 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongqiu Wu
Instruction-Driven Game Engines on Large Language Models
Apr 03, 2024
The Instruction-Driven Game Engine (IDGE) project aims to democratize game development by enabling a large language model (LLM) to follow free-form game rules and autonomously generate game-play processes. The IDGE allows users to create games by issuing simple natural language instructions, which significantly lowers the barrier for game development. We approach the learning process for IDGEs as a Next State Prediction task, wherein the model autoregressively predicts in-game states given player actions. It is a challenging task because the computation of in-game states must be precise; otherwise, slight errors could disrupt the game-play. To address this, we train the IDGE in a curriculum manner that progressively increases the model's exposure to complex scenarios. Our initial progress lies in developing an IDGE for Poker, a universally cherished card game. The engine we've designed not only supports a wide range of poker variants but also allows for high customization of rules through natural language inputs. Furthermore, it also favors rapid prototyping of new games from minimal samples, proposing an innovative paradigm in game development that relies on minimal prompt and data engineering. This work lays the groundwork for future advancements in instruction-driven game creation, potentially transforming how games are designed and played.
Unveiling Vulnerability of Self-Attention
Feb 26, 2024Pre-trained language models (PLMs) are shown to be vulnerable to minor word changes, which poses a big threat to real-world systems. While previous studies directly focus on manipulating word inputs, they are limited by their means of generating adversarial samples, lacking generalization to versatile real-world attack. This paper studies the basic structure of transformer-based PLMs, the self-attention (SA) mechanism. (1) We propose a powerful perturbation technique \textit{HackAttend}, which perturbs the attention scores within the SA matrices via meticulously crafted attention masks. We show that state-of-the-art PLMs fall into heavy vulnerability that minor attention perturbations $(1\%)$ can produce a very high attack success rate $(98\%)$. Our paper expands the conventional text attack of word perturbations to more general structural perturbations. (2) We introduce \textit{S-Attend}, a novel smoothing technique that effectively makes SA robust via structural perturbations. We empirically demonstrate that this simple yet effective technique achieves robust performance on par with adversarial training when facing various text attackers. Code is publicly available at \url{github.com/liongkj/HackAttend}.
Episodic Return Decomposition by Difference of Implicitly Assigned Sub-Trajectory Reward
Dec 17, 2023Real-world decision-making problems are usually accompanied by delayed rewards, which affects the sample efficiency of Reinforcement Learning, especially in the extremely delayed case where the only feedback is the episodic reward obtained at the end of an episode. Episodic return decomposition is a promising way to deal with the episodic-reward setting. Several corresponding algorithms have shown remarkable effectiveness of the learned step-wise proxy rewards from return decomposition. However, these existing methods lack either attribution or representation capacity, leading to inefficient decomposition in the case of long-term episodes. In this paper, we propose a novel episodic return decomposition method called Diaster (Difference of implicitly assigned sub-trajectory reward). Diaster decomposes any episodic reward into credits of two divided sub-trajectories at any cut point, and the step-wise proxy rewards come from differences in expectation. We theoretically and empirically verify that the decomposed proxy reward function can guide the policy to be nearly optimal. Experimental results show that our method outperforms previous state-of-the-art methods in terms of both sample efficiency and performance.
Empower Nested Boolean Logic via Self-Supervised Curriculum Learning
Oct 09, 2023



Beyond the great cognitive powers showcased by language models, it is crucial to scrutinize whether their reasoning capabilities stem from strong generalization or merely exposure to relevant data. As opposed to constructing increasingly complex logic, this paper probes into the boolean logic, the root capability of a logical reasoner. We find that any pre-trained language models even including large language models only behave like a random selector in the face of multi-nested boolean logic, a task that humans can handle with ease. To empower language models with this fundamental capability, this paper proposes a new self-supervised learning method \textit{Curriculum Logical Reasoning} (\textsc{Clr}), where we augment the training data with nested boolean logic chain step-by-step, and program the training from simpler logical patterns gradually to harder ones. This new training paradigm allows language models to effectively generalize to much harder and longer-hop logic, which can hardly be learned through naive training. Furthermore, we show that boolean logic is a great foundation for improving the subsequent general logical tasks.
Chinese Spelling Correction as Rephrasing Language Model
Aug 17, 2023



This paper studies Chinese Spelling Correction (CSC), which aims to detect and correct potential spelling errors in a given sentence. Current state-of-the-art methods regard CSC as a sequence tagging task and fine-tune BERT-based models on sentence pairs. However, we note a critical flaw in the process of tagging one character to another, that the correction is excessively conditioned on the error. This is opposite from human mindset, where individuals rephrase the complete sentence based on its semantics, rather than solely on the error patterns memorized before. Such a counter-intuitive learning process results in the bottleneck of generalizability and transferability of machine spelling correction. To address this, we propose $Rephrasing Language Modeling$ (ReLM), where the model is trained to rephrase the entire sentence by infilling additional slots, instead of character-to-character tagging. This novel training paradigm achieves the new state-of-the-art results across fine-tuned and zero-shot CSC benchmarks, outperforming previous counterparts by a large margin. Our method also learns transferable language representation when CSC is jointly trained with other tasks.
Rethinking Masked Language Modeling for Chinese Spelling Correction
May 28, 2023



In this paper, we study Chinese Spelling Correction (CSC) as a joint decision made by two separate models: a language model and an error model. Through empirical analysis, we find that fine-tuning BERT tends to over-fit the error model while under-fit the language model, resulting in poor generalization to out-of-distribution error patterns. Given that BERT is the backbone of most CSC models, this phenomenon has a significant negative impact. To address this issue, we are releasing a multi-domain benchmark LEMON, with higher quality and diversity than existing benchmarks, to allow a comprehensive assessment of the open domain generalization of CSC models. Then, we demonstrate that a very simple strategy, randomly masking 20\% non-error tokens from the input sequence during fine-tuning is sufficient for learning a much better language model without sacrificing the error model. This technique can be applied to any model architecture and achieves new state-of-the-art results on SIGHAN, ECSpell, and LEMON.
Attack Named Entity Recognition by Entity Boundary Interference
May 09, 2023
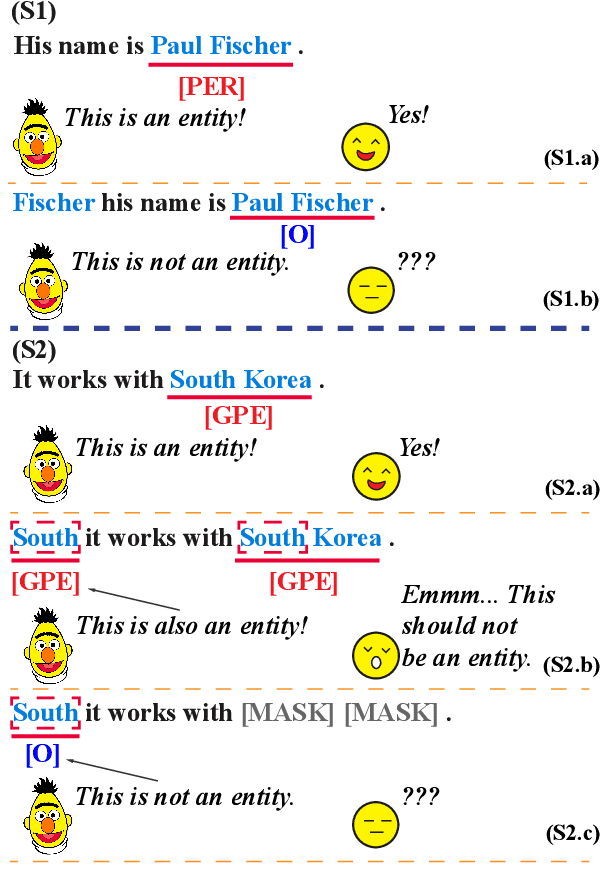


Named Entity Recognition (NER) is a cornerstone NLP task while its robustness has been given little attention. This paper rethinks the principles of NER attacks derived from sentence classification, as they can easily violate the label consistency between the original and adversarial NER examples. This is due to the fine-grained nature of NER, as even minor word changes in the sentence can result in the emergence or mutation of any entities, resulting in invalid adversarial examples. To this end, we propose a novel one-word modification NER attack based on a key insight, NER models are always vulnerable to the boundary position of an entity to make their decision. We thus strategically insert a new boundary into the sentence and trigger the Entity Boundary Interference that the victim model makes the wrong prediction either on this boundary word or on other words in the sentence. We call this attack Virtual Boundary Attack (ViBA), which is shown to be remarkably effective when attacking both English and Chinese models with a 70%-90% attack success rate on state-of-the-art language models (e.g. RoBERTa, DeBERTa) and also significantly faster than previous methods.
Toward Adversarial Training on Contextualized Language Representation
May 08, 2023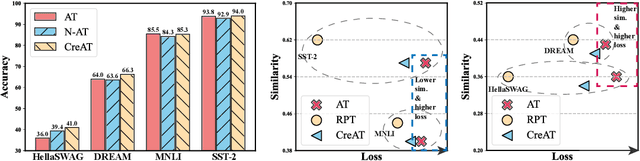
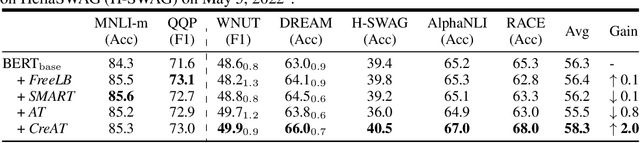
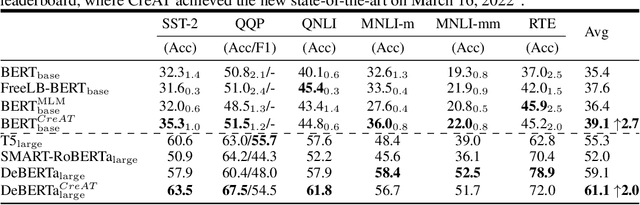
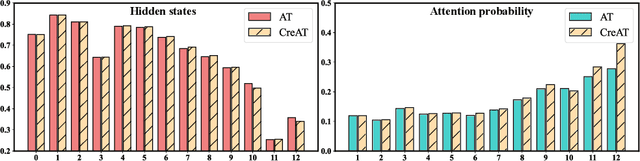
Beyond the success story of adversarial training (AT) in the recent text domain on top of pre-trained language models (PLMs), our empirical study showcases the inconsistent gains from AT on some tasks, e.g. commonsense reasoning, named entity recognition. This paper investigates AT from the perspective of the contextualized language representation outputted by PLM encoders. We find the current AT attacks lean to generate sub-optimal adversarial examples that can fool the decoder part but have a minor effect on the encoder. However, we find it necessary to effectively deviate the latter one to allow AT to gain. Based on the observation, we propose simple yet effective \textit{Contextualized representation-Adversarial Training} (CreAT), in which the attack is explicitly optimized to deviate the contextualized representation of the encoder. It allows a global optimization of adversarial examples that can fool the entire model. We also find CreAT gives rise to a better direction to optimize the adversarial examples, to let them less sensitive to hyperparameters. Compared to AT, CreAT produces consistent performance gains on a wider range of tasks and is proven to be more effective for language pre-training where only the encoder part is kept for downstream tasks. We achieve the new state-of-the-art performances on a series of challenging benchmarks, e.g. AdvGLUE (59.1 $ \rightarrow $ 61.1), HellaSWAG (93.0 $ \rightarrow $ 94.9), ANLI (68.1 $ \rightarrow $ 69.3).
Forging Multiple Training Objectives for Pre-trained Language Models via Meta-Learning
Oct 19, 2022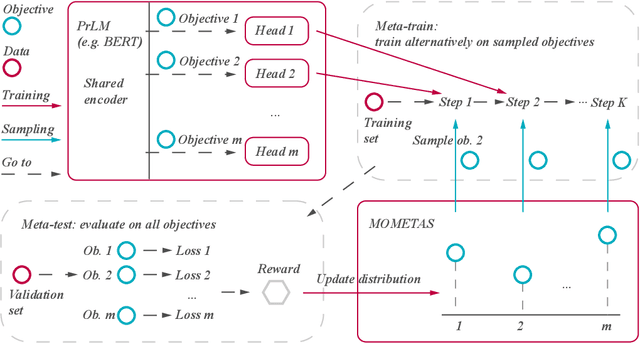
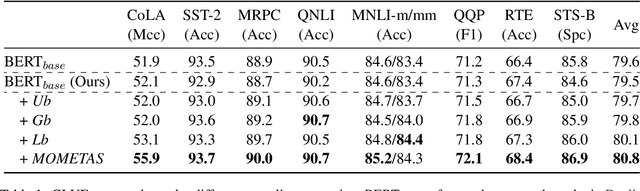
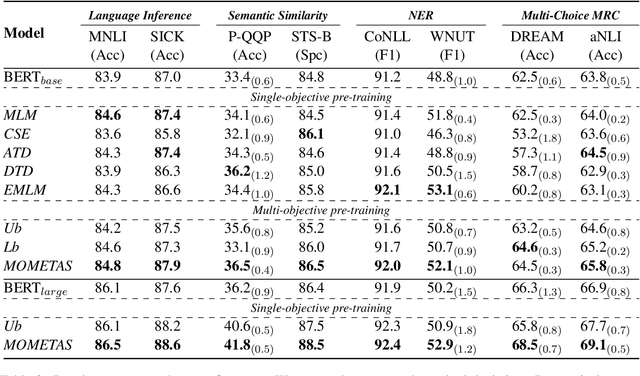
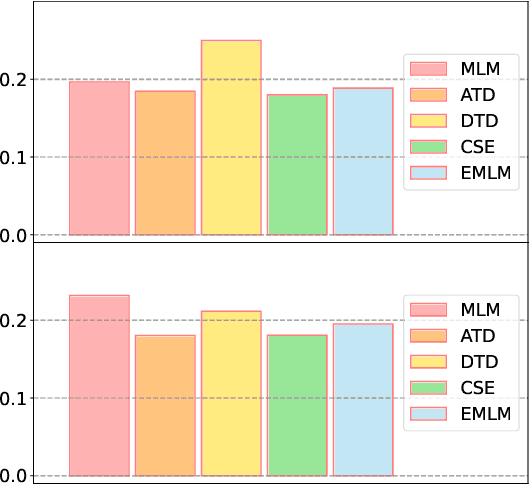
Multiple pre-training objectives fill the vacancy of the understanding capability of single-objective language modeling, which serves the ultimate purpose of pre-trained language models (PrLMs), generalizing well on a mass of scenarios. However, learning multiple training objectives in a single model is challenging due to the unknown relative significance as well as the potential contrariety between them. Empirical studies have shown that the current objective sampling in an ad-hoc manual setting makes the learned language representation barely converge to the desired optimum. Thus, we propose \textit{MOMETAS}, a novel adaptive sampler based on meta-learning, which learns the latent sampling pattern on arbitrary pre-training objectives. Such a design is lightweight with negligible additional training overhead. To validate our approach, we adopt five objectives and conduct continual pre-training with BERT-base and BERT-large models, where MOMETAS demonstrates universal performance gain over other rule-based sampling strategies on 14 natural language processing tasks.
Semantic-Preserving Adversarial Code Comprehension
Sep 12, 2022
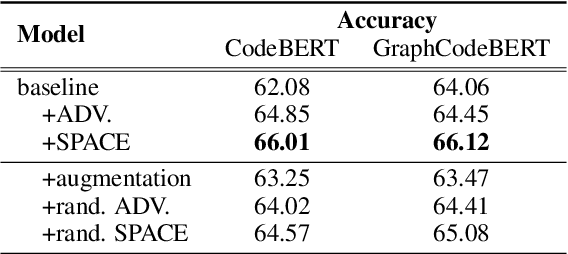


Based on the tremendous success of pre-trained language models (PrLMs) for source code comprehension tasks, current literature studies either ways to further improve the performance (generalization) of PrLMs, or their robustness against adversarial attacks. However, they have to compromise on the trade-off between the two aspects and none of them consider improving both sides in an effective and practical way. To fill this gap, we propose Semantic-Preserving Adversarial Code Embeddings (SPACE) to find the worst-case semantic-preserving attacks while forcing the model to predict the correct labels under these worst cases. Experiments and analysis demonstrate that SPACE can stay robust against state-of-the-art attacks while boosting the performance of PrLMs for code.