 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Sui
DisDet: Exploring Detectability of Backdoor Attack on Diffusion Models
Feb 05, 2024
In the exciting generative AI era, the diffusion model has emerged as a very powerful and widely adopted content generation and editing tool for various data modalities, making the study of their potential security risks very necessary and critical. Very recently, some pioneering works have shown the vulnerability of the diffusion model against backdoor attacks, calling for in-depth analysis and investigation of the security challenges of this popular and fundamental AI technique. In this paper, for the first time, we systematically explore the detectability of the poisoned noise input for the backdoored diffusion models, an important performance metric yet little explored in the existing works. Starting from the perspective of a defender, we first analyze the properties of the trigger pattern in the existing diffusion backdoor attacks, discovering the important role of distribution discrepancy in Trojan detection. Based on this finding, we propose a low-cost trigger detection mechanism that can effectively identify the poisoned input noise. We then take a further step to study the same problem from the attack side, proposing a backdoor attack strategy that can learn the unnoticeable trigger to evade our proposed detection scheme. Empirical evaluations across various diffusion models and datasets demonstrate the effectiveness of the proposed trigger detection and detection-evading attack strategy. For trigger detection, our distribution discrepancy-based solution can achieve a 100\% detection rate for the Trojan triggers used in the existing works. For evading trigger detection, our proposed stealthy trigger design approach performs end-to-end learning to make the distribution of poisoned noise input approach that of benign noise, enabling nearly 100\% detection pass rate with very high attack and benign performance for the backdoored diffusion models.
ELRT: Efficient Low-Rank Training for Compact Convolutional Neural Networks
Jan 18, 2024Low-rank compression, a popular model compression technique that produces compact convolutional neural networks (CNNs) with low rankness, has been well-studied in the literature. On the other hand, low-rank training, as an alternative way to train low-rank CNNs from scratch, has been exploited little yet. Unlike low-rank compression, low-rank training does not need pre-trained full-rank models, and the entire training phase is always performed on the low-rank structure, bringing attractive benefits for practical applications. However, the existing low-rank training solutions still face several challenges, such as a considerable accuracy drop and/or still needing to update full-size models during the training. In this paper, we perform a systematic investigation on low-rank CNN training. By identifying the proper low-rank format and performance-improving strategy, we propose ELRT, an efficient low-rank training solution for high-accuracy, high-compactness, low-rank CNN models. Our extensive evaluation results for training various CNNs on different datasets demonstrate the effectiveness of ELRT.
Transferable Learned Image Compression-Resistant Adversarial Perturbations
Jan 06, 2024Adversarial attacks can readily disrupt the image classification system, revealing the vulnerability of DNN-based recognition tasks. While existing adversarial perturbations are primarily applied to uncompressed images or compressed images by the traditional image compression method, i.e., JPEG, limited studies have investigated the robustness of models for image classification in the context of DNN-based image compression. With the rapid evolution of advanced image compression, DNN-based learned image compression has emerged as the promising approach for transmitting images in many security-critical applications, such as cloud-based face recognition and autonomous driving, due to its superior performance over traditional compression. Therefore, there is a pressing need to fully investigate the robustness of a classification system post-processed by learned image compression. To bridge this research gap, we explore the adversarial attack on a new pipeline that targets image classification models that utilize learned image compressors as pre-processing modules. Furthermore, to enhance the transferability of perturbations across various quality levels and architectures of learned image compression models, we introduce a saliency score-based sampling method to enable the fast generation of transferable perturbation. Extensive experiments with popular attack methods demonstrate the enhanced transferability of our proposed method when attacking images that have been post-processed with different learned image compression models.
In-Sensor Radio Frequency Computing for Energy-Efficient Intelligent Radar
Dec 16, 2023Radio Frequency Neural Networks (RFNNs) have demonstrated advantages in realizing intelligent applications across various domains. However, as the model size of deep neural networks rapidly increases, implementing large-scale RFNN in practice requires an extensive number of RF interferometers and consumes a substantial amount of energy. To address this challenge, we propose to utilize low-rank decomposition to transform a large-scale RFNN into a compact RFNN while almost preserving its accuracy. Specifically, we develop a Tensor-Train RFNN (TT-RFNN) where each layer comprises a sequence of low-rank third-order tensors, leading to a notable reduction in parameter count, thereby optimizing RF interferometer utilization in comparison to the original large-scale RFNN. Additionally, considering the inherent physical errors when mapping TT-RFNN to RF device parameters in real-world deployment, from a general perspective, we construct the Robust TT-RFNN (RTT-RFNN) by incorporating a robustness solver on TT-RFNN to enhance its robustness. To adapt the RTT-RFNN to varying requirements of reshaping operations, we further provide a reconfigurable reshaping solution employing RF switch matrices. Empirical evaluations conducted on MNIST and CIFAR-10 datasets show the effectiveness of our proposed method.
Corner-to-Center Long-range Context Model for Efficient Learned Image Compression
Nov 29, 2023In the framework of learned image compression, the context model plays a pivotal role in capturing the dependencies among latent representations. To reduce the decoding time resulting from the serial autoregressive context model, the parallel context model has been proposed as an alternative that necessitates only two passes during the decoding phase, thus facilitating efficient image compression in real-world scenarios. However, performance degradation occurs due to its incomplete casual context. To tackle this issue, we conduct an in-depth analysis of the performance degradation observed in existing parallel context models, focusing on two aspects: the Quantity and Quality of information utilized for context prediction and decoding. Based on such analysis, we propose the \textbf{Corner-to-Center transformer-based Context Model (C$^3$M)} designed to enhance context and latent predictions and improve rate-distortion performance. Specifically, we leverage the logarithmic-based prediction order to predict more context features from corner to center progressively. In addition, to enlarge the receptive field in the analysis and synthesis transformation, we use the Long-range Crossing Attention Module (LCAM) in the encoder/decoder to capture the long-range semantic information by assigning the different window shapes in different channels. Extensive experimental evaluations show that the proposed method is effective and outperforms the state-of-the-art parallel methods. Finally, according to the subjective analysis, we suggest that improving the detailed representation in transformer-based image compression is a promising direction to be explored.
Reconstruction Distortion of Learned Image Compression with Imperceptible Perturbations
Jun 01, 2023
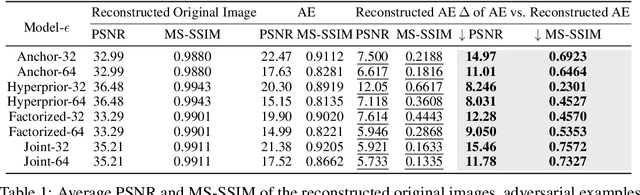

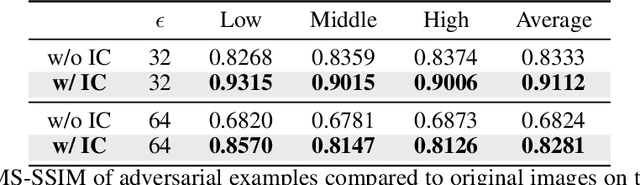
Learned Image Compression (LIC) has recently become the trending technique for image transmission due to its notable performance. Despite its popularity, the robustness of LIC with respect to the quality of image reconstruction remains under-explored. In this paper, we introduce an imperceptible attack approach designed to effectively degrade the reconstruction quality of LIC, resulting in the reconstructed image being severely disrupted by noise where any object in the reconstructed images is virtually impossible. More specifically, we generate adversarial examples by introducing a Frobenius norm-based loss function to maximize the discrepancy between original images and reconstructed adversarial examples. Further, leveraging the insensitivity of high-frequency components to human vision, we introduce Imperceptibility Constraint (IC) to ensure that the perturbations remain inconspicuous. Experiments conducted on the Kodak dataset using various LIC models demonstrate effectiveness. In addition, we provide several findings and suggestions for designing future defenses.
HALOC: Hardware-Aware Automatic Low-Rank Compression for Compact Neural Networks
Jan 20, 2023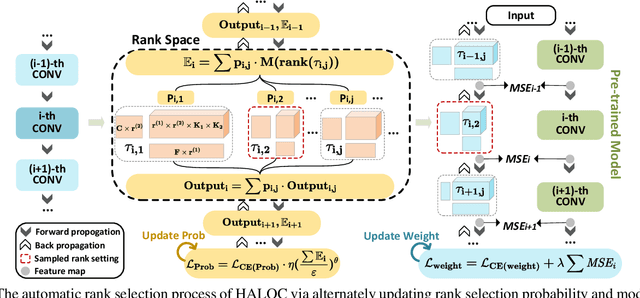
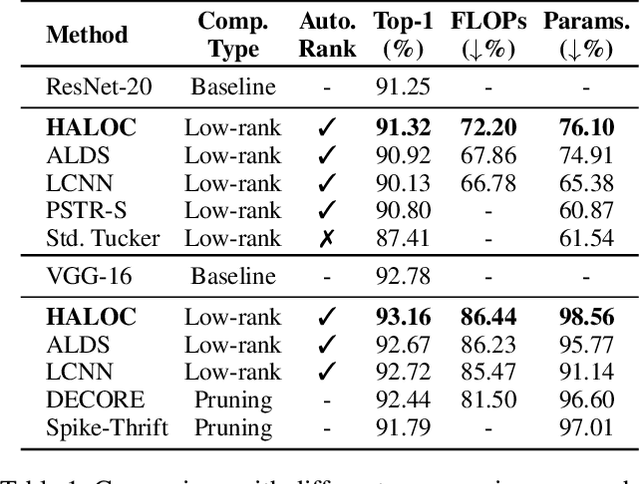
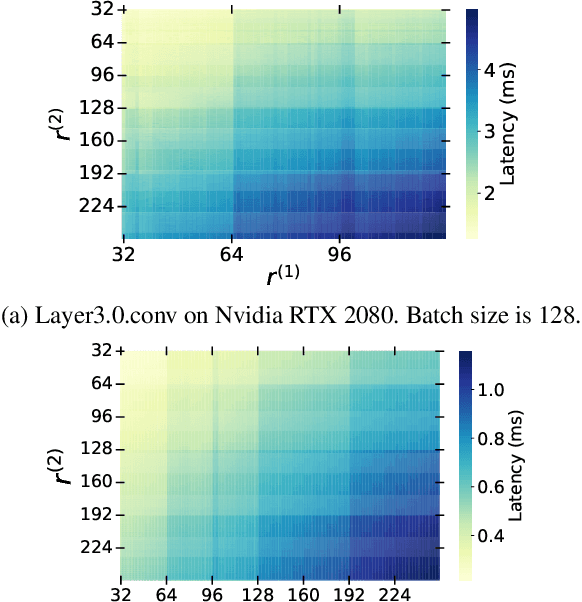
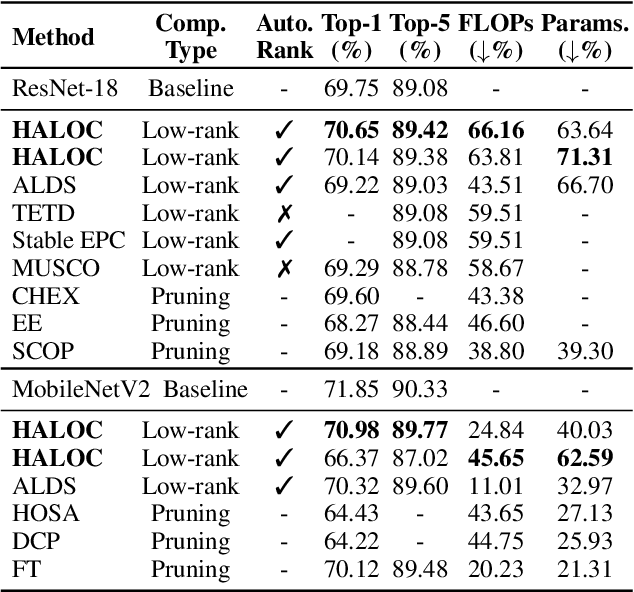
Low-rank compression is an important model compression strategy for obtaining compact neural network models. In general, because the rank values directly determine the model complexity and model accuracy, proper selection of layer-wise rank is very critical and desired. To date, though many low-rank compression approaches, either selecting the ranks in a manual or automatic way, have been proposed, they suffer from costly manual trials or unsatisfied compression performance. In addition, all of the existing works are not designed in a hardware-aware way, limiting the practical performance of the compressed models on real-world hardware platforms. To address these challenges, in this paper we propose HALOC, a hardware-aware automatic low-rank compression framework. By interpreting automatic rank selection from an architecture search perspective, we develop an end-to-end solution to determine the suitable layer-wise ranks in a differentiable and hardware-aware way. We further propose design principles and mitigation strategy to efficiently explore the rank space and reduce the potential interference problem. Experimental results on different datasets and hardware platforms demonstrate the effectiveness of our proposed approach. On CIFAR-10 dataset, HALOC enables 0.07% and 0.38% accuracy increase over the uncompressed ResNet-20 and VGG-16 models with 72.20% and 86.44% fewer FLOPs, respectively. On ImageNet dataset, HALOC achieves 0.9% higher top-1 accuracy than the original ResNet-18 model with 66.16% fewer FLOPs. HALOC also shows 0.66% higher top-1 accuracy increase than the state-of-the-art automatic low-rank compression solution with fewer computational and memory costs. In addition, HALOC demonstrates the practical speedups on different hardware platforms, verified by the measurement results on desktop GPU, embedded GPU and ASIC accelerator.
Algorithm and Hardware Co-Design of Energy-Efficient LSTM Networks for Video Recognition with Hierarchical Tucker Tensor Decomposition
Dec 05, 2022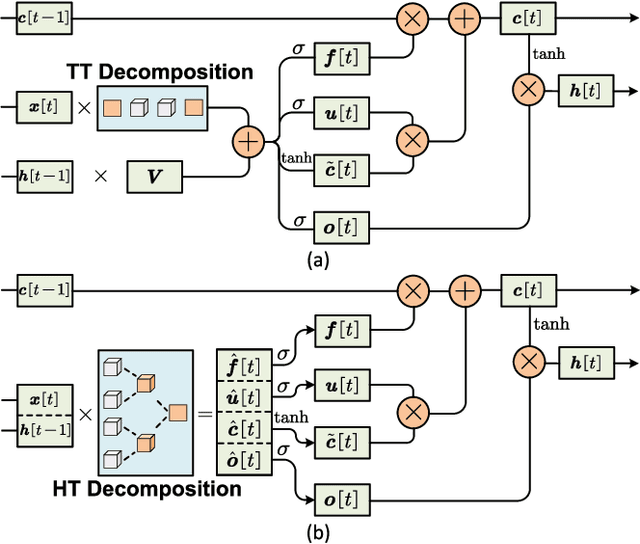
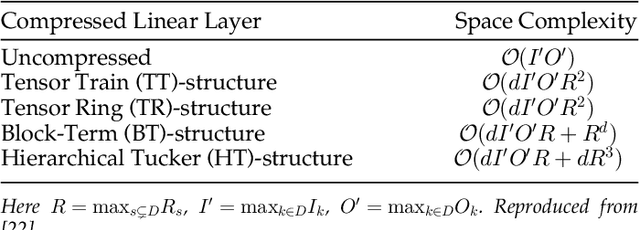
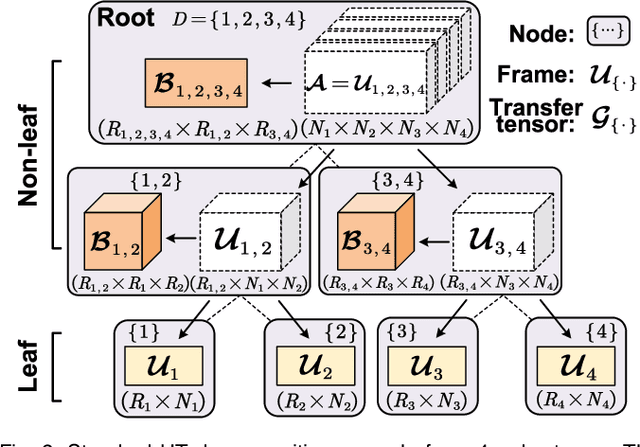

Long short-term memory (LSTM) is a type of powerful deep neural network that has been widely used in many sequence analysis and modeling applications. However, the large model size problem of LSTM networks make their practical deployment still very challenging, especially for the video recognition tasks that require high-dimensional input data. Aiming to overcome this limitation and fully unlock the potentials of LSTM models, in this paper we propose to perform algorithm and hardware co-design towards high-performance energy-efficient LSTM networks. At algorithm level, we propose to develop fully decomposed hierarchical Tucker (FDHT) structure-based LSTM, namely FDHT-LSTM, which enjoys ultra-low model complexity while still achieving high accuracy. In order to fully reap such attractive algorithmic benefit, we further develop the corresponding customized hardware architecture to support the efficient execution of the proposed FDHT-LSTM model. With the delicate design of memory access scheme, the complicated matrix transformation can be efficiently supported by the underlying hardware without any access conflict in an on-the-fly way. Our evaluation results show that both the proposed ultra-compact FDHT-LSTM models and the corresponding hardware accelerator achieve very high performance. Compared with the state-of-the-art compressed LSTM models, FDHT-LSTM enjoys both order-of-magnitude reduction in model size and significant accuracy improvement across different video recognition datasets. Meanwhile, compared with the state-of-the-art tensor decomposed model-oriented hardware TIE, our proposed FDHT-LSTM architecture achieves better performance in throughput, area efficiency and energy efficiency, respectively on LSTM-Youtube workload. For LSTM-UCF workload, our proposed design also outperforms TIE with higher throughput, higher energy efficiency and comparable area efficiency.
CSTAR: Towards Compact and STructured Deep Neural Networks with Adversarial Robustness
Dec 04, 2022



Model compression and model defense for deep neural networks (DNNs) have been extensively and individually studied. Considering the co-importance of model compactness and robustness in practical applications, several prior works have explored to improve the adversarial robustness of the sparse neural networks. However, the structured sparse models obtained by the exiting works suffer severe performance degradation for both benign and robust accuracy, thereby causing a challenging dilemma between robustness and structuredness of the compact DNNs. To address this problem, in this paper, we propose CSTAR, an efficient solution that can simultaneously impose the low-rankness-based Compactness, high STructuredness and high Adversarial Robustness on the target DNN models. By formulating the low-rankness and robustness requirement within the same framework and globally determining the ranks, the compressed DNNs can simultaneously achieve high compression performance and strong adversarial robustness. Evaluations for various DNN models on different datasets demonstrate the effectiveness of CSTAR. Compared with the state-of-the-art robust structured pruning methods, CSTAR shows consistently better performance. For instance, when compressing ResNet-18 on CIFAR-10, CSTAR can achieve up to 20.07% and 11.91% improvement for benign accuracy and robust accuracy, respectively. For compressing ResNet-18 with 16x compression ratio on Imagenet, CSTAR can obtain 8.58% benign accuracy gain and 4.27% robust accuracy gain compared to the existing robust structured pruning method.
CHIP: CHannel Independence-based Pruning for Compact Neural Networks
Oct 26, 2021



Filter pruning has been widely used for neural network compression because of its enabled practical acceleration. To date, most of the existing filter pruning works explore the importance of filters via using intra-channel information. In this paper, starting from an inter-channel perspective, we propose to perform efficient filter pruning using Channel Independence, a metric that measures the correlations among different feature maps. The less independent feature map is interpreted as containing less useful information$/$knowledge, and hence its corresponding filter can be pruned without affecting model capacity. We systematically investigate the quantification metric, measuring scheme and sensitiveness$/$reliability of channel independence in the context of filter pruning. Our evaluation results for different models on various datasets show the superior performance of our approach. Notably, on CIFAR-10 dataset our solution can bring $0.75\%$ and $0.94\%$ accuracy increase over baseline ResNet-56 and ResNet-110 models, respectively, and meanwhile the model size and FLOPs are reduced by $42.8\%$ and $47.4\%$ (for ResNet-56) and $48.3\%$ and $52.1\%$ (for ResNet-110), respectively. On ImageNet dataset, our approach can achieve $40.8\%$ and $44.8\%$ storage and computation reductions, respectively, with $0.15\%$ accuracy increase over the baseline ResNet-50 model. The code is available at https://github.com/Eclipsess/CHIP_NeurIPS2021.