 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZicheng Liu
LongVQ: Long Sequence Modeling with Vector Quantization on Structured Memory
Apr 18, 2024
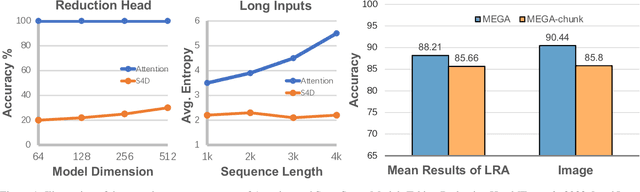



Transformer models have been successful in various sequence processing tasks, but the self-attention mechanism's computational cost limits its practicality for long sequences. Although there are existing attention variants that improve computational efficiency, they have a limited ability to abstract global information effectively based on their hand-crafted mixing strategies. On the other hand, state-space models (SSMs) are tailored for long sequences but cannot capture complicated local information. Therefore, the combination of them as a unified token mixer is a trend in recent long-sequence models. However, the linearized attention degrades performance significantly even when equipped with SSMs. To address the issue, we propose a new method called LongVQ. LongVQ uses the vector quantization (VQ) technique to compress the global abstraction as a length-fixed codebook, enabling the linear-time computation of the attention matrix. This technique effectively maintains dynamic global and local patterns, which helps to complement the lack of long-range dependency issues. Our experiments on the Long Range Arena benchmark, autoregressive language modeling, and image and speech classification demonstrate the effectiveness of LongVQ. Our model achieves significant improvements over other sequence models, including variants of Transformers, Convolutions, and recent State Space Models.
A robust assessment for invariant representations
Apr 07, 2024The performance of machine learning models can be impacted by changes in data over time. A promising approach to address this challenge is invariant learning, with a particular focus on a method known as invariant risk minimization (IRM). This technique aims to identify a stable data representation that remains effective with out-of-distribution (OOD) data. While numerous studies have developed IRM-based methods adaptive to data augmentation scenarios, there has been limited attention on directly assessing how well these representations preserve their invariant performance under varying conditions. In our paper, we propose a novel method to evaluate invariant performance, specifically tailored for IRM-based methods. We establish a bridge between the conditional expectation of an invariant predictor across different environments through the likelihood ratio. Our proposed criterion offers a robust basis for evaluating invariant performance. We validate our approach with theoretical support and demonstrate its effectiveness through extensive numerical studies.These experiments illustrate how our method can assess the invariant performance of various representation techniques.
Switch EMA: A Free Lunch for Better Flatness and Sharpness
Feb 14, 2024Exponential Moving Average (EMA) is a widely used weight averaging (WA) regularization to learn flat optima for better generalizations without extra cost in deep neural network (DNN) optimization. Despite achieving better flatness, existing WA methods might fall into worse final performances or require extra test-time computations. This work unveils the full potential of EMA with a single line of modification, i.e., switching the EMA parameters to the original model after each epoch, dubbed as Switch EMA (SEMA). From both theoretical and empirical aspects, we demonstrate that SEMA can help DNNs to reach generalization optima that better trade-off between flatness and sharpness. To verify the effectiveness of SEMA, we conduct comparison experiments with discriminative, generative, and regression tasks on vision and language datasets, including image classification, self-supervised learning, object detection and segmentation, image generation, video prediction, attribute regression, and language modeling. Comprehensive results with popular optimizers and networks show that SEMA is a free lunch for DNN training by improving performances and boosting convergence speeds.
PSC-CPI: Multi-Scale Protein Sequence-Structure Contrasting for Efficient and Generalizable Compound-Protein Interaction Prediction
Feb 13, 2024Compound-Protein Interaction (CPI) prediction aims to predict the pattern and strength of compound-protein interactions for rational drug discovery. Existing deep learning-based methods utilize only the single modality of protein sequences or structures and lack the co-modeling of the joint distribution of the two modalities, which may lead to significant performance drops in complex real-world scenarios due to various factors, e.g., modality missing and domain shifting. More importantly, these methods only model protein sequences and structures at a single fixed scale, neglecting more fine-grained multi-scale information, such as those embedded in key protein fragments. In this paper, we propose a novel multi-scale Protein Sequence-structure Contrasting framework for CPI prediction (PSC-CPI), which captures the dependencies between protein sequences and structures through both intra-modality and cross-modality contrasting. We further apply length-variable protein augmentation to allow contrasting to be performed at different scales, from the amino acid level to the sequence level. Finally, in order to more fairly evaluate the model generalizability, we split the test data into four settings based on whether compounds and proteins have been observed during the training stage. Extensive experiments have shown that PSC-CPI generalizes well in all four settings, particularly in the more challenging ``Unseen-Both" setting, where neither compounds nor proteins have been observed during training. Furthermore, even when encountering a situation of modality missing, i.e., inference with only single-modality protein data, PSC-CPI still exhibits comparable or even better performance than previous approaches.
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis
Jan 30, 2024To leverage LLMs for visual synthesis, traditional methods convert raster image information into discrete grid tokens through specialized visual modules, while disrupting the model's ability to capture the true semantic representation of visual scenes. This paper posits that an alternative representation of images, vector graphics, can effectively surmount this limitation by enabling a more natural and semantically coherent segmentation of the image information. Thus, we introduce StrokeNUWA, a pioneering work exploring a better visual representation ''stroke tokens'' on vector graphics, which is inherently visual semantics rich, naturally compatible with LLMs, and highly compressed. Equipped with stroke tokens, StrokeNUWA can significantly surpass traditional LLM-based and optimization-based methods across various metrics in the vector graphic generation task. Besides, StrokeNUWA achieves up to a 94x speedup in inference over the speed of prior methods with an exceptional SVG code compression ratio of 6.9%.
A Unified Gaussian Process for Branching and Nested Hyperparameter Optimization
Jan 19, 2024Choosing appropriate hyperparameters plays a crucial role in the success of neural networks as hyper-parameters directly control the behavior and performance of the training algorithms. To obtain efficient tuning, Bayesian optimization methods based on Gaussian process (GP) models are widely used. Despite numerous applications of Bayesian optimization in deep learning, the existing methodologies are developed based on a convenient but restrictive assumption that the tuning parameters are independent of each other. However, tuning parameters with conditional dependence are common in practice. In this paper, we focus on two types of them: branching and nested parameters. Nested parameters refer to those tuning parameters that exist only within a particular setting of another tuning parameter, and a parameter within which other parameters are nested is called a branching parameter. To capture the conditional dependence between branching and nested parameters, a unified Bayesian optimization framework is proposed. The sufficient conditions are rigorously derived to guarantee the validity of the kernel function, and the asymptotic convergence of the proposed optimization framework is proven under the continuum-armed-bandit setting. Based on the new GP model, which accounts for the dependent structure among input variables through a new kernel function, higher prediction accuracy and better optimization efficiency are observed in a series of synthetic simulations and real data applications of neural networks. Sensitivity analysis is also performed to provide insights into how changes in hyperparameter values affect prediction accuracy.
Masked Modeling for Self-supervised Representation Learning on Vision and Beyond
Jan 09, 2024As the deep learning revolution marches on, self-supervised learning has garnered increasing attention in recent years thanks to its remarkable representation learning ability and the low dependence on labeled data. Among these varied self-supervised techniques, masked modeling has emerged as a distinctive approach that involves predicting parts of the original data that are proportionally masked during training. This paradigm enables deep models to learn robust representations and has demonstrated exceptional performance in the context of computer vision, natural language processing, and other modalities. In this survey, we present a comprehensive review of the masked modeling framework and its methodology. We elaborate on the details of techniques within masked modeling, including diverse masking strategies, recovering targets, network architectures, and more. Then, we systematically investigate its wide-ranging applications across domains. Furthermore, we also explore the commonalities and differences between masked modeling methods in different fields. Toward the end of this paper, we conclude by discussing the limitations of current techniques and point out several potential avenues for advancing masked modeling research. A paper list project with this survey is available at \url{https://github.com/Lupin1998/Awesome-MIM}.
Bring Metric Functions into Diffusion Models
Jan 04, 2024We introduce a Cascaded Diffusion Model (Cas-DM) that improves a Denoising Diffusion Probabilistic Model (DDPM) by effectively incorporating additional metric functions in training. Metric functions such as the LPIPS loss have been proven highly effective in consistency models derived from the score matching. However, for the diffusion counterparts, the methodology and efficacy of adding extra metric functions remain unclear. One major challenge is the mismatch between the noise predicted by a DDPM at each step and the desired clean image that the metric function works well on. To address this problem, we propose Cas-DM, a network architecture that cascades two network modules to effectively apply metric functions to the diffusion model training. The first module, similar to a standard DDPM, learns to predict the added noise and is unaffected by the metric function. The second cascaded module learns to predict the clean image, thereby facilitating the metric function computation. Experiment results show that the proposed diffusion model backbone enables the effective use of the LPIPS loss, leading to state-of-the-art image quality (FID, sFID, IS) on various established benchmarks.
Segment and Caption Anything
Dec 01, 2023We propose a method to efficiently equip the Segment Anything Model (SAM) with the ability to generate regional captions. SAM presents strong generalizability to segment anything while is short for semantic understanding. By introducing a lightweight query-based feature mixer, we align the region-specific features with the embedding space of language models for later caption generation. As the number of trainable parameters is small (typically in the order of tens of millions), it costs less computation, less memory usage, and less communication bandwidth, resulting in both fast and scalable training. To address the scarcity problem of regional caption data, we propose to first pre-train our model on objection detection and segmentation tasks. We call this step weak supervision pretraining since the pre-training data only contains category names instead of full-sentence descriptions. The weak supervision pretraining allows us to leverage many publicly available object detection and segmentation datasets. We conduct extensive experiments to demonstrate the superiority of our method and validate each design choice. This work serves as a stepping stone towards scaling up regional captioning data and sheds light on exploring efficient ways to augment SAM with regional semantics. The project page, along with the associated code, can be accessed via the following https://xk-huang.github.io/segment-caption-anything/.
MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning
Nov 29, 2023We present MM-Narrator, a novel system leveraging GPT-4 with multimodal in-context learning for the generation of audio descriptions (AD). Unlike previous methods that primarily focused on downstream fine-tuning with short video clips, MM-Narrator excels in generating precise audio descriptions for videos of extensive lengths, even beyond hours, in an autoregressive manner. This capability is made possible by the proposed memory-augmented generation process, which effectively utilizes both the short-term textual context and long-term visual memory through an efficient register-and-recall mechanism. These contextual memories compile pertinent past information, including storylines and character identities, ensuring an accurate tracking and depicting of story-coherent and character-centric audio descriptions. Maintaining the training-free design of MM-Narrator, we further propose a complexity-based demonstration selection strategy to largely enhance its multi-step reasoning capability via few-shot multimodal in-context learning (MM-ICL). Experimental results on MAD-eval dataset demonstrate that MM-Narrator consistently outperforms both the existing fine-tuning-based approaches and LLM-based approaches in most scenarios, as measured by standard evaluation metrics. Additionally, we introduce the first segment-based evaluator for recurrent text generation. Empowered by GPT-4, this evaluator comprehensively reasons and marks AD generation performance in various extendable dimensions.