 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi-Chen Li
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024
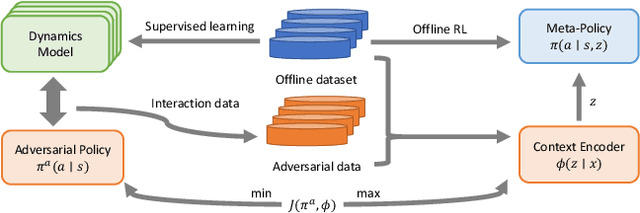

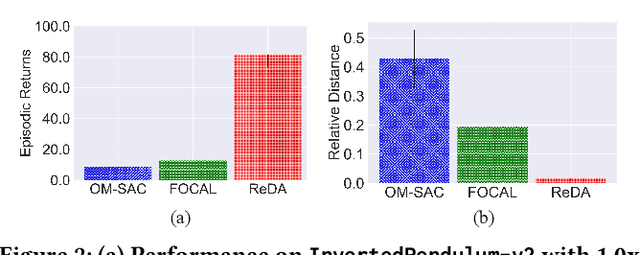
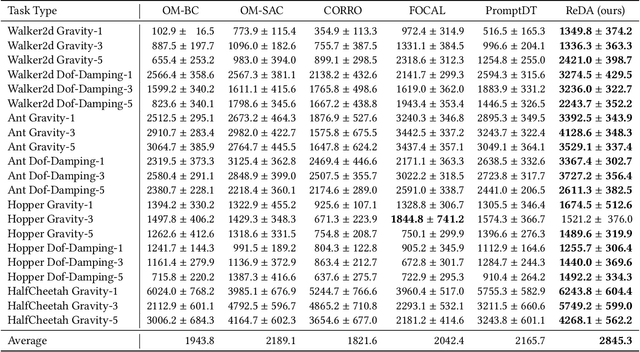
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
Debiased Offline Representation Learning for Fast Online Adaptation in Non-stationary Dynamics
Feb 17, 2024Developing policies that can adjust to non-stationary environments is essential for real-world reinforcement learning applications. However, learning such adaptable policies in offline settings, with only a limited set of pre-collected trajectories, presents significant challenges. A key difficulty arises because the limited offline data makes it hard for the context encoder to differentiate between changes in the environment dynamics and shifts in the behavior policy, often leading to context misassociations. To address this issue, we introduce a novel approach called Debiased Offline Representation for fast online Adaptation (DORA). DORA incorporates an information bottleneck principle that maximizes mutual information between the dynamics encoding and the environmental data, while minimizing mutual information between the dynamics encoding and the actions of the behavior policy. We present a practical implementation of DORA, leveraging tractable bounds of the information bottleneck principle. Our experimental evaluation across six benchmark MuJoCo tasks with variable parameters demonstrates that DORA not only achieves a more precise dynamics encoding but also significantly outperforms existing baselines in terms of performance.
Imitator Learning: Achieve Out-of-the-Box Imitation Ability in Variable Environments
Oct 09, 2023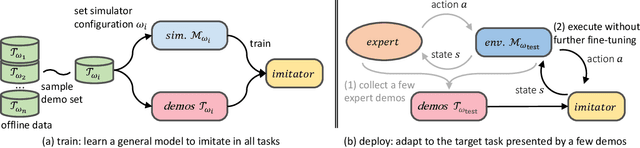
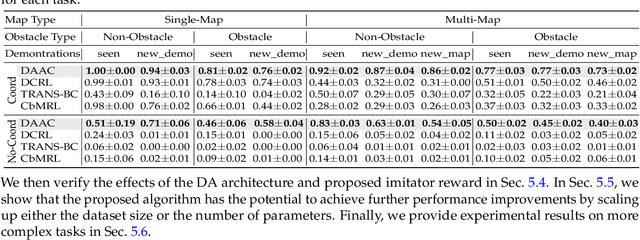
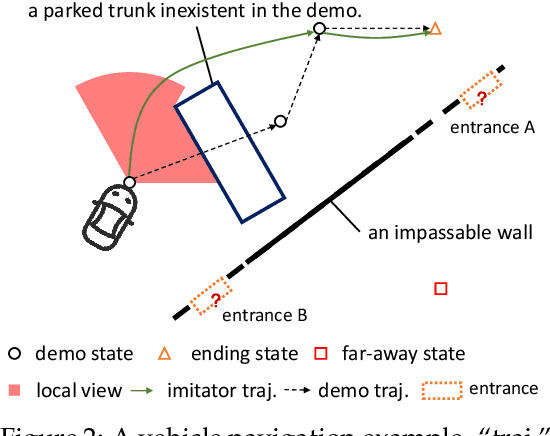

Imitation learning (IL) enables agents to mimic expert behaviors. Most previous IL techniques focus on precisely imitating one policy through mass demonstrations. However, in many applications, what humans require is the ability to perform various tasks directly through a few demonstrations of corresponding tasks, where the agent would meet many unexpected changes when deployed. In this scenario, the agent is expected to not only imitate the demonstration but also adapt to unforeseen environmental changes. This motivates us to propose a new topic called imitator learning (ItorL), which aims to derive an imitator module that can on-the-fly reconstruct the imitation policies based on very limited expert demonstrations for different unseen tasks, without any extra adjustment. In this work, we focus on imitator learning based on only one expert demonstration. To solve ItorL, we propose Demo-Attention Actor-Critic (DAAC), which integrates IL into a reinforcement-learning paradigm that can regularize policies' behaviors in unexpected situations. Besides, for autonomous imitation policy building, we design a demonstration-based attention architecture for imitator policy that can effectively output imitated actions by adaptively tracing the suitable states in demonstrations. We develop a new navigation benchmark and a robot environment for \topic~and show that DAAC~outperforms previous imitation methods \textit{with large margins} both on seen and unseen tasks.
Policy Regularization with Dataset Constraint for Offline Reinforcement Learning
Jun 11, 2023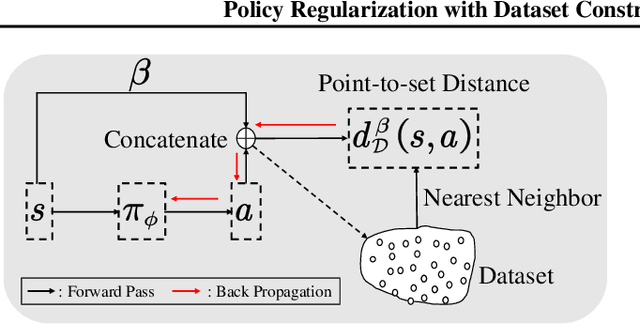
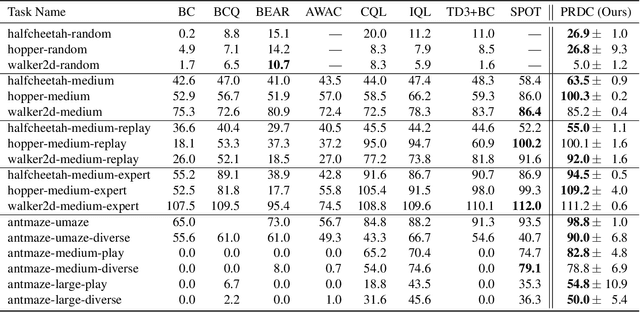

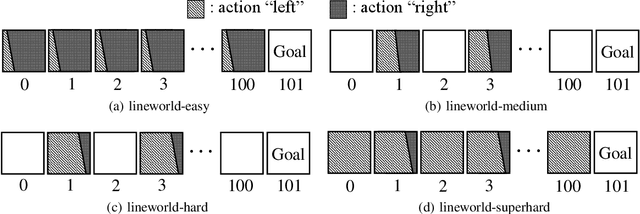
We consider the problem of learning the best possible policy from a fixed dataset, known as offline Reinforcement Learning (RL). A common taxonomy of existing offline RL works is policy regularization, which typically constrains the learned policy by distribution or support of the behavior policy. However, distribution and support constraints are overly conservative since they both force the policy to choose similar actions as the behavior policy when considering particular states. It will limit the learned policy's performance, especially when the behavior policy is sub-optimal. In this paper, we find that regularizing the policy towards the nearest state-action pair can be more effective and thus propose Policy Regularization with Dataset Constraint (PRDC). When updating the policy in a given state, PRDC searches the entire dataset for the nearest state-action sample and then restricts the policy with the action of this sample. Unlike previous works, PRDC can guide the policy with proper behaviors from the dataset, allowing it to choose actions that do not appear in the dataset along with the given state. It is a softer constraint but still keeps enough conservatism from out-of-distribution actions. Empirical evidence and theoretical analysis show that PRDC can alleviate offline RL's fundamentally challenging value overestimation issue with a bounded performance gap. Moreover, on a set of locomotion and navigation tasks, PRDC achieves state-of-the-art performance compared with existing methods. Code is available at https://github.com/LAMDA-RL/PRDC