 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlex Kot
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
May 03, 2024
Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024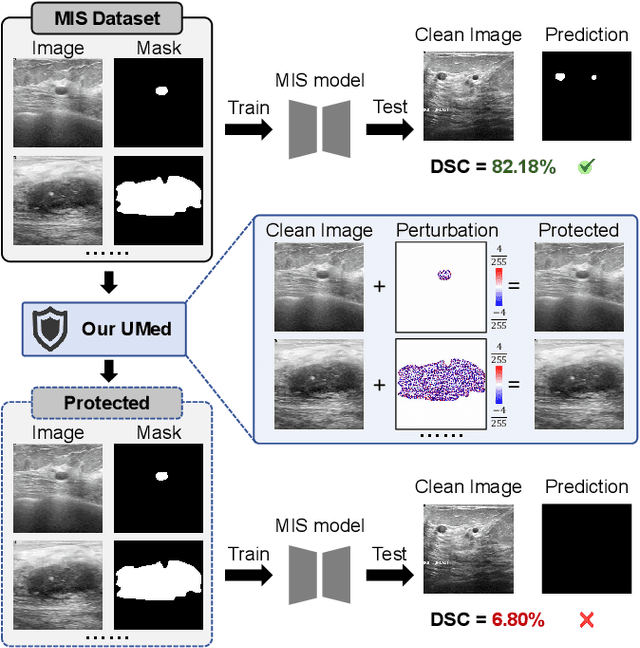
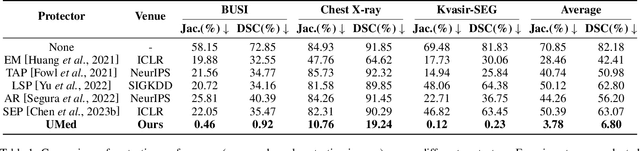
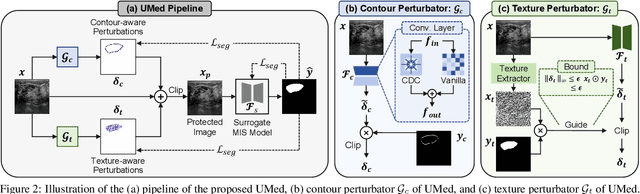
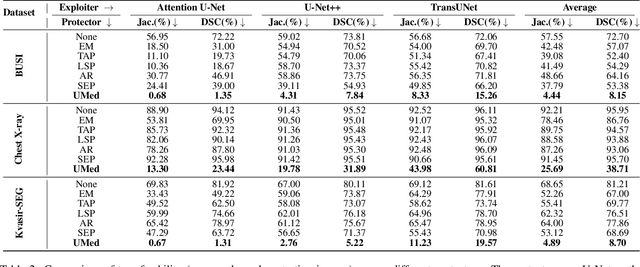
The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Mar 05, 2024Face Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable sorely using the dominant modality. To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients. Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source code and protocols will be released on https://github.com/OMGGGGG/mmdg.
MIMIC: Mask Image Pre-training with Mix Contrastive Fine-tuning for Facial Expression Recognition
Jan 14, 2024Cutting-edge research in facial expression recognition (FER) currently favors the utilization of convolutional neural networks (CNNs) backbone which is supervisedly pre-trained on face recognition datasets for feature extraction. However, due to the vast scale of face recognition datasets and the high cost associated with collecting facial labels, this pre-training paradigm incurs significant expenses. Towards this end, we propose to pre-train vision Transformers (ViTs) through a self-supervised approach on a mid-scale general image dataset. In addition, when compared with the domain disparity existing between face datasets and FER datasets, the divergence between general datasets and FER datasets is more pronounced. Therefore, we propose a contrastive fine-tuning approach to effectively mitigate this domain disparity. Specifically, we introduce a novel FER training paradigm named Mask Image pre-training with MIx Contrastive fine-tuning (MIMIC). In the initial phase, we pre-train the ViT via masked image reconstruction on general images. Subsequently, in the fine-tuning stage, we introduce a mix-supervised contrastive learning process, which enhances the model with a more extensive range of positive samples by the mixing strategy. Through extensive experiments conducted on three benchmark datasets, we demonstrate that our MIMIC outperforms the previous training paradigm, showing its capability to learn better representations. Remarkably, the results indicate that the vanilla ViT can achieve impressive performance without the need for intricate, auxiliary-designed modules. Moreover, when scaling up the model size, MIMIC exhibits no performance saturation and is superior to the current state-of-the-art methods.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.
Biomedical Image Splicing Detection using Uncertainty-Guided Refinement
Sep 28, 2023



Recently, a surge in biomedical academic publications suspected of image manipulation has led to numerous retractions, turning biomedical image forensics into a research hotspot. While manipulation detectors are concerning, the specific detection of splicing traces in biomedical images remains underexplored. The disruptive factors within biomedical images, such as artifacts, abnormal patterns, and noises, show misleading features like the splicing traces, greatly increasing the challenge for this task. Moreover, the scarcity of high-quality spliced biomedical images also limits potential advancements in this field. In this work, we propose an Uncertainty-guided Refinement Network (URN) to mitigate the effects of these disruptive factors. Our URN can explicitly suppress the propagation of unreliable information flow caused by disruptive factors among regions, thereby obtaining robust features. Moreover, URN enables a concentration on the refinement of uncertainly predicted regions during the decoding phase. Besides, we construct a dataset for Biomedical image Splicing (BioSp) detection, which consists of 1,290 spliced images. Compared with existing datasets, BioSp comprises the largest number of spliced images and the most diverse sources. Comprehensive experiments on three benchmark datasets demonstrate the superiority of the proposed method. Meanwhile, we verify the generalizability of URN when against cross-dataset domain shifts and its robustness to resist post-processing approaches. Our BioSp dataset will be released upon acceptance.
S-Adapter: Generalizing Vision Transformer for Face Anti-Spoofing with Statistical Tokens
Sep 07, 2023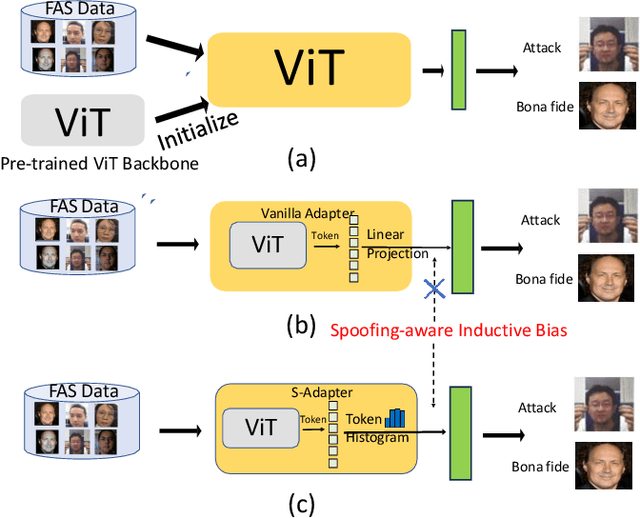
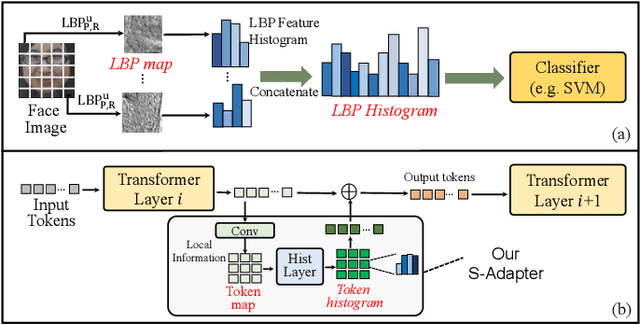
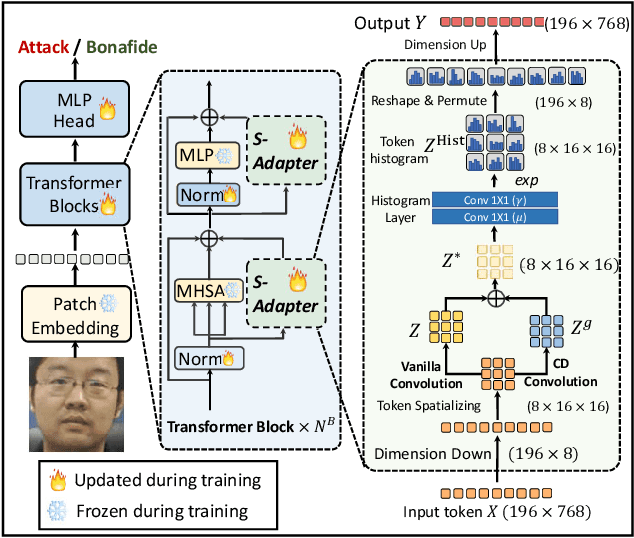
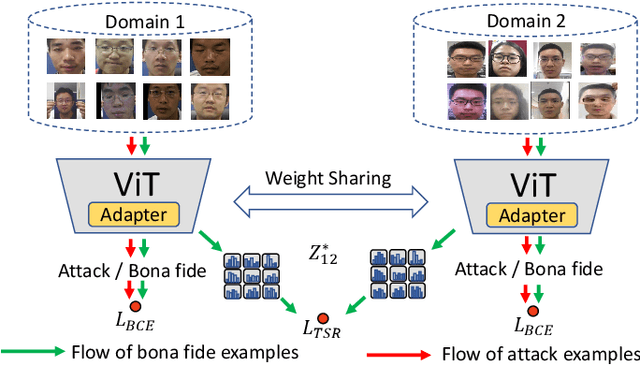
Face Anti-Spoofing (FAS) aims to detect malicious attempts to invade a face recognition system by presenting spoofed faces. State-of-the-art FAS techniques predominantly rely on deep learning models but their cross-domain generalization capabilities are often hindered by the domain shift problem, which arises due to different distributions between training and testing data. In this study, we develop a generalized FAS method under the Efficient Parameter Transfer Learning (EPTL) paradigm, where we adapt the pre-trained Vision Transformer models for the FAS task. During training, the adapter modules are inserted into the pre-trained ViT model, and the adapters are updated while other pre-trained parameters remain fixed. We find the limitations of previous vanilla adapters in that they are based on linear layers, which lack a spoofing-aware inductive bias and thus restrict the cross-domain generalization. To address this limitation and achieve cross-domain generalized FAS, we propose a novel Statistical Adapter (S-Adapter) that gathers local discriminative and statistical information from localized token histograms. To further improve the generalization of the statistical tokens, we propose a novel Token Style Regularization (TSR), which aims to reduce domain style variance by regularizing Gram matrices extracted from tokens across different domains. Our experimental results demonstrate that our proposed S-Adapter and TSR provide significant benefits in both zero-shot and few-shot cross-domain testing, outperforming state-of-the-art methods on several benchmark tests. We will release the source code upon acceptance.
Hyperbolic Face Anti-Spoofing
Aug 17, 2023



Learning generalized face anti-spoofing (FAS) models against presentation attacks is essential for the security of face recognition systems. Previous FAS methods usually encourage models to extract discriminative features, of which the distances within the same class (bonafide or attack) are pushed close while those between bonafide and attack are pulled away. However, these methods are designed based on Euclidean distance, which lacks generalization ability for unseen attack detection due to poor hierarchy embedding ability. According to the evidence that different spoofing attacks are intrinsically hierarchical, we propose to learn richer hierarchical and discriminative spoofing cues in hyperbolic space. Specifically, for unimodal FAS learning, the feature embeddings are projected into the Poincar\'e ball, and then the hyperbolic binary logistic regression layer is cascaded for classification. To further improve generalization, we conduct hyperbolic contrastive learning for the bonafide only while relaxing the constraints on diverse spoofing attacks. To alleviate the vanishing gradient problem in hyperbolic space, a new feature clipping method is proposed to enhance the training stability of hyperbolic models. Besides, we further design a multimodal FAS framework with Euclidean multimodal feature decomposition and hyperbolic multimodal feature fusion & classification. Extensive experiments on three benchmark datasets (i.e., WMCA, PADISI-Face, and SiW-M) with diverse attack types demonstrate that the proposed method can bring significant improvement compared to the Euclidean baselines on unseen attack detection. In addition, the proposed framework is also generalized well on four benchmark datasets (i.e., MSU-MFSD, IDIAP REPLAY-ATTACK, CASIA-FASD, and OULU-NPU) with a limited number of attack types.
Rehearsal-Free Domain Continual Face Anti-Spoofing: Generalize More and Forget Less
Mar 16, 2023



Face Anti-Spoofing (FAS) is recently studied under the continual learning setting, where the FAS models are expected to evolve after encountering the data from new domains. However, existing methods need extra replay buffers to store previous data for rehearsal, which becomes infeasible when previous data is unavailable because of privacy issues. In this paper, we propose the first rehearsal-free method for Domain Continual Learning (DCL) of FAS, which deals with catastrophic forgetting and unseen domain generalization problems simultaneously. For better generalization to unseen domains, we design the Dynamic Central Difference Convolutional Adapter (DCDCA) to adapt Vision Transformer (ViT) models during the continual learning sessions. To alleviate the forgetting of previous domains without using previous data, we propose the Proxy Prototype Contrastive Regularization (PPCR) to constrain the continual learning with previous domain knowledge from the proxy prototypes. Simulate practical DCL scenarios, we devise two new protocols which evaluate both generalization and anti-forgetting performance. Extensive experimental results show that our proposed method can improve the generalization performance in unseen domains and alleviate the catastrophic forgetting of the previous knowledge. The codes and protocols will be released soon.
Raw Image Reconstruction with Learned Compact Metadata
Feb 28, 2023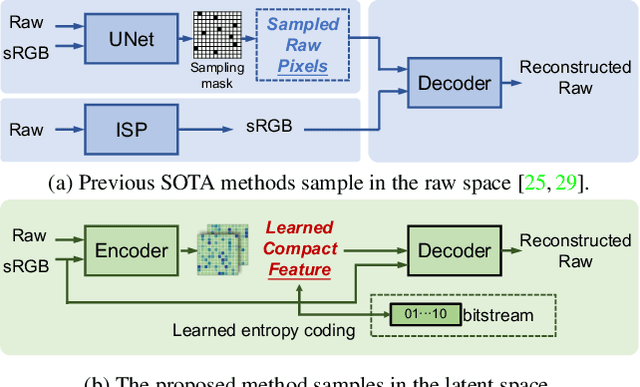
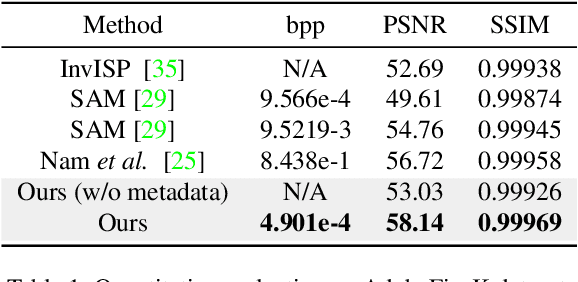
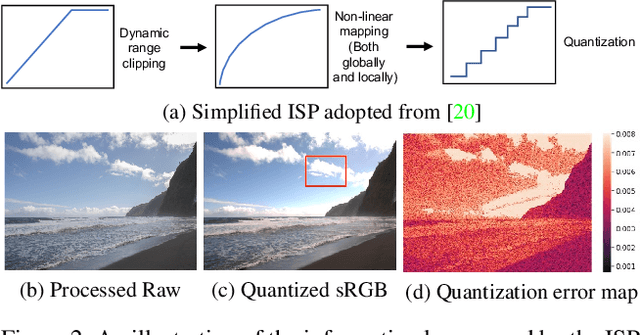
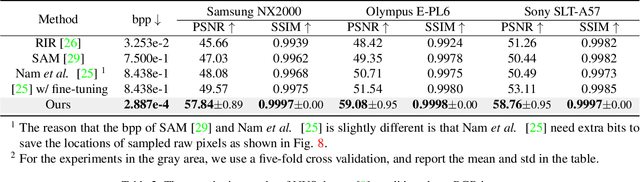
While raw images exhibit advantages over sRGB images (e.g., linearity and fine-grained quantization level), they are not widely used by common users due to the large storage requirements. Very recent works propose to compress raw images by designing the sampling masks in the raw image pixel space, leading to suboptimal image representations and redundant metadata. In this paper, we propose a novel framework to learn a compact representation in the latent space serving as the metadata in an end-to-end manner. Furthermore, we propose a novel sRGB-guided context model with improved entropy estimation strategies, which leads to better reconstruction quality, smaller size of metadata, and faster speed. We illustrate how the proposed raw image compression scheme can adaptively allocate more bits to image regions that are important from a global perspective. The experimental results show that the proposed method can achieve superior raw image reconstruction results using a smaller size of the metadata on both uncompressed sRGB images and JPEG images.