 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYawen Cui
FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
Apr 15, 2024
Multi-modal image fusion aims to combine information from different modes to create a single image with comprehensive information and detailed textures. However, fusion models based on convolutional neural networks encounter limitations in capturing global image features due to their focus on local convolution operations. Transformer-based models, while excelling in global feature modeling, confront computational challenges stemming from their quadratic complexity. Recently, the Selective Structured State Space Model has exhibited significant potential for long-range dependency modeling with linear complexity, offering a promising avenue to address the aforementioned dilemma. In this paper, we propose FusionMamba, a novel dynamic feature enhancement method for multimodal image fusion with Mamba. Specifically, we devise an improved efficient Mamba model for image fusion, integrating efficient visual state space model with dynamic convolution and channel attention. This refined model not only upholds the performance of Mamba and global modeling capability but also diminishes channel redundancy while enhancing local enhancement capability. Additionally, we devise a dynamic feature fusion module (DFFM) comprising two dynamic feature enhancement modules (DFEM) and a cross modality fusion mamba module (CMFM). The former serves for dynamic texture enhancement and dynamic difference perception, whereas the latter enhances correlation features between modes and suppresses redundant intermodal information. FusionMamba has yielded state-of-the-art (SOTA) performance across various multimodal medical image fusion tasks (CT-MRI, PET-MRI, SPECT-MRI), infrared and visible image fusion task (IR-VIS) and multimodal biomedical image fusion dataset (GFP-PC), which is proved that our model has generalization ability. The code for FusionMamba is available at https://github.com/millieXie/FusionMamba.
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape
Aug 22, 2023
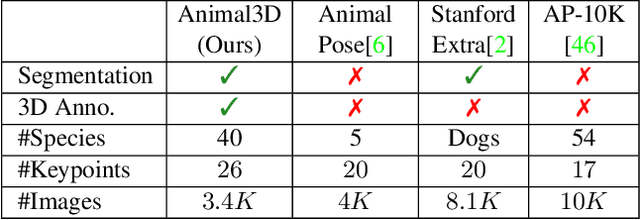
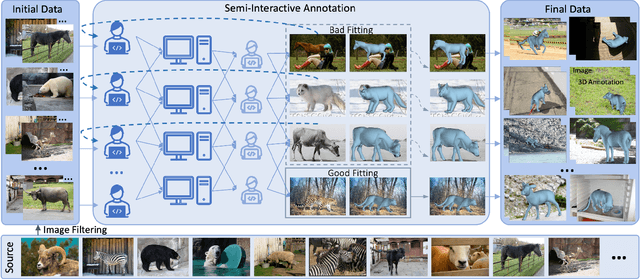

Accurately estimating the 3D pose and shape is an essential step towards understanding animal behavior, and can potentially benefit many downstream applications, such as wildlife conservation. However, research in this area is held back by the lack of a comprehensive and diverse dataset with high-quality 3D pose and shape annotations. In this paper, we propose Animal3D, the first comprehensive dataset for mammal animal 3D pose and shape estimation. Animal3D consists of 3379 images collected from 40 mammal species, high-quality annotations of 26 keypoints, and importantly the pose and shape parameters of the SMAL model. All annotations were labeled and checked manually in a multi-stage process to ensure highest quality results. Based on the Animal3D dataset, we benchmark representative shape and pose estimation models at: (1) supervised learning from only the Animal3D data, (2) synthetic to real transfer from synthetically generated images, and (3) fine-tuning human pose and shape estimation models. Our experimental results demonstrate that predicting the 3D shape and pose of animals across species remains a very challenging task, despite significant advances in human pose estimation. Our results further demonstrate that synthetic pre-training is a viable strategy to boost the model performance. Overall, Animal3D opens new directions for facilitating future research in animal 3D pose and shape estimation, and is publicly available.
Hyperbolic Face Anti-Spoofing
Aug 17, 2023



Learning generalized face anti-spoofing (FAS) models against presentation attacks is essential for the security of face recognition systems. Previous FAS methods usually encourage models to extract discriminative features, of which the distances within the same class (bonafide or attack) are pushed close while those between bonafide and attack are pulled away. However, these methods are designed based on Euclidean distance, which lacks generalization ability for unseen attack detection due to poor hierarchy embedding ability. According to the evidence that different spoofing attacks are intrinsically hierarchical, we propose to learn richer hierarchical and discriminative spoofing cues in hyperbolic space. Specifically, for unimodal FAS learning, the feature embeddings are projected into the Poincar\'e ball, and then the hyperbolic binary logistic regression layer is cascaded for classification. To further improve generalization, we conduct hyperbolic contrastive learning for the bonafide only while relaxing the constraints on diverse spoofing attacks. To alleviate the vanishing gradient problem in hyperbolic space, a new feature clipping method is proposed to enhance the training stability of hyperbolic models. Besides, we further design a multimodal FAS framework with Euclidean multimodal feature decomposition and hyperbolic multimodal feature fusion & classification. Extensive experiments on three benchmark datasets (i.e., WMCA, PADISI-Face, and SiW-M) with diverse attack types demonstrate that the proposed method can bring significant improvement compared to the Euclidean baselines on unseen attack detection. In addition, the proposed framework is also generalized well on four benchmark datasets (i.e., MSU-MFSD, IDIAP REPLAY-ATTACK, CASIA-FASD, and OULU-NPU) with a limited number of attack types.
Visual Prompt Flexible-Modal Face Anti-Spoofing
Jul 26, 2023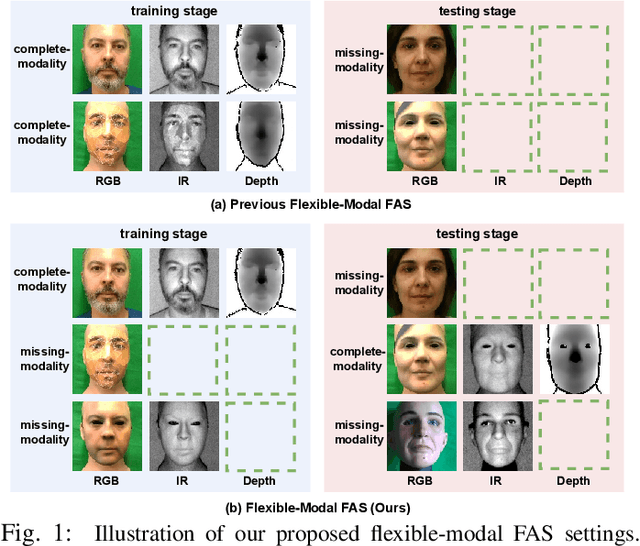
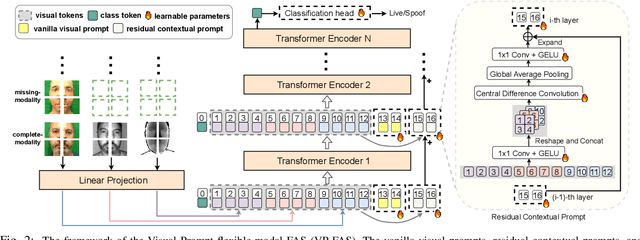
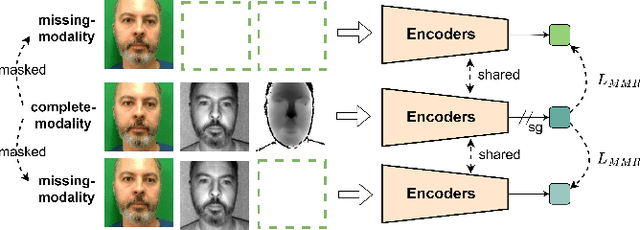
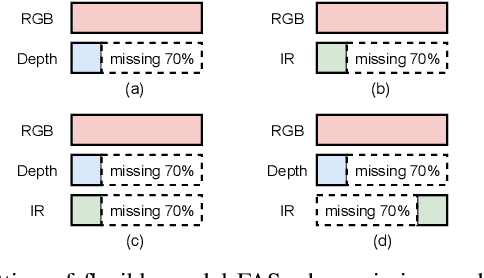
Recently, vision transformer based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, multimodal face data collected from the real world is often imperfect due to missing modalities from various imaging sensors. Recently, flexible-modal FAS~\cite{yu2023flexible} has attracted more attention, which aims to develop a unified multimodal FAS model using complete multimodal face data but is insensitive to test-time missing modalities. In this paper, we tackle one main challenge in flexible-modal FAS, i.e., when missing modality occurs either during training or testing in real-world situations. Inspired by the recent success of the prompt learning in language models, we propose \textbf{V}isual \textbf{P}rompt flexible-modal \textbf{FAS} (VP-FAS), which learns the modal-relevant prompts to adapt the frozen pre-trained foundation model to downstream flexible-modal FAS task. Specifically, both vanilla visual prompts and residual contextual prompts are plugged into multimodal transformers to handle general missing-modality cases, while only requiring less than 4\% learnable parameters compared to training the entire model. Furthermore, missing-modality regularization is proposed to force models to learn consistent multimodal feature embeddings when missing partial modalities. Extensive experiments conducted on two multimodal FAS benchmark datasets demonstrate the effectiveness of our VP-FAS framework that improves the performance under various missing-modality cases while alleviating the requirement of heavy model re-training.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 19, 2023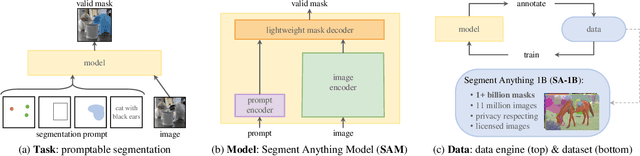

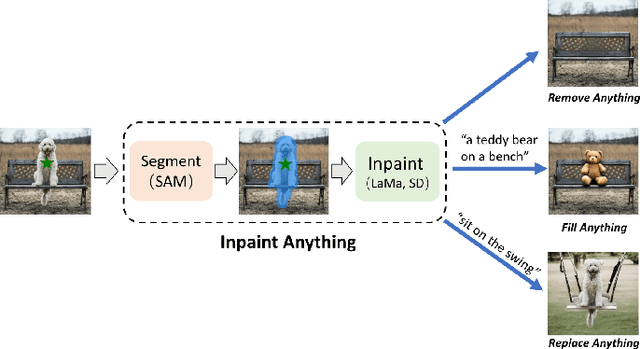
Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, many insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond. Finally, we maintain a continuously updated paper list and an open-source project summary for foundation model SAM at \href{https://github.com/liliu-avril/Awesome-Segment-Anything}{\color{magenta}{here}}.
Rehearsal-Free Domain Continual Face Anti-Spoofing: Generalize More and Forget Less
Mar 16, 2023



Face Anti-Spoofing (FAS) is recently studied under the continual learning setting, where the FAS models are expected to evolve after encountering the data from new domains. However, existing methods need extra replay buffers to store previous data for rehearsal, which becomes infeasible when previous data is unavailable because of privacy issues. In this paper, we propose the first rehearsal-free method for Domain Continual Learning (DCL) of FAS, which deals with catastrophic forgetting and unseen domain generalization problems simultaneously. For better generalization to unseen domains, we design the Dynamic Central Difference Convolutional Adapter (DCDCA) to adapt Vision Transformer (ViT) models during the continual learning sessions. To alleviate the forgetting of previous domains without using previous data, we propose the Proxy Prototype Contrastive Regularization (PPCR) to constrain the continual learning with previous domain knowledge from the proxy prototypes. Simulate practical DCL scenarios, we devise two new protocols which evaluate both generalization and anti-forgetting performance. Extensive experimental results show that our proposed method can improve the generalization performance in unseen domains and alleviate the catastrophic forgetting of the previous knowledge. The codes and protocols will be released soon.
Generalized Few-Shot Continual Learning with Contrastive Mixture of Adapters
Feb 12, 2023



The goal of Few-Shot Continual Learning (FSCL) is to incrementally learn novel tasks with limited labeled samples and preserve previous capabilities simultaneously, while current FSCL methods are all for the class-incremental purpose. Moreover, the evaluation of FSCL solutions is only the cumulative performance of all encountered tasks, but there is no work on exploring the domain generalization ability. Domain generalization is a challenging yet practical task that aims to generalize beyond training domains. In this paper, we set up a Generalized FSCL (GFSCL) protocol involving both class- and domain-incremental situations together with the domain generalization assessment. Firstly, two benchmark datasets and protocols are newly arranged, and detailed baselines are provided for this unexplored configuration. We find that common continual learning methods have poor generalization ability on unseen domains and cannot better cope with the catastrophic forgetting issue in cross-incremental tasks. In this way, we further propose a rehearsal-free framework based on Vision Transformer (ViT) named Contrastive Mixture of Adapters (CMoA). Due to different optimization targets of class increment and domain increment, the CMoA contains two parts: (1) For the class-incremental issue, the Mixture of Adapters (MoA) module is incorporated into ViT, then cosine similarity regularization and the dynamic weighting are designed to make each adapter learn specific knowledge and concentrate on particular classes. (2) For the domain-related issues and domain-invariant representation learning, we alleviate the inner-class variation by prototype-calibrated contrastive learning. The codes and protocols are available at https://github.com/yawencui/CMoA.
Rethinking Vision Transformer and Masked Autoencoder in Multimodal Face Anti-Spoofing
Feb 11, 2023



Recently, vision transformer (ViT) based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, there are still no works to explore the fundamental natures (\textit{e.g.}, modality-aware inputs, suitable multimodal pre-training, and efficient finetuning) in vanilla ViT for multimodal FAS. In this paper, we investigate three key factors (i.e., inputs, pre-training, and finetuning) in ViT for multimodal FAS with RGB, Infrared (IR), and Depth. First, in terms of the ViT inputs, we find that leveraging local feature descriptors benefits the ViT on IR modality but not RGB or Depth modalities. Second, in observation of the inefficiency on direct finetuning the whole or partial ViT, we design an adaptive multimodal adapter (AMA), which can efficiently aggregate local multimodal features while freezing majority of ViT parameters. Finally, in consideration of the task (FAS vs. generic object classification) and modality (multimodal vs. unimodal) gaps, ImageNet pre-trained models might be sub-optimal for the multimodal FAS task. To bridge these gaps, we propose the modality-asymmetric masked autoencoder (M$^{2}$A$^{2}$E) for multimodal FAS self-supervised pre-training without costly annotated labels. Compared with the previous modality-symmetric autoencoder, the proposed M$^{2}$A$^{2}$E is able to learn more intrinsic task-aware representation and compatible with modality-agnostic (e.g., unimodal, bimodal, and trimodal) downstream settings. Extensive experiments with both unimodal (RGB, Depth, IR) and multimodal (RGB+Depth, RGB+IR, Depth+IR, RGB+Depth+IR) settings conducted on multimodal FAS benchmarks demonstrate the superior performance of the proposed methods. We hope these findings and solutions can facilitate the future research for ViT-based multimodal FAS.
PhysFormer++: Facial Video-based Physiological Measurement with SlowFast Temporal Difference Transformer
Feb 07, 2023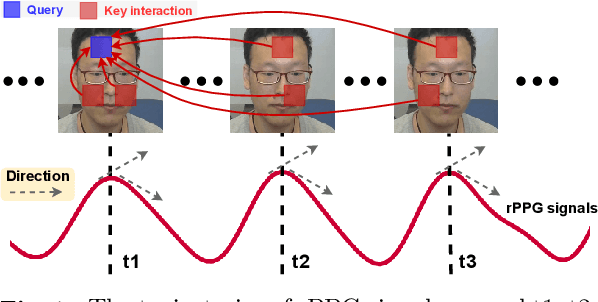

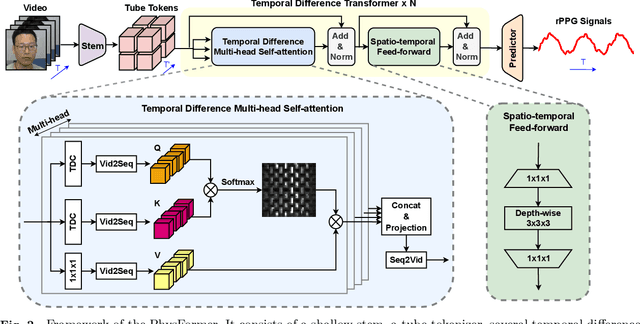
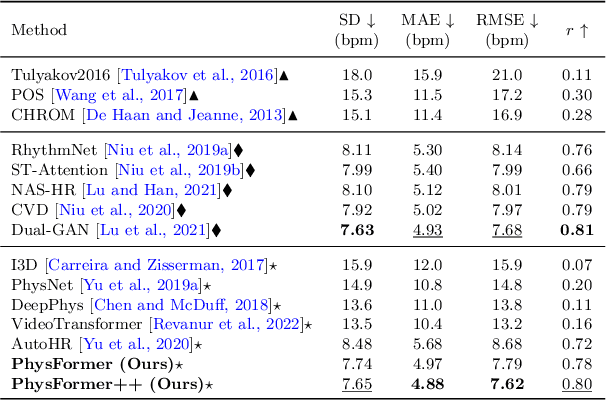
Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose two end-to-end video transformer based architectures, namely PhysFormer and PhysFormer++, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. To better exploit the temporal contextual and periodic rPPG clues, we also extend the PhysFormer to the two-pathway SlowFast based PhysFormer++ with temporal difference periodic and cross-attention transformers. Furthermore, we propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and PhysFormer++ and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. Unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer family can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community.
Uncertainty-Aware Distillation for Semi-Supervised Few-Shot Class-Incremental Learning
Jan 24, 2023



Given a model well-trained with a large-scale base dataset, Few-Shot Class-Incremental Learning (FSCIL) aims at incrementally learning novel classes from a few labeled samples by avoiding overfitting, without catastrophically forgetting all encountered classes previously. Currently, semi-supervised learning technique that harnesses freely-available unlabeled data to compensate for limited labeled data can boost the performance in numerous vision tasks, which heuristically can be applied to tackle issues in FSCIL, i.e., the Semi-supervised FSCIL (Semi-FSCIL). So far, very limited work focuses on the Semi-FSCIL task, leaving the adaptability issue of semi-supervised learning to the FSCIL task unresolved. In this paper, we focus on this adaptability issue and present a simple yet efficient Semi-FSCIL framework named Uncertainty-aware Distillation with Class-Equilibrium (UaD-CE), encompassing two modules UaD and CE. Specifically, when incorporating unlabeled data into each incremental session, we introduce the CE module that employs a class-balanced self-training to avoid the gradual dominance of easy-to-classified classes on pseudo-label generation. To distill reliable knowledge from the reference model, we further implement the UaD module that combines uncertainty-guided knowledge refinement with adaptive distillation. Comprehensive experiments on three benchmark datasets demonstrate that our method can boost the adaptability of unlabeled data with the semi-supervised learning technique in FSCIL tasks.