 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMax Simchowitz
Butterfly Effects of SGD Noise: Error Amplification in Behavior Cloning and Autoregression
Oct 17, 2023
This work studies training instabilities of behavior cloning with deep neural networks. We observe that minibatch SGD updates to the policy network during training result in sharp oscillations in long-horizon rewards, despite negligibly affecting the behavior cloning loss. We empirically disentangle the statistical and computational causes of these oscillations, and find them to stem from the chaotic propagation of minibatch SGD noise through unstable closed-loop dynamics. While SGD noise is benign in the single-step action prediction objective, it results in catastrophic error accumulation over long horizons, an effect we term gradient variance amplification (GVA). We show that many standard mitigation techniques do not alleviate GVA, but find an exponential moving average (EMA) of iterates to be surprisingly effective at doing so. We illustrate the generality of this phenomenon by showing the existence of GVA and its amelioration by EMA in both continuous control and autoregressive language generation. Finally, we provide theoretical vignettes that highlight the benefits of EMA in alleviating GVA and shed light on the extent to which classical convex models can help in understanding the benefits of iterate averaging in deep learning.
Fleet Policy Learning via Weight Merging and An Application to Robotic Tool-Use
Oct 02, 2023Fleets of robots ingest massive amounts of streaming data generated by interacting with their environments, far more than those that can be stored or transmitted with ease. At the same time, we hope that teams of robots can co-acquire diverse skills through their experiences in varied settings. How can we enable such fleet-level learning without having to transmit or centralize fleet-scale data? In this paper, we investigate distributed learning of policies as a potential solution. To efficiently merge policies in the distributed setting, we propose fleet-merge, an instantiation of distributed learning that accounts for the symmetries that can arise in learning policies that are parameterized by recurrent neural networks. We show that fleet-merge consolidates the behavior of policies trained on 50 tasks in the Meta-World environment, with the merged policy achieving good performance on nearly all training tasks at test time. Moreover, we introduce a novel robotic tool-use benchmark, fleet-tools, for fleet policy learning in compositional and contact-rich robot manipulation tasks, which might be of broader interest, and validate the efficacy of fleet-merge on the benchmark.
Constrained Bimanual Planning with Analytic Inverse Kinematics
Sep 15, 2023In order for a bimanual robot to manipulate an object that is held by both hands, it must construct motion plans such that the transformation between its end effectors remains fixed. This amounts to complicated nonlinear equality constraints in the configuration space, which are difficult for trajectory optimizers. In addition, the set of feasible configurations becomes a measure zero set, which presents a challenge to sampling-based motion planners. We leverage an analytic solution to the inverse kinematics problem to parametrize the configuration space, resulting in a lower-dimensional representation where the set of valid configurations has positive measure. We describe how to use this parametrization with existing algorithms for motion planning, including sampling-based approaches, trajectory optimizers, and techniques that plan through convex inner-approximations of collision-free space.
RePo: Resilient Model-Based Reinforcement Learning by Regularizing Posterior Predictability
Aug 31, 2023
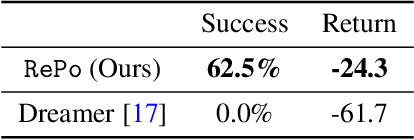
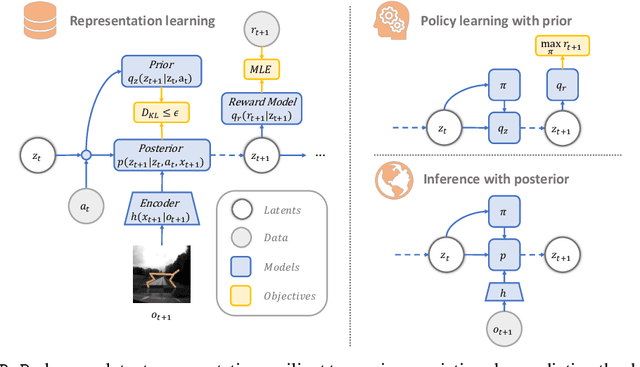
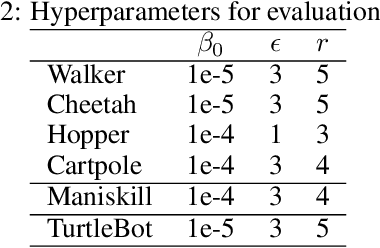
Visual model-based RL methods typically encode image observations into low-dimensional representations in a manner that does not eliminate redundant information. This leaves them susceptible to spurious variations -- changes in task-irrelevant components such as background distractors or lighting conditions. In this paper, we propose a visual model-based RL method that learns a latent representation resilient to such spurious variations. Our training objective encourages the representation to be maximally predictive of dynamics and reward, while constraining the information flow from the observation to the latent representation. We demonstrate that this objective significantly bolsters the resilience of visual model-based RL methods to visual distractors, allowing them to operate in dynamic environments. We then show that while the learned encoder is resilient to spirious variations, it is not invariant under significant distribution shift. To address this, we propose a simple reward-free alignment procedure that enables test time adaptation of the encoder. This allows for quick adaptation to widely differing environments without having to relearn the dynamics and policy. Our effort is a step towards making model-based RL a practical and useful tool for dynamic, diverse domains. We show its effectiveness in simulation benchmarks with significant spurious variations as well as a real-world egocentric navigation task with noisy TVs in the background. Videos and code at https://zchuning.github.io/repo-website/.
Imitating Complex Trajectories: Bridging Low-Level Stability and High-Level Behavior
Jul 29, 2023We propose a theoretical framework for studying the imitation of stochastic, non-Markovian, potentially multi-modal (i.e. "complex" ) expert demonstrations in nonlinear dynamical systems. Our framework invokes low-level controllers - either learned or implicit in position-command control - to stabilize imitation policies around expert demonstrations. We show that with (a) a suitable low-level stability guarantee and (b) a stochastic continuity property of the learned policy we call "total variation continuity" (TVC), an imitator that accurately estimates actions on the demonstrator's state distribution closely matches the demonstrator's distribution over entire trajectories. We then show that TVC can be ensured with minimal degradation of accuracy by combining a popular data-augmentation regimen with a novel algorithmic trick: adding augmentation noise at execution time. We instantiate our guarantees for policies parameterized by diffusion models and prove that if the learner accurately estimates the score of the (noise-augmented) expert policy, then the distribution of imitator trajectories is close to the demonstrator distribution in a natural optimal transport distance. Our analysis constructs intricate couplings between noise-augmented trajectories, a technique that may be of independent interest. We conclude by empirically validating our algorithmic recommendations.
Tackling Combinatorial Distribution Shift: A Matrix Completion Perspective
Jul 28, 2023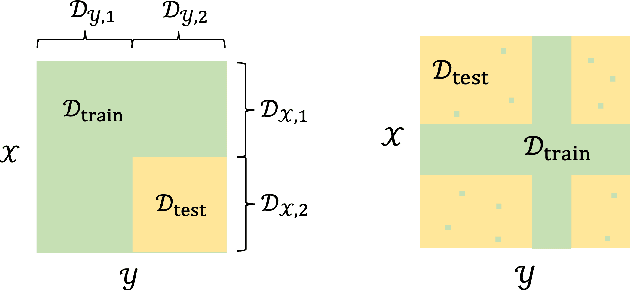
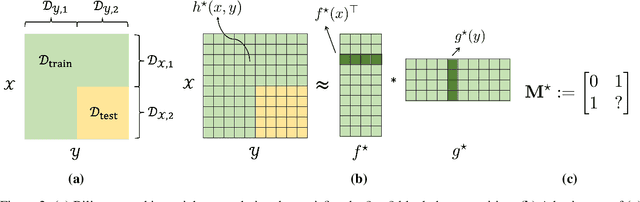
Obtaining rigorous statistical guarantees for generalization under distribution shift remains an open and active research area. We study a setting we call combinatorial distribution shift, where (a) under the test- and training-distributions, the labels $z$ are determined by pairs of features $(x,y)$, (b) the training distribution has coverage of certain marginal distributions over $x$ and $y$ separately, but (c) the test distribution involves examples from a product distribution over $(x,y)$ that is {not} covered by the training distribution. Focusing on the special case where the labels are given by bilinear embeddings into a Hilbert space $H$: $\mathbb{E}[z \mid x,y ]=\langle f_{\star}(x),g_{\star}(y)\rangle_{{H}}$, we aim to extrapolate to a test distribution domain that is $not$ covered in training, i.e., achieving bilinear combinatorial extrapolation. Our setting generalizes a special case of matrix completion from missing-not-at-random data, for which all existing results require the ground-truth matrices to be either exactly low-rank, or to exhibit very sharp spectral cutoffs. In this work, we develop a series of theoretical results that enable bilinear combinatorial extrapolation under gradual spectral decay as observed in typical high-dimensional data, including novel algorithms, generalization guarantees, and linear-algebraic results. A key tool is a novel perturbation bound for the rank-$k$ singular value decomposition approximations between two matrices that depends on the relative spectral gap rather than the absolute spectral gap, a result that may be of broader independent interest.
The Power of Learned Locally Linear Models for Nonlinear Policy Optimization
May 16, 2023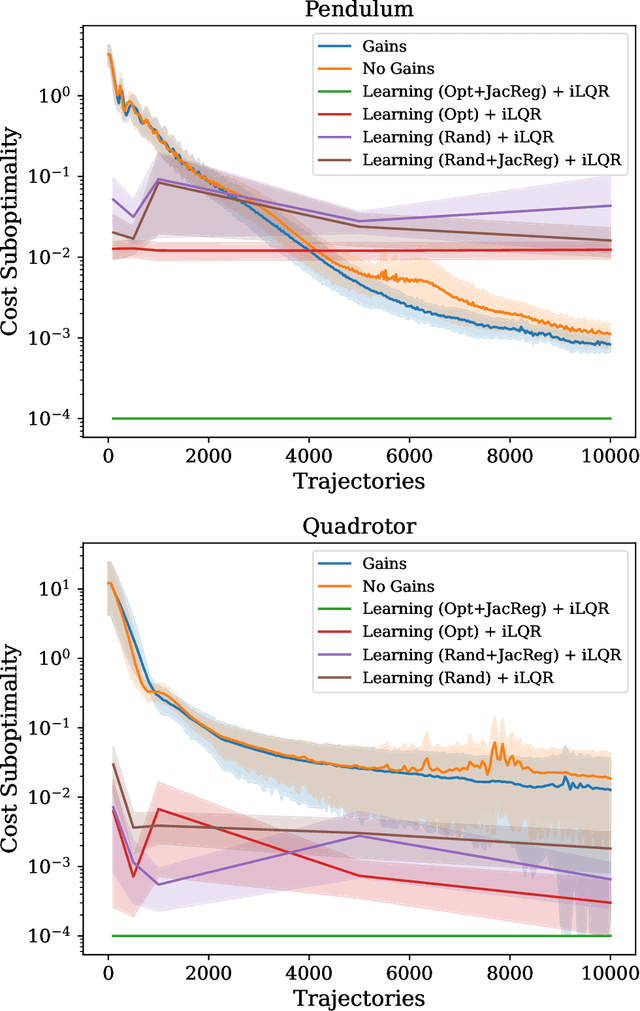
A common pipeline in learning-based control is to iteratively estimate a model of system dynamics, and apply a trajectory optimization algorithm - e.g.~$\mathtt{iLQR}$ - on the learned model to minimize a target cost. This paper conducts a rigorous analysis of a simplified variant of this strategy for general nonlinear systems. We analyze an algorithm which iterates between estimating local linear models of nonlinear system dynamics and performing $\mathtt{iLQR}$-like policy updates. We demonstrate that this algorithm attains sample complexity polynomial in relevant problem parameters, and, by synthesizing locally stabilizing gains, overcomes exponential dependence in problem horizon. Experimental results validate the performance of our algorithm, and compare to natural deep-learning baselines.
Non-Euclidean Motion Planning with Graphs of Geodesically-Convex Sets
May 11, 2023

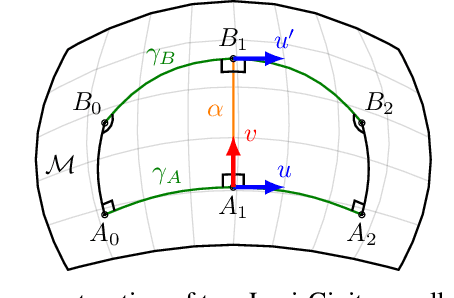
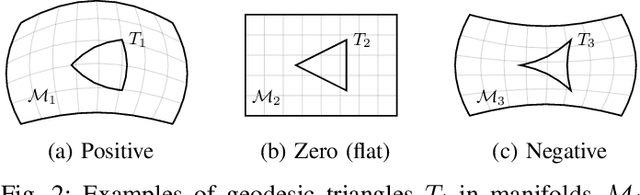
Computing optimal, collision-free trajectories for high-dimensional systems is a challenging problem. Sampling-based planners struggle with the dimensionality, whereas trajectory optimizers may get stuck in local minima due to inherent nonconvexities in the optimization landscape. The use of mixed-integer programming to encapsulate these nonconvexities and find globally optimal trajectories has recently shown great promise, thanks in part to tight convex relaxations and efficient approximation strategies that greatly reduce runtimes. These approaches were previously limited to Euclidean configuration spaces, precluding their use with mobile bases or continuous revolute joints. In this paper, we handle such scenarios by modeling configuration spaces as Riemannian manifolds, and we describe a reduction procedure for the zero-curvature case to a mixed-integer convex optimization problem. We demonstrate our results on various robot platforms, including producing efficient collision-free trajectories for a PR2 bimanual mobile manipulator.