 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Yu
Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
Apr 14, 2024
Reinforcement learning (RL) trains agents to accomplish complex tasks through environmental interaction data, but its capacity is also limited by the scope of the available data. To obtain a knowledgeable agent, a promising approach is to leverage the knowledge from large language models (LLMs). Despite previous studies combining LLMs with RL, seamless integration of the two components remains challenging due to their semantic gap. This paper introduces a novel method, Knowledgeable Agents from Language Model Rollouts (KALM), which extracts knowledge from LLMs in the form of imaginary rollouts that can be easily learned by the agent through offline reinforcement learning methods. The primary challenge of KALM lies in LLM grounding, as LLMs are inherently limited to textual data, whereas environmental data often comprise numerical vectors unseen to LLMs. To address this, KALM fine-tunes the LLM to perform various tasks based on environmental data, including bidirectional translation between natural language descriptions of skills and their corresponding rollout data. This grounding process enhances the LLM's comprehension of environmental dynamics, enabling it to generate diverse and meaningful imaginary rollouts that reflect novel skills. Initial empirical evaluations on the CLEVR-Robot environment demonstrate that KALM enables agents to complete complex rephrasings of task goals and extend their capabilities to novel tasks requiring unprecedented optimal behaviors. KALM achieves a success rate of 46% in executing tasks with unseen goals, substantially surpassing the 26% success rate achieved by baseline methods. Furthermore, KALM effectively enables the LLM to comprehend environmental dynamics, resulting in the generation of meaningful imaginary rollouts that reflect novel skills and demonstrate the seamless integration of large language models and reinforcement learning.
SceneTracker: Long-term Scene Flow Estimation Network
Mar 29, 2024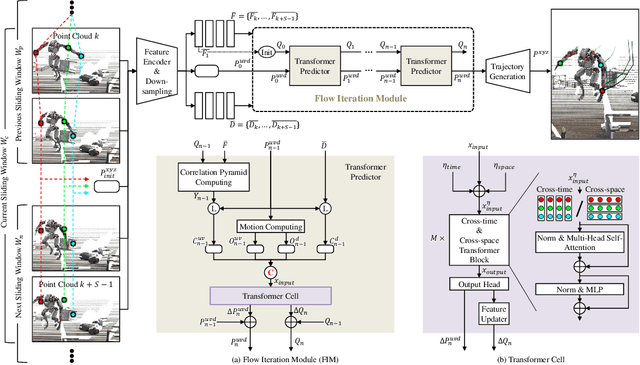



Considering the complementarity of scene flow estimation in the spatial domain's focusing capability and 3D object tracking in the temporal domain's coherence, this study aims to address a comprehensive new task that can simultaneously capture fine-grained and long-term 3D motion in an online manner: long-term scene flow estimation (LSFE). We introduce SceneTracker, a novel learning-based LSFE network that adopts an iterative approach to approximate the optimal trajectory. Besides, it dynamically indexes and constructs appearance and depth correlation features simultaneously and employs the Transformer to explore and utilize long-range connections within and between trajectories. With detailed experiments, SceneTracker shows superior capabilities in handling 3D spatial occlusion and depth noise interference, highly tailored to the LSFE task's needs. The code for SceneTracker is available at https://github.com/wwsource/SceneTracker.
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024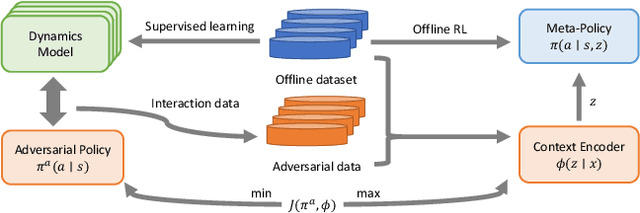

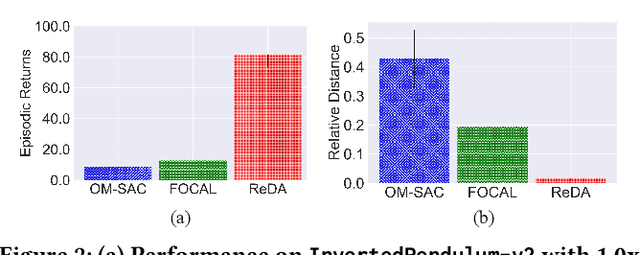
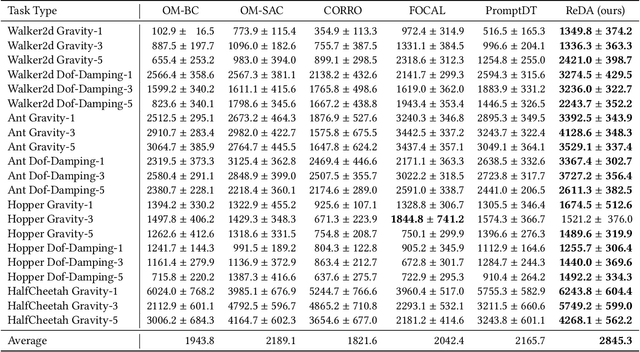
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
Prejudice and Caprice: A Statistical Framework for Measuring Social Discrimination in Large Language Models
Feb 29, 2024The growing integration of large language models (LLMs) into social operations amplifies their impact on decisions in crucial areas such as economics, law, education, and healthcare, raising public concerns about these models' discrimination-related safety and reliability. However, prior discrimination measuring frameworks solely assess the average discriminatory behavior of LLMs, often proving inadequate due to the overlook of an additional discrimination-leading factor, i.e., the LLMs' prediction variation across diverse contexts. In this work, we present the Prejudice-Caprice Framework (PCF) that comprehensively measures discrimination in LLMs by considering both their consistently biased preference and preference variation across diverse contexts. Specifically, we mathematically dissect the aggregated contextualized discrimination risk of LLMs into prejudice risk, originating from LLMs' persistent prejudice, and caprice risk, stemming from their generation inconsistency. In addition, we utilize a data-mining approach to gather preference-detecting probes from sentence skeletons, devoid of attribute indications, to approximate LLMs' applied contexts. While initially intended for assessing discrimination in LLMs, our proposed PCF facilitates the comprehensive and flexible measurement of any inductive biases, including knowledge alongside prejudice, across various modality models. We apply our discrimination-measuring framework to 12 common LLMs, yielding intriguing findings: i) modern LLMs demonstrate significant pro-male stereotypes, ii) LLMs' exhibited discrimination correlates with several social and economic factors, iii) prejudice risk dominates the overall discrimination risk and follows a normal distribution, and iv) caprice risk contributes minimally to the overall risk but follows a fat-tailed distribution, suggesting that it is wild risk requiring enhanced surveillance.
Debiased Offline Representation Learning for Fast Online Adaptation in Non-stationary Dynamics
Feb 17, 2024Developing policies that can adjust to non-stationary environments is essential for real-world reinforcement learning applications. However, learning such adaptable policies in offline settings, with only a limited set of pre-collected trajectories, presents significant challenges. A key difficulty arises because the limited offline data makes it hard for the context encoder to differentiate between changes in the environment dynamics and shifts in the behavior policy, often leading to context misassociations. To address this issue, we introduce a novel approach called Debiased Offline Representation for fast online Adaptation (DORA). DORA incorporates an information bottleneck principle that maximizes mutual information between the dynamics encoding and the environmental data, while minimizing mutual information between the dynamics encoding and the actions of the behavior policy. We present a practical implementation of DORA, leveraging tractable bounds of the information bottleneck principle. Our experimental evaluation across six benchmark MuJoCo tasks with variable parameters demonstrates that DORA not only achieves a more precise dynamics encoding but also significantly outperforms existing baselines in terms of performance.
Learning by Doing: An Online Causal Reinforcement Learning Framework with Causal-Aware Policy
Feb 07, 2024As a key component to intuitive cognition and reasoning solutions in human intelligence, causal knowledge provides great potential for reinforcement learning (RL) agents' interpretability towards decision-making by helping reduce the searching space. However, there is still a considerable gap in discovering and incorporating causality into RL, which hinders the rapid development of causal RL. In this paper, we consider explicitly modeling the generation process of states with the causal graphical model, based on which we augment the policy. We formulate the causal structure updating into the RL interaction process with active intervention learning of the environment. To optimize the derived objective, we propose a framework with theoretical performance guarantees that alternates between two steps: using interventions for causal structure learning during exploration and using the learned causal structure for policy guidance during exploitation. Due to the lack of public benchmarks that allow direct intervention in the state space, we design the root cause localization task in our simulated fault alarm environment and then empirically show the effectiveness and robustness of the proposed method against state-of-the-art baselines. Theoretical analysis shows that our performance improvement attributes to the virtuous cycle of causal-guided policy learning and causal structure learning, which aligns with our experimental results.
PALoc: Advancing SLAM Benchmarking with Prior-Assisted 6-DoF Trajectory Generation and Uncertainty Estimation
Feb 06, 2024Accurately generating ground truth (GT) trajectories is essential for Simultaneous Localization and Mapping (SLAM) evaluation, particularly under varying environmental conditions. This study introduces a systematic approach employing a prior map-assisted framework for generating dense six-degree-of-freedom (6-DoF) GT poses for the first time, enhancing the fidelity of both indoor and outdoor SLAM datasets. Our method excels in handling degenerate and stationary conditions frequently encountered in SLAM datasets, thereby increasing robustness and precision. A significant aspect of our approach is the detailed derivation of covariances within the factor graph, enabling an in-depth analysis of pose uncertainty propagation. This analysis crucially contributes to demonstrating specific pose uncertainties and enhancing trajectory reliability from both theoretical and empirical perspectives. Additionally, we provide an open-source toolbox (https://github.com/JokerJohn/Cloud_Map_Evaluation) for map evaluation criteria, facilitating the indirect assessment of overall trajectory precision. Experimental results show at least a 30\% improvement in map accuracy and a 20\% increase in direct trajectory accuracy compared to the Iterative Closest Point (ICP) \cite{sharp2002icp} algorithm across diverse campus environments, with substantially enhanced robustness. Our open-source solution (https://github.com/JokerJohn/PALoc), extensively applied in the FusionPortable\cite{Jiao2022Mar} dataset, is geared towards SLAM benchmark dataset augmentation and represents a significant advancement in SLAM evaluations.
Empowering Language Models with Active Inquiry for Deeper Understanding
Feb 06, 2024The rise of large language models (LLMs) has revolutionized the way that we interact with artificial intelligence systems through natural language. However, LLMs often misinterpret user queries because of their uncertain intention, leading to less helpful responses. In natural human interactions, clarification is sought through targeted questioning to uncover obscure information. Thus, in this paper, we introduce LaMAI (Language Model with Active Inquiry), designed to endow LLMs with this same level of interactive engagement. LaMAI leverages active learning techniques to raise the most informative questions, fostering a dynamic bidirectional dialogue. This approach not only narrows the contextual gap but also refines the output of the LLMs, aligning it more closely with user expectations. Our empirical studies, across a variety of complex datasets where LLMs have limited conversational context, demonstrate the effectiveness of LaMAI. The method improves answer accuracy from 31.9% to 50.9%, outperforming other leading question-answering frameworks. Moreover, in scenarios involving human participants, LaMAI consistently generates responses that are superior or comparable to baseline methods in more than 82% of the cases. The applicability of LaMAI is further evidenced by its successful integration with various LLMs, highlighting its potential for the future of interactive language models.