 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhong Ji
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024
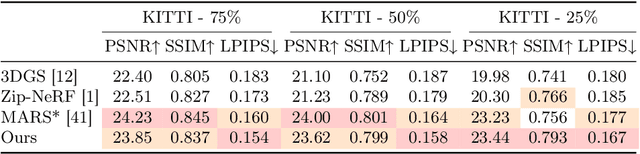

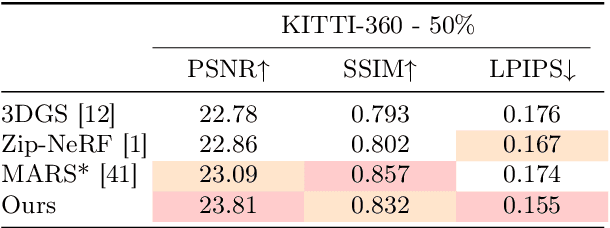
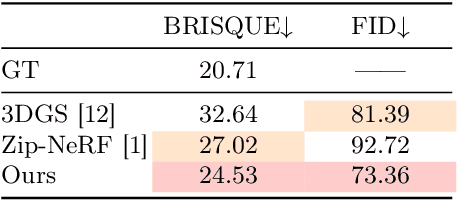
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
NTK-Guided Few-Shot Class Incremental Learning
Mar 19, 2024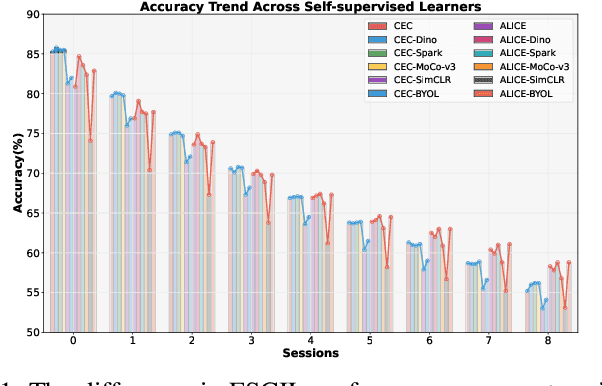
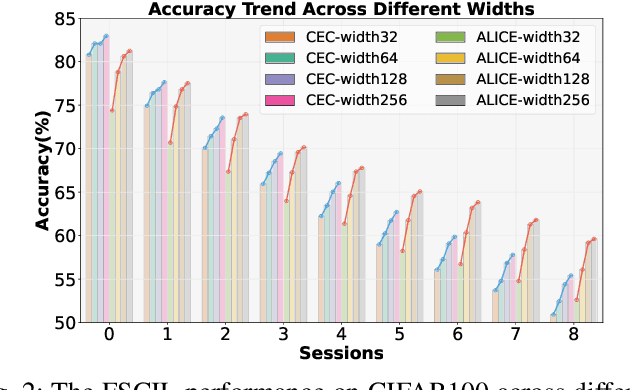
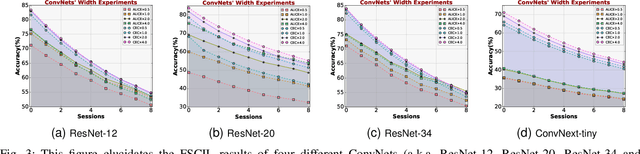
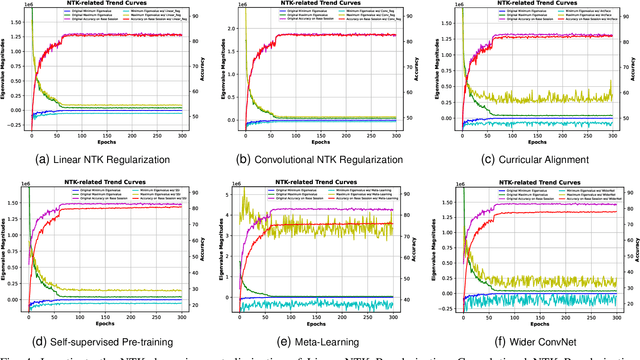
While anti-amnesia FSCIL learners often excel in incremental sessions, they tend to prioritize mitigating knowledge attrition over harnessing the model's potential for knowledge acquisition. In this paper, we delve into the foundations of model generalization in FSCIL through the lens of the Neural Tangent Kernel (NTK). Our primary design focus revolves around ensuring optimal NTK convergence and NTK-related generalization error, serving as the theoretical bedrock for exceptional generalization. To attain globally optimal NTK convergence, we employ a meta-learning mechanism grounded in mathematical principles to guide the optimization process within an expanded network. Furthermore, to reduce the NTK-related generalization error, we commence from the foundational level, optimizing the relevant factors constituting its generalization loss. Specifically, we initiate self-supervised pre-training on the base session to shape the initial network weights. Then they are carefully refined through curricular alignment, followed by the application of dual NTK regularization tailored specifically for both convolutional and linear layers. Through the combined effects of these measures, our network acquires robust NTK properties, significantly enhancing its foundational generalization. On popular FSCIL benchmark datasets, our NTK-FSCIL surpasses contemporary state-of-the-art approaches, elevating end-session accuracy by 2.9% to 8.7%.
Hierarchical Matching and Reasoning for Multi-Query Image Retrieval
Jun 26, 2023
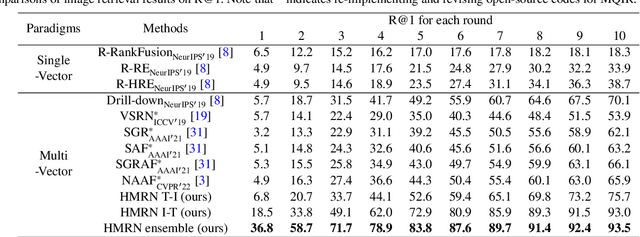
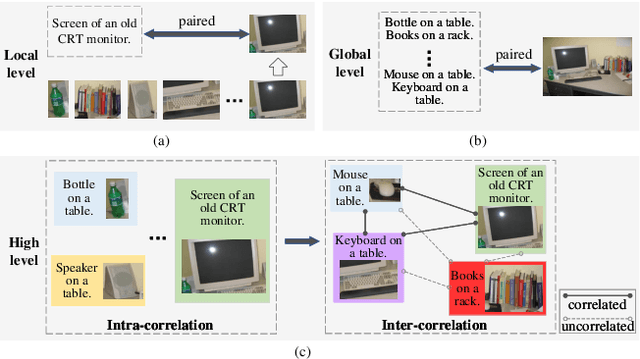
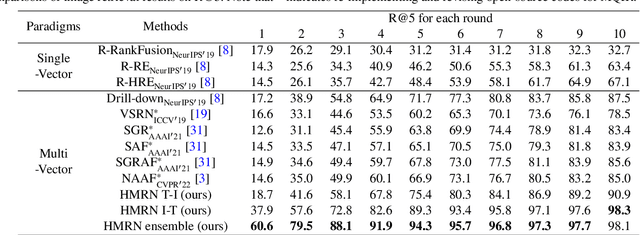
As a promising field, Multi-Query Image Retrieval (MQIR) aims at searching for the semantically relevant image given multiple region-specific text queries. Existing works mainly focus on a single-level similarity between image regions and text queries, which neglects the hierarchical guidance of multi-level similarities and results in incomplete alignments. Besides, the high-level semantic correlations that intrinsically connect different region-query pairs are rarely considered. To address above limitations, we propose a novel Hierarchical Matching and Reasoning Network (HMRN) for MQIR. It disentangles MQIR into three hierarchical semantic representations, which is responsible to capture fine-grained local details, contextual global scopes, and high-level inherent correlations. HMRN comprises two modules: Scalar-based Matching (SM) module and Vector-based Reasoning (VR) module. Specifically, the SM module characterizes the multi-level alignment similarity, which consists of a fine-grained local-level similarity and a context-aware global-level similarity. Afterwards, the VR module is developed to excavate the potential semantic correlations among multiple region-query pairs, which further explores the high-level reasoning similarity. Finally, these three-level similarities are aggregated into a joint similarity space to form the ultimate similarity. Extensive experiments on the benchmark dataset demonstrate that our HMRN substantially surpasses the current state-of-the-art methods. For instance, compared with the existing best method Drill-down, the metric R@1 in the last round is improved by 23.4%. Our source codes will be released at https://github.com/LZH-053/HMRN.
USER: Unified Semantic Enhancement with Momentum Contrast for Image-Text Retrieval
Jan 17, 2023
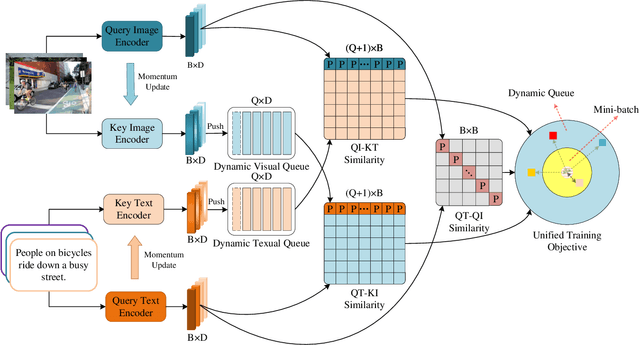
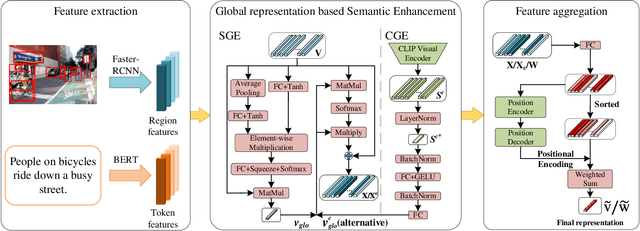

As a fundamental and challenging task in bridging language and vision domains, Image-Text Retrieval (ITR) aims at searching for the target instances that are semantically relevant to the given query from the other modality, and its key challenge is to measure the semantic similarity across different modalities. Although significant progress has been achieved, existing approaches typically suffer from two major limitations: (1) It hurts the accuracy of the representation by directly exploiting the bottom-up attention based region-level features where each region is equally treated. (2) It limits the scale of negative sample pairs by employing the mini-batch based end-to-end training mechanism. To address these limitations, we propose a Unified Semantic Enhancement Momentum Contrastive Learning (USER) method for ITR. Specifically, we delicately design two simple but effective Global representation based Semantic Enhancement (GSE) modules. One learns the global representation via the self-attention algorithm, noted as Self-Guided Enhancement (SGE) module. The other module benefits from the pre-trained CLIP module, which provides a novel scheme to exploit and transfer the knowledge from an off-the-shelf model, noted as CLIP-Guided Enhancement (CGE) module. Moreover, we incorporate the training mechanism of MoCo into ITR, in which two dynamic queues are employed to enrich and enlarge the scale of negative sample pairs. Meanwhile, a Unified Training Objective (UTO) is developed to learn from mini-batch based and dynamic queue based samples. Extensive experiments on the benchmark MSCOCO and Flickr30K datasets demonstrate the superiority of both retrieval accuracy and inference efficiency. Our source code will be released at https://github.com/zhangy0822/USER.
Conformal Loss-Controlling Prediction
Jan 06, 2023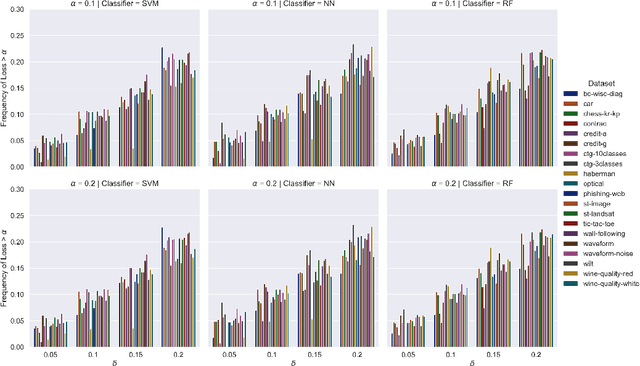
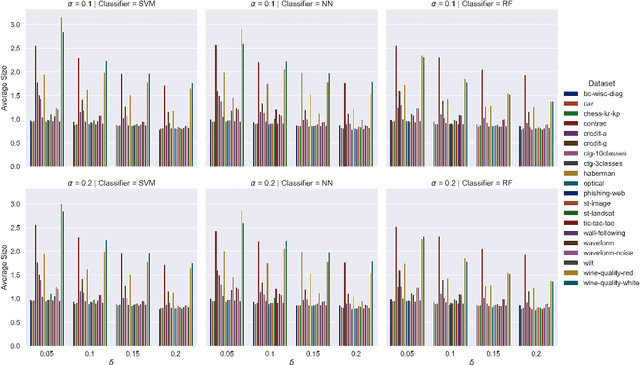

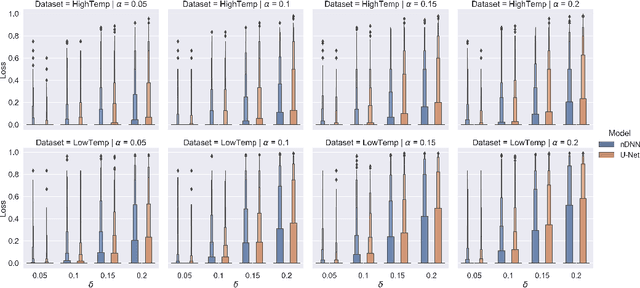
Conformal prediction is a learning framework controlling prediction coverage of prediction sets, which can be built on any learning algorithm for point prediction. This work proposes a learning framework named conformal loss-controlling prediction, which extends conformal prediction to the situation where the value of a loss function needs to be controlled. Different from existing works about risk-controlling prediction sets and conformal risk control with the purpose of controlling the expected values of loss functions, the proposed approach in this paper focuses on the loss for any test object, which is an extension of conformal prediction from miscoverage loss to some general loss. The controlling guarantee is proved under the assumption of exchangeability of data in finite-sample cases and the framework is tested empirically for classification with a class-varying loss and statistical postprocessing of numerical weather forecasting applications, which are introduced as point-wise classification and point-wise regression problems. All theoretical analysis and experimental results confirm the effectiveness of our loss-controlling approach.
Asymmetric Cross-Scale Alignment for Text-Based Person Search
Nov 26, 2022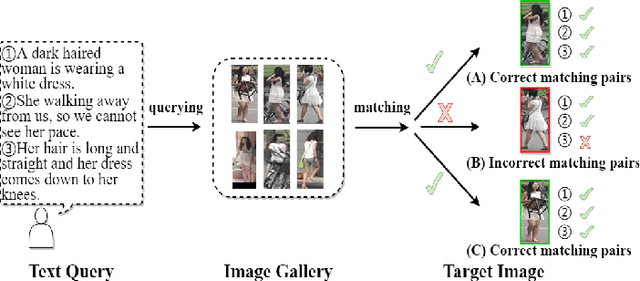
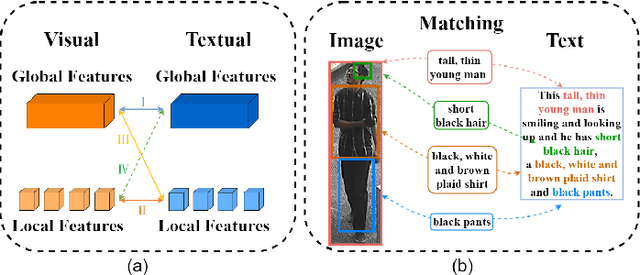
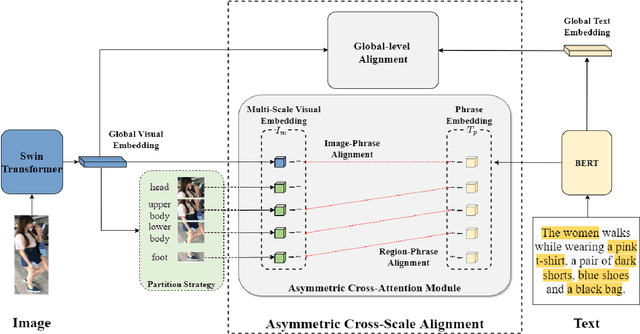
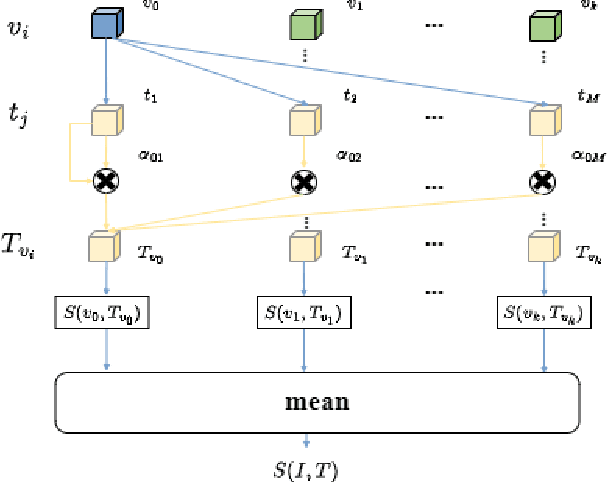
Text-based person search (TBPS) is of significant importance in intelligent surveillance, which aims to retrieve pedestrian images with high semantic relevance to a given text description. This retrieval task is characterized with both modal heterogeneity and fine-grained matching. To implement this task, one needs to extract multi-scale features from both image and text domains, and then perform the cross-modal alignment. However, most existing approaches only consider the alignment confined at their individual scales, e.g., an image-sentence or a region-phrase scale. Such a strategy adopts the presumable alignment in feature extraction, while overlooking the cross-scale alignment, e.g., image-phrase. In this paper, we present a transformer-based model to extract multi-scale representations, and perform Asymmetric Cross-Scale Alignment (ACSA) to precisely align the two modalities. Specifically, ACSA consists of a global-level alignment module and an asymmetric cross-attention module, where the former aligns an image and texts on a global scale, and the latter applies the cross-attention mechanism to dynamically align the cross-modal entities in region/image-phrase scales. Extensive experiments on two benchmark datasets CUHK-PEDES and RSTPReid demonstrate the effectiveness of our approach. Codes are available at \href{url}{https://github.com/mul-hjh/ACSA}.
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022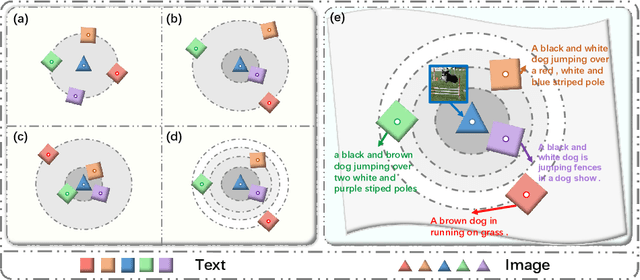
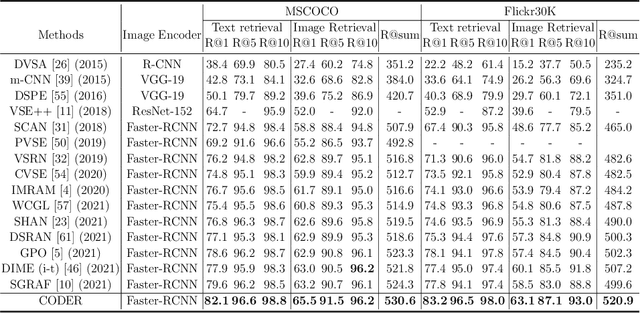
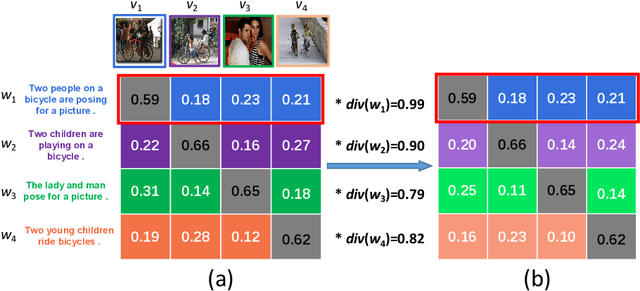
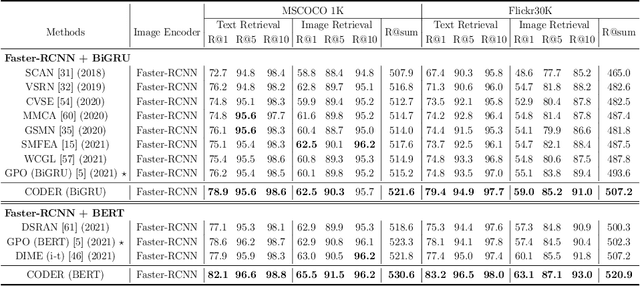
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.
Memorizing Complementation Network for Few-Shot Class-Incremental Learning
Aug 11, 2022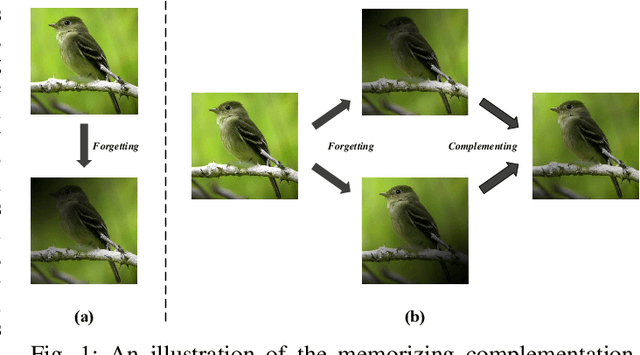
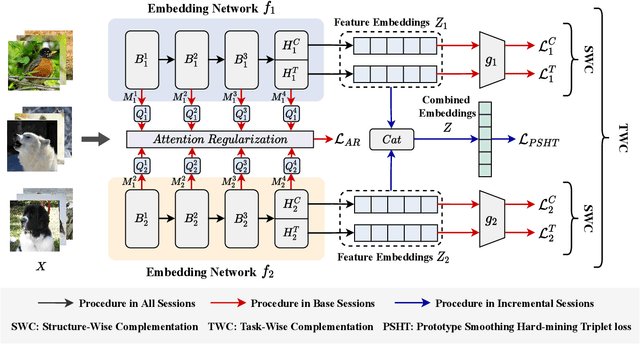
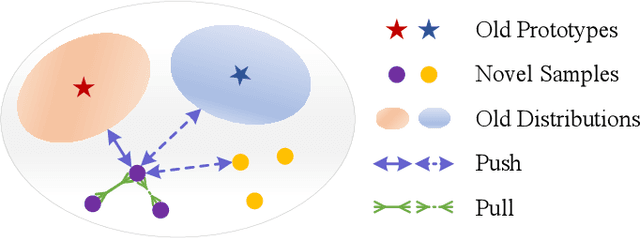
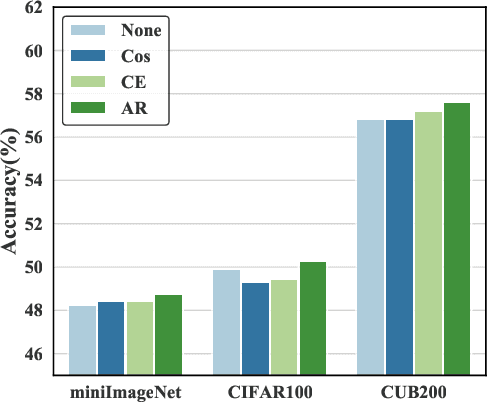
Few-shot Class-Incremental Learning (FSCIL) aims at learning new concepts continually with only a few samples, which is prone to suffer the catastrophic forgetting and overfitting problems. The inaccessibility of old classes and the scarcity of the novel samples make it formidable to realize the trade-off between retaining old knowledge and learning novel concepts. Inspired by that different models memorize different knowledge when learning novel concepts, we propose a Memorizing Complementation Network (MCNet) to ensemble multiple models that complements the different memorized knowledge with each other in novel tasks. Additionally, to update the model with few novel samples, we develop a Prototype Smoothing Hard-mining Triplet (PSHT) loss to push the novel samples away from not only each other in current task but also the old distribution. Extensive experiments on three benchmark datasets, e.g., CIFAR100, miniImageNet and CUB200, have demonstrated the superiority of our proposed method.
Boosting Video-Text Retrieval with Explicit High-Level Semantics
Aug 09, 2022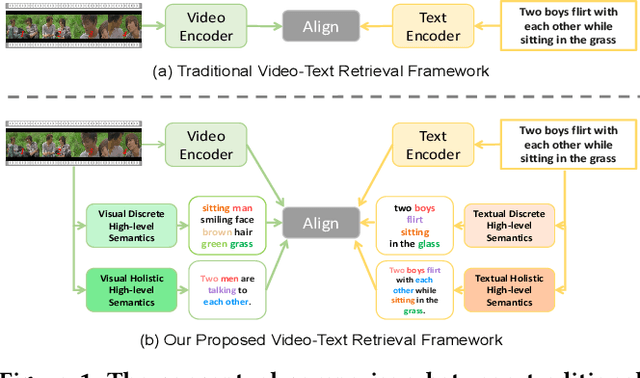
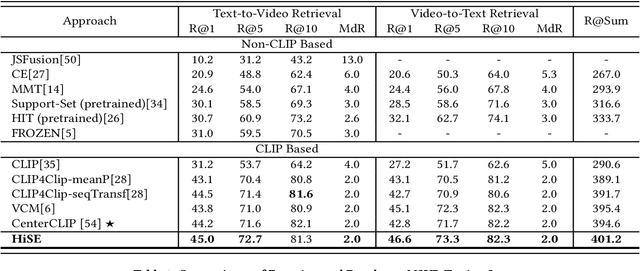
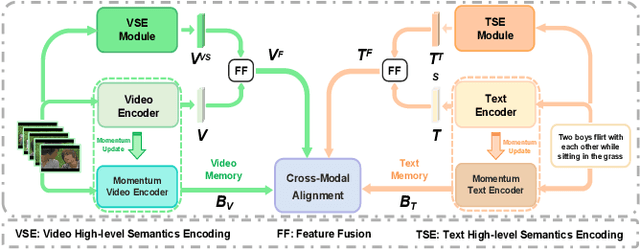

Video-text retrieval (VTR) is an attractive yet challenging task for multi-modal understanding, which aims to search for relevant video (text) given a query (video). Existing methods typically employ completely heterogeneous visual-textual information to align video and text, whilst lacking the awareness of homogeneous high-level semantic information residing in both modalities. To fill this gap, in this work, we propose a novel visual-linguistic aligning model named HiSE for VTR, which improves the cross-modal representation by incorporating explicit high-level semantics. First, we explore the hierarchical property of explicit high-level semantics, and further decompose it into two levels, i.e. discrete semantics and holistic semantics. Specifically, for visual branch, we exploit an off-the-shelf semantic entity predictor to generate discrete high-level semantics. In parallel, a trained video captioning model is employed to output holistic high-level semantics. As for the textual modality, we parse the text into three parts including occurrence, action and entity. In particular, the occurrence corresponds to the holistic high-level semantics, meanwhile both action and entity represent the discrete ones. Then, different graph reasoning techniques are utilized to promote the interaction between holistic and discrete high-level semantics. Extensive experiments demonstrate that, with the aid of explicit high-level semantics, our method achieves the superior performance over state-of-the-art methods on three benchmark datasets, including MSR-VTT, MSVD and DiDeMo.
Reinforced Pedestrian Attribute Recognition with Group Optimization Reward
May 21, 2022



Pedestrian Attribute Recognition (PAR) is a challenging task in intelligent video surveillance. Two key challenges in PAR include complex alignment relations between images and attributes, and imbalanced data distribution. Existing approaches usually formulate PAR as a recognition task. Different from them, this paper addresses it as a decision-making task via a reinforcement learning framework. Specifically, PAR is formulated as a Markov decision process (MDP) by designing ingenious states, action space, reward function and state transition. To alleviate the inter-attribute imbalance problem, we apply an Attribute Grouping Strategy (AGS) by dividing all attributes into subgroups according to their region and category information. Then we employ an agent to recognize each group of attributes, which is trained with Deep Q-learning algorithm. We also propose a Group Optimization Reward (GOR) function to alleviate the intra-attribute imbalance problem. Experimental results on the three benchmark datasets of PETA, RAP and PA100K illustrate the effectiveness and competitiveness of the proposed approach and demonstrate that the application of reinforcement learning to PAR is a valuable research direction.