores. Our experimental results affirm the effectiveness of our approach, showcasing a novel integration of LMMs into PCQA that enhances model understanding and assessment accuracy. We hope our contributions can inspire subsequent investigations into the fusion of LMMs with PCQA, fostering advancements in 3D visual quality analysis and beyond.
NTIRE 2024 Quality Assessment of AI-Generated Content Challenge
Apr 25, 2024This paper reports on the NTIRE 2024 Quality Assessment of AI-Generated Content Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2024. This challenge is to address a major challenge in the field of image and video processing, namely, Image Quality Assessment (IQA) and Video Quality Assessment (VQA) for AI-Generated Content (AIGC). The challenge is divided into the image track and the video track. The image track uses the AIGIQA-20K, which contains 20,000 AI-Generated Images (AIGIs) generated by 15 popular generative models. The image track has a total of 318 registered participants. A total of 1,646 submissions are received in the development phase, and 221 submissions are received in the test phase. Finally, 16 participating teams submitted their models and fact sheets. The video track uses the T2VQA-DB, which contains 10,000 AI-Generated Videos (AIGVs) generated by 9 popular Text-to-Video (T2V) models. A total of 196 participants have registered in the video track. A total of 991 submissions are received in the development phase, and 185 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. Some methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on AIGC.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
AIGIQA-20K: A Large Database for AI-Generated Image Quality Assessment
Apr 04, 2024With the rapid advancements in AI-Generated Content (AIGC), AI-Generated Images (AIGIs) have been widely applied in entertainment, education, and social media. However, due to the significant variance in quality among different AIGIs, there is an urgent need for models that consistently match human subjective ratings. To address this issue, we organized a challenge towards AIGC quality assessment on NTIRE 2024 that extensively considers 15 popular generative models, utilizing dynamic hyper-parameters (including classifier-free guidance, iteration epochs, and output image resolution), and gather subjective scores that consider perceptual quality and text-to-image alignment altogether comprehensively involving 21 subjects. This approach culminates in the creation of the largest fine-grained AIGI subjective quality database to date with 20,000 AIGIs and 420,000 subjective ratings, known as AIGIQA-20K. Furthermore, we conduct benchmark experiments on this database to assess the correspondence between 16 mainstream AIGI quality models and human perception. We anticipate that this large-scale quality database will inspire robust quality indicators for AIGIs and propel the evolution of AIGC for vision. The database is released on https://www.modelscope.cn/datasets/lcysyzxdxc/AIGCQA-30K-Image.
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Mar 28, 2024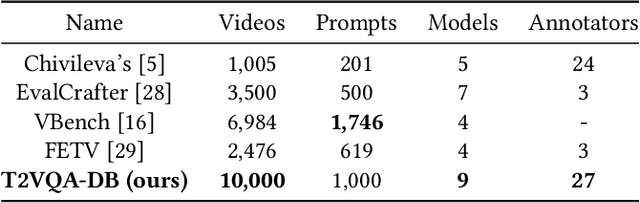

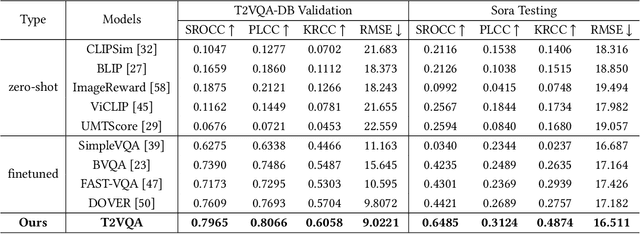
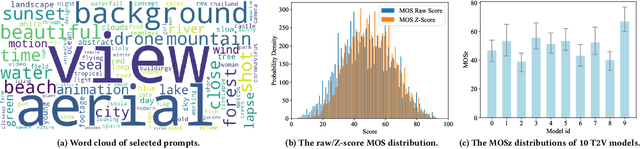
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
Towards Open-ended Visual Quality Comparison
Mar 04, 2024Comparative settings (e.g. pairwise choice, listwise ranking) have been adopted by a wide range of subjective studies for image quality assessment (IQA), as it inherently standardizes the evaluation criteria across different observers and offer more clear-cut responses. In this work, we extend the edge of emerging large multi-modality models (LMMs) to further advance visual quality comparison into open-ended settings, that 1) can respond to open-range questions on quality comparison; 2) can provide detailed reasonings beyond direct answers. To this end, we propose the Co-Instruct. To train this first-of-its-kind open-source open-ended visual quality comparer, we collect the Co-Instruct-562K dataset, from two sources: (a) LLM-merged single image quality description, (b) GPT-4V "teacher" responses on unlabeled data. Furthermore, to better evaluate this setting, we propose the MICBench, the first benchmark on multi-image comparison for LMMs. We demonstrate that Co-Instruct not only achieves in average 30% higher accuracy than state-of-the-art open-source LMMs, but also outperforms GPT-4V (its teacher), on both existing related benchmarks and the proposed MICBench. Our model is published at https://huggingface.co/q-future/co-instruct.
MISC: Ultra-low Bitrate Image Semantic Compression Driven by Large Multimodal Model
Feb 29, 2024With the evolution of storage and communication protocols, ultra-low bitrate image compression has become a highly demanding topic. However, existing compression algorithms must sacrifice either consistency with the ground truth or perceptual quality at ultra-low bitrate. In recent years, the rapid development of the Large Multimodal Model (LMM) has made it possible to balance these two goals. To solve this problem, this paper proposes a method called Multimodal Image Semantic Compression (MISC), which consists of an LMM encoder for extracting the semantic information of the image, a map encoder to locate the region corresponding to the semantic, an image encoder generates an extremely compressed bitstream, and a decoder reconstructs the image based on the above information. Experimental results show that our proposed MISC is suitable for compressing both traditional Natural Sense Images (NSIs) and emerging AI-Generated Images (AIGIs) content. It can achieve optimal consistency and perception results while saving 50% bitrate, which has strong potential applications in the next generation of storage and communication. The code will be released on https://github.com/lcysyzxdxc/MISC.
Q-Refine: A Perceptual Quality Refiner for AI-Generated Image
Jan 02, 2024With the rapid evolution of the Text-to-Image (T2I) model in recent years, their unsatisfactory generation result has become a challenge. However, uniformly refining AI-Generated Images (AIGIs) of different qualities not only limited optimization capabilities for low-quality AIGIs but also brought negative optimization to high-quality AIGIs. To address this issue, a quality-award refiner named Q-Refine is proposed. Based on the preference of the Human Visual System (HVS), Q-Refine uses the Image Quality Assessment (IQA) metric to guide the refining process for the first time, and modify images of different qualities through three adaptive pipelines. Experimental shows that for mainstream T2I models, Q-Refine can perform effective optimization to AIGIs of different qualities. It can be a general refiner to optimize AIGIs from both fidelity and aesthetic quality levels, thus expanding the application of the T2I generation models.
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Dec 28, 2023The explosion of visual content available online underscores the requirement for an accurate machine assessor to robustly evaluate scores across diverse types of visual contents. While recent studies have demonstrated the exceptional potentials of large multi-modality models (LMMs) on a wide range of related fields, in this work, we explore how to teach them for visual rating aligned with human opinions. Observing that human raters only learn and judge discrete text-defined levels in subjective studies, we propose to emulate this subjective process and teach LMMs with text-defined rating levels instead of scores. The proposed Q-Align achieves state-of-the-art performance on image quality assessment (IQA), image aesthetic assessment (IAA), as well as video quality assessment (VQA) tasks under the original LMM structure. With the syllabus, we further unify the three tasks into one model, termed the OneAlign. In our experiments, we demonstrate the advantage of the discrete-level-based syllabus over direct-score-based variants for LMMs. Our code and the pre-trained weights are released at https://github.com/Q-Future/Q-Align.