 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLap-Pui Chau
AOCIL: Exemplar-free Analytic Online Class Incremental Learning with Low Time and Resource Consumption
Mar 23, 2024
Online Class Incremental Learning (OCIL) aims to train the model in a task-by-task manner, where data arrive in mini-batches at a time while previous data are not accessible. A significant challenge is known as Catastrophic Forgetting, i.e., loss of the previous knowledge on old data. To address this, replay-based methods show competitive results but invade data privacy, while exemplar-free methods protect data privacy but struggle for accuracy. In this paper, we proposed an exemplar-free approach -- Analytic Online Class Incremental Learning (AOCIL). Instead of back-propagation, we design the Analytic Classifier (AC) updated by recursive least square, cooperating with a frozen backbone. AOCIL simultaneously achieves high accuracy, low resource consumption and data privacy protection. We conduct massive experiments on four existing benchmark datasets, and the results demonstrate the strong capability of handling OCIL scenarios. Codes will be ready.
SinSR: Diffusion-Based Image Super-Resolution in a Single Step
Nov 23, 2023
While super-resolution (SR) methods based on diffusion models exhibit promising results, their practical application is hindered by the substantial number of required inference steps. Recent methods utilize degraded images in the initial state, thereby shortening the Markov chain. Nevertheless, these solutions either rely on a precise formulation of the degradation process or still necessitate a relatively lengthy generation path (e.g., 15 iterations). To enhance inference speed, we propose a simple yet effective method for achieving single-step SR generation, named SinSR. Specifically, we first derive a deterministic sampling process from the most recent state-of-the-art (SOTA) method for accelerating diffusion-based SR. This allows the mapping between the input random noise and the generated high-resolution image to be obtained in a reduced and acceptable number of inference steps during training. We show that this deterministic mapping can be distilled into a student model that performs SR within only one inference step. Additionally, we propose a novel consistency-preserving loss to simultaneously leverage the ground-truth image during the distillation process, ensuring that the performance of the student model is not solely bound by the feature manifold of the teacher model, resulting in further performance improvement. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method can achieve comparable or even superior performance compared to both previous SOTA methods and the teacher model, in just one sampling step, resulting in a remarkable up to x10 speedup for inference. Our code will be released at https://github.com/wyf0912/SinSR
Bitstream-Corrupted Video Recovery: A Novel Benchmark Dataset and Method
Sep 26, 2023
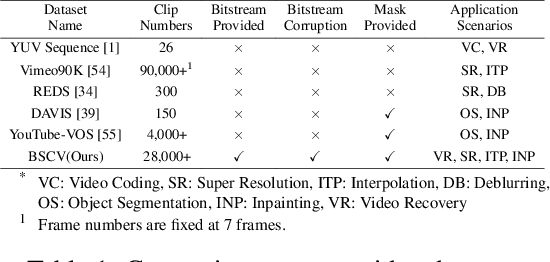

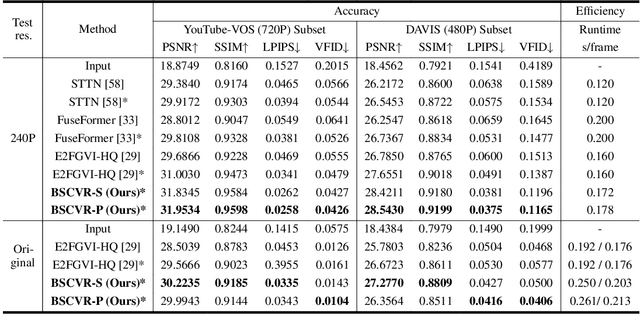
The past decade has witnessed great strides in video recovery by specialist technologies, like video inpainting, completion, and error concealment. However, they typically simulate the missing content by manual-designed error masks, thus failing to fill in the realistic video loss in video communication (e.g., telepresence, live streaming, and internet video) and multimedia forensics. To address this, we introduce the bitstream-corrupted video (BSCV) benchmark, the first benchmark dataset with more than 28,000 video clips, which can be used for bitstream-corrupted video recovery in the real world. The BSCV is a collection of 1) a proposed three-parameter corruption model for video bitstream, 2) a large-scale dataset containing rich error patterns, multiple corruption levels, and flexible dataset branches, and 3) a plug-and-play module in video recovery framework that serves as a benchmark. We evaluate state-of-the-art video inpainting methods on the BSCV dataset, demonstrating existing approaches' limitations and our framework's advantages in solving the bitstream-corrupted video recovery problem. The benchmark and dataset are released at https://github.com/LIUTIGHE/BSCV-Dataset.
ExposureDiffusion: Learning to Expose for Low-light Image Enhancement
Jul 15, 2023

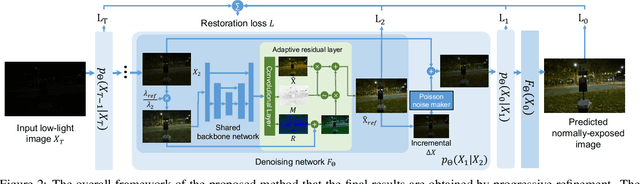
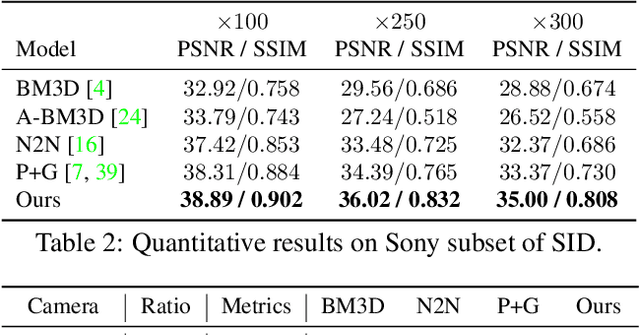
Previous raw image-based low-light image enhancement methods predominantly relied on feed-forward neural networks to learn deterministic mappings from low-light to normally-exposed images. However, they failed to capture critical distribution information, leading to visually undesirable results. This work addresses the issue by seamlessly integrating a diffusion model with a physics-based exposure model. Different from a vanilla diffusion model that has to perform Gaussian denoising, with the injected physics-based exposure model, our restoration process can directly start from a noisy image instead of pure noise. As such, our method obtains significantly improved performance and reduced inference time compared with vanilla diffusion models. To make full use of the advantages of different intermediate steps, we further propose an adaptive residual layer that effectively screens out the side-effect in the iterative refinement when the intermediate results have been already well-exposed. The proposed framework can work with both real-paired datasets, SOTA noise models, and different backbone networks. Note that, the proposed framework is compatible with real-paired datasets, real/synthetic noise models, and different backbone networks. We evaluate the proposed method on various public benchmarks, achieving promising results with consistent improvements using different exposure models and backbones. Besides, the proposed method achieves better generalization capacity for unseen amplifying ratios and better performance than a larger feedforward neural model when few parameters are adopted.
A Comprehensive Study on the Robustness of Image Classification and Object Detection in Remote Sensing: Surveying and Benchmarking
Jun 21, 2023



Deep neural networks (DNNs) have found widespread applications in interpreting remote sensing (RS) imagery. However, it has been demonstrated in previous works that DNNs are vulnerable to different types of noises, particularly adversarial noises. Surprisingly, there has been a lack of comprehensive studies on the robustness of RS tasks, prompting us to undertake a thorough survey and benchmark on the robustness of image classification and object detection in RS. To our best knowledge, this study represents the first comprehensive examination of both natural robustness and adversarial robustness in RS tasks. Specifically, we have curated and made publicly available datasets that contain natural and adversarial noises. These datasets serve as valuable resources for evaluating the robustness of DNNs-based models. To provide a comprehensive assessment of model robustness, we conducted meticulous experiments with numerous different classifiers and detectors, encompassing a wide range of mainstream methods. Through rigorous evaluation, we have uncovered insightful and intriguing findings, which shed light on the relationship between adversarial noise crafting and model training, yielding a deeper understanding of the susceptibility and limitations of various models, and providing guidance for the development of more resilient and robust models
Beyond Learned Metadata-based Raw Image Reconstruction
Jun 21, 2023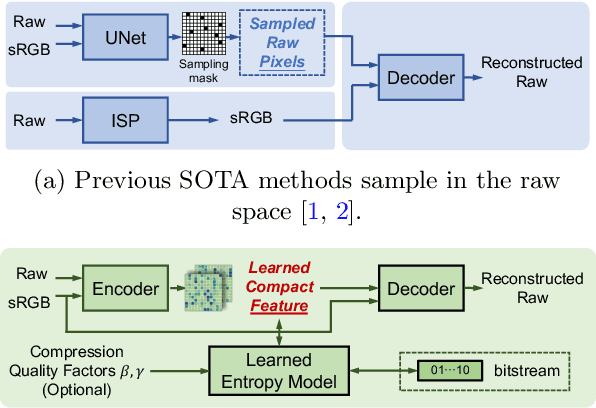
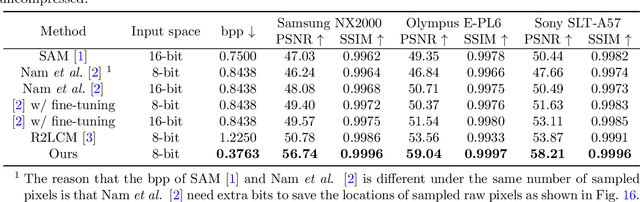
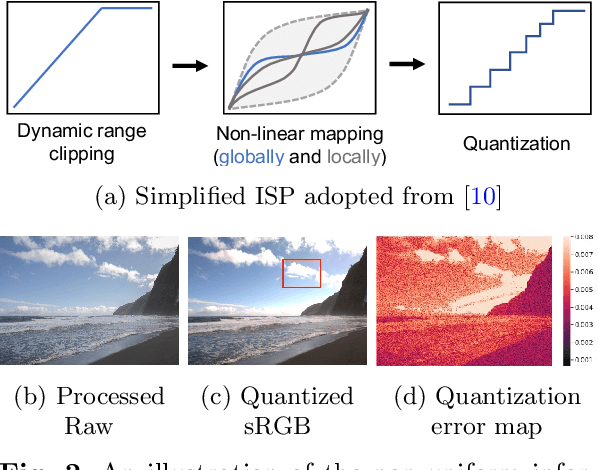
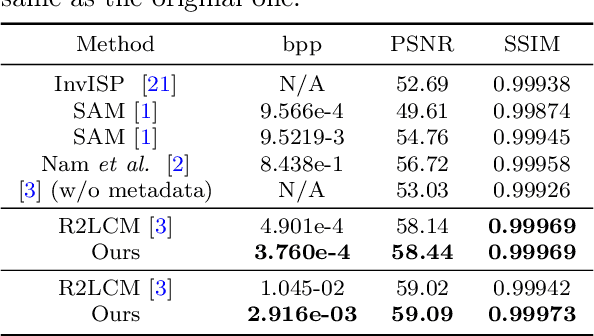
While raw images have distinct advantages over sRGB images, e.g., linearity and fine-grained quantization levels, they are not widely adopted by general users due to their substantial storage requirements. Very recent studies propose to compress raw images by designing sampling masks within the pixel space of the raw image. However, these approaches often leave space for pursuing more effective image representations and compact metadata. In this work, we propose a novel framework that learns a compact representation in the latent space, serving as metadata, in an end-to-end manner. Compared with lossy image compression, we analyze the intrinsic difference of the raw image reconstruction task caused by rich information from the sRGB image. Based on the analysis, a novel backbone design with asymmetric and hybrid spatial feature resolutions is proposed, which significantly improves the rate-distortion performance. Besides, we propose a novel design of the context model, which can better predict the order masks of encoding/decoding based on both the sRGB image and the masks of already processed features. Benefited from the better modeling of the correlation between order masks, the already processed information can be better utilized. Moreover, a novel sRGB-guided adaptive quantization precision strategy, which dynamically assigns varying levels of quantization precision to different regions, further enhances the representation ability of the model. Finally, based on the iterative properties of the proposed context model, we propose a novel strategy to achieve variable bit rates using a single model. This strategy allows for the continuous convergence of a wide range of bit rates. Extensive experimental results demonstrate that the proposed method can achieve better reconstruction quality with a smaller metadata size.
A Byte Sequence is Worth an Image: CNN for File Fragment Classification Using Bit Shift and n-Gram Embeddings
Apr 14, 2023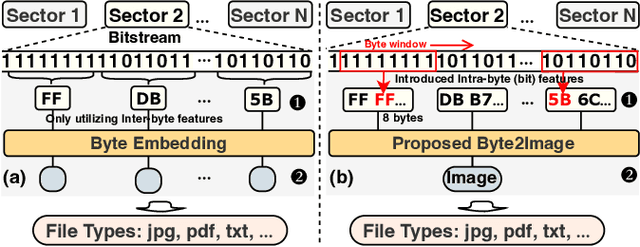
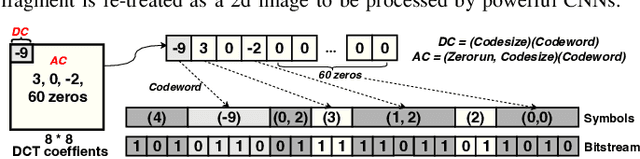
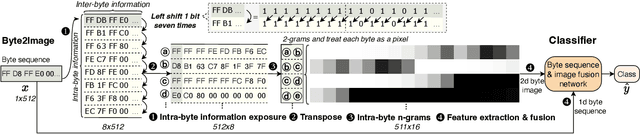
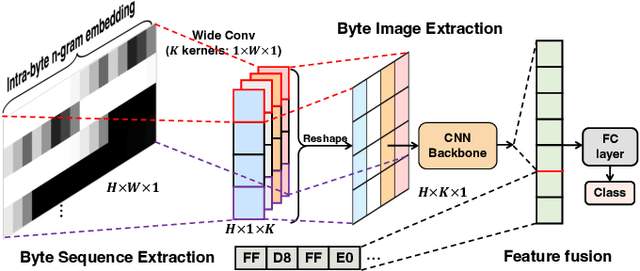
File fragment classification (FFC) on small chunks of memory is essential in memory forensics and Internet security. Existing methods mainly treat file fragments as 1d byte signals and utilize the captured inter-byte features for classification, while the bit information within bytes, i.e., intra-byte information, is seldom considered. This is inherently inapt for classifying variable-length coding files whose symbols are represented as the variable number of bits. Conversely, we propose Byte2Image, a novel data augmentation technique, to introduce the neglected intra-byte information into file fragments and re-treat them as 2d gray-scale images, which allows us to capture both inter-byte and intra-byte correlations simultaneously through powerful convolutional neural networks (CNNs). Specifically, to convert file fragments to 2d images, we employ a sliding byte window to expose the neglected intra-byte information and stack their n-gram features row by row. We further propose a byte sequence \& image fusion network as a classifier, which can jointly model the raw 1d byte sequence and the converted 2d image to perform FFC. Experiments on FFT-75 dataset validate that our proposed method can achieve notable accuracy improvements over state-of-the-art methods in nearly all scenarios. The code will be released at https://github.com/wenyang001/Byte2Image.
Bitstream-Corrupted JPEG Images are Restorable: Two-stage Compensation and Alignment Framework for Image Restoration
Apr 14, 2023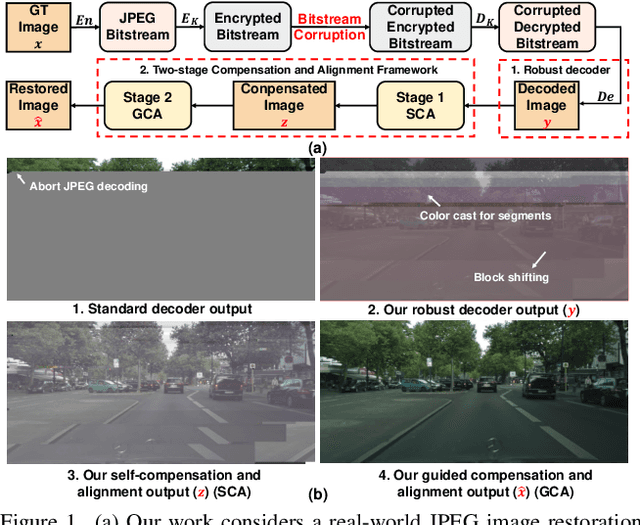
In this paper, we study a real-world JPEG image restoration problem with bit errors on the encrypted bitstream. The bit errors bring unpredictable color casts and block shifts on decoded image contents, which cannot be resolved by existing image restoration methods mainly relying on pre-defined degradation models in the pixel domain. To address these challenges, we propose a robust JPEG decoder, followed by a two-stage compensation and alignment framework to restore bitstream-corrupted JPEG images. Specifically, the robust JPEG decoder adopts an error-resilient mechanism to decode the corrupted JPEG bitstream. The two-stage framework is composed of the self-compensation and alignment (SCA) stage and the guided-compensation and alignment (GCA) stage. The SCA adaptively performs block-wise image color compensation and alignment based on the estimated color and block offsets via image content similarity. The GCA leverages the extracted low-resolution thumbnail from the JPEG header to guide full-resolution pixel-wise image restoration in a coarse-to-fine manner. It is achieved by a coarse-guided pix2pix network and a refine-guided bi-directional Laplacian pyramid fusion network. We conduct experiments on three benchmarks with varying degrees of bit error rates. Experimental results and ablation studies demonstrate the superiority of our proposed method. The code will be released at https://github.com/wenyang001/Two-ACIR.
Raw Image Reconstruction with Learned Compact Metadata
Feb 28, 2023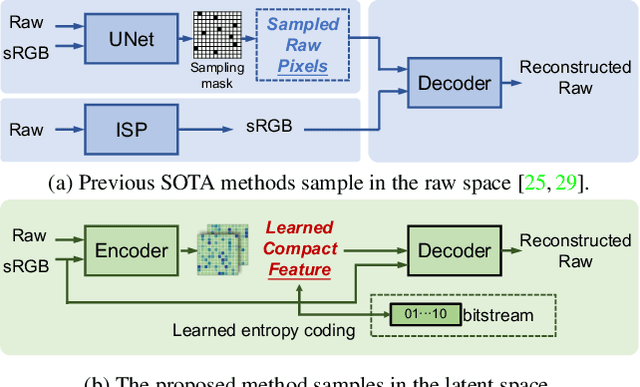
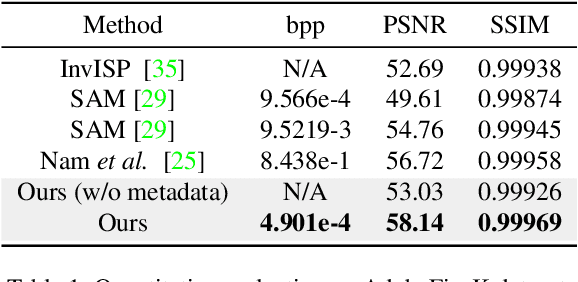
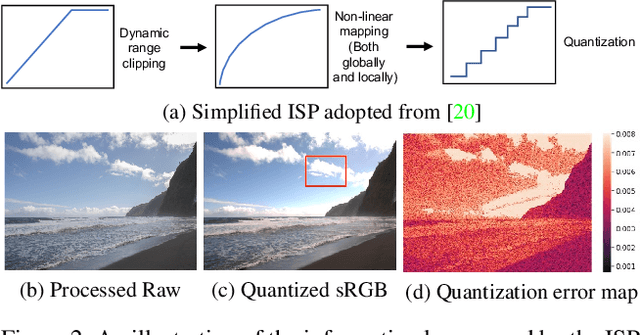
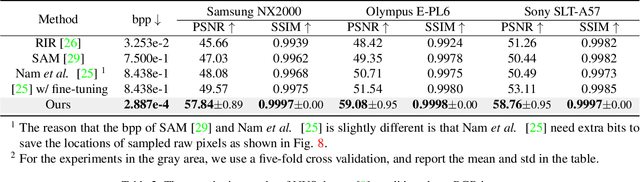
While raw images exhibit advantages over sRGB images (e.g., linearity and fine-grained quantization level), they are not widely used by common users due to the large storage requirements. Very recent works propose to compress raw images by designing the sampling masks in the raw image pixel space, leading to suboptimal image representations and redundant metadata. In this paper, we propose a novel framework to learn a compact representation in the latent space serving as the metadata in an end-to-end manner. Furthermore, we propose a novel sRGB-guided context model with improved entropy estimation strategies, which leads to better reconstruction quality, smaller size of metadata, and faster speed. We illustrate how the proposed raw image compression scheme can adaptively allocate more bits to image regions that are important from a global perspective. The experimental results show that the proposed method can achieve superior raw image reconstruction results using a smaller size of the metadata on both uncompressed sRGB images and JPEG images.
On the Simulation of Perception Errors in Autonomous Vehicles
Feb 23, 2023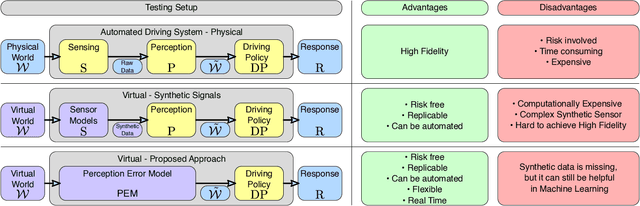
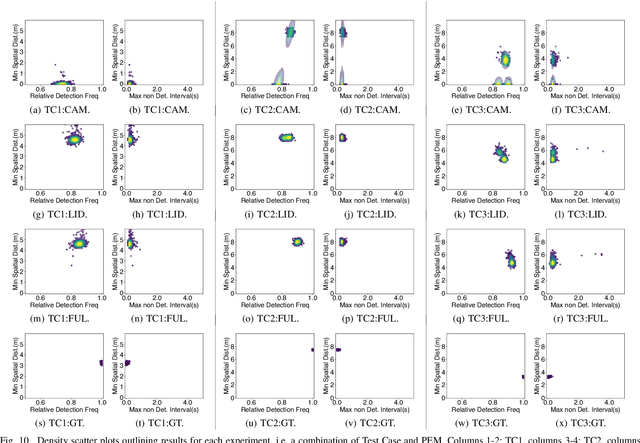
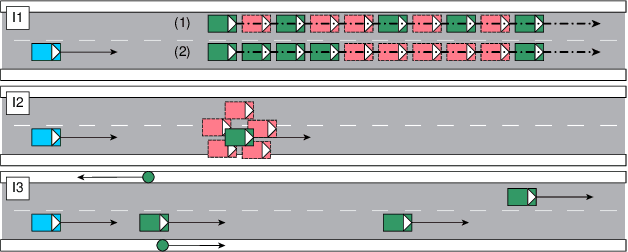
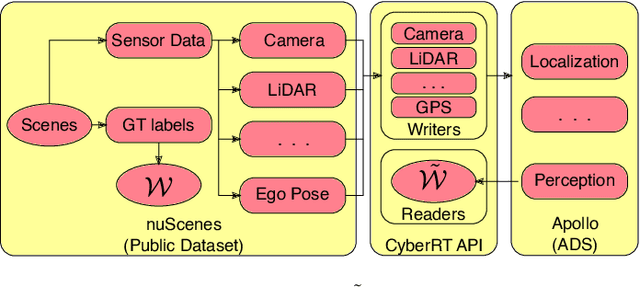
Even though virtual testing of Autonomous Vehicles (AVs) has been well recognized as essential for safety assessment, AV simulators are still undergoing active development. One particularly challenging question is to effectively include the Sensing and Perception (S&P) subsystem into the simulation loop. In this article, we define Perception Error Models (PEM), a virtual simulation component that can enable the analysis of the impact of perception errors on AV safety, without the need to model the sensors themselves. We propose a generalized data-driven procedure towards parametric modeling and evaluate it using Apollo, an open-source driving software, and nuScenes, a public AV dataset. Additionally, we implement PEMs in SVL, an open-source vehicle simulator. Furthermore, we demonstrate the usefulness of PEM-based virtual tests, by evaluating camera, LiDAR, and camera-LiDAR setups. Our virtual tests highlight limitations in the current evaluation metrics, and the proposed approach can help study the impact of perception errors on AV safety.