 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZedong Wang
LongVQ: Long Sequence Modeling with Vector Quantization on Structured Memory
Apr 18, 2024
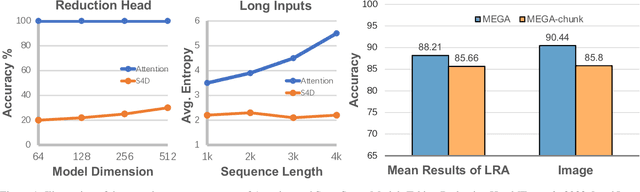



Transformer models have been successful in various sequence processing tasks, but the self-attention mechanism's computational cost limits its practicality for long sequences. Although there are existing attention variants that improve computational efficiency, they have a limited ability to abstract global information effectively based on their hand-crafted mixing strategies. On the other hand, state-space models (SSMs) are tailored for long sequences but cannot capture complicated local information. Therefore, the combination of them as a unified token mixer is a trend in recent long-sequence models. However, the linearized attention degrades performance significantly even when equipped with SSMs. To address the issue, we propose a new method called LongVQ. LongVQ uses the vector quantization (VQ) technique to compress the global abstraction as a length-fixed codebook, enabling the linear-time computation of the attention matrix. This technique effectively maintains dynamic global and local patterns, which helps to complement the lack of long-range dependency issues. Our experiments on the Long Range Arena benchmark, autoregressive language modeling, and image and speech classification demonstrate the effectiveness of LongVQ. Our model achieves significant improvements over other sequence models, including variants of Transformers, Convolutions, and recent State Space Models.
Switch EMA: A Free Lunch for Better Flatness and Sharpness
Feb 14, 2024Exponential Moving Average (EMA) is a widely used weight averaging (WA) regularization to learn flat optima for better generalizations without extra cost in deep neural network (DNN) optimization. Despite achieving better flatness, existing WA methods might fall into worse final performances or require extra test-time computations. This work unveils the full potential of EMA with a single line of modification, i.e., switching the EMA parameters to the original model after each epoch, dubbed as Switch EMA (SEMA). From both theoretical and empirical aspects, we demonstrate that SEMA can help DNNs to reach generalization optima that better trade-off between flatness and sharpness. To verify the effectiveness of SEMA, we conduct comparison experiments with discriminative, generative, and regression tasks on vision and language datasets, including image classification, self-supervised learning, object detection and segmentation, image generation, video prediction, attribute regression, and language modeling. Comprehensive results with popular optimizers and networks show that SEMA is a free lunch for DNN training by improving performances and boosting convergence speeds.
Masked Modeling for Self-supervised Representation Learning on Vision and Beyond
Jan 09, 2024As the deep learning revolution marches on, self-supervised learning has garnered increasing attention in recent years thanks to its remarkable representation learning ability and the low dependence on labeled data. Among these varied self-supervised techniques, masked modeling has emerged as a distinctive approach that involves predicting parts of the original data that are proportionally masked during training. This paradigm enables deep models to learn robust representations and has demonstrated exceptional performance in the context of computer vision, natural language processing, and other modalities. In this survey, we present a comprehensive review of the masked modeling framework and its methodology. We elaborate on the details of techniques within masked modeling, including diverse masking strategies, recovering targets, network architectures, and more. Then, we systematically investigate its wide-ranging applications across domains. Furthermore, we also explore the commonalities and differences between masked modeling methods in different fields. Toward the end of this paper, we conclude by discussing the limitations of current techniques and point out several potential avenues for advancing masked modeling research. A paper list project with this survey is available at \url{https://github.com/Lupin1998/Awesome-MIM}.
SemiReward: A General Reward Model for Semi-supervised Learning
Oct 04, 2023



Semi-supervised learning (SSL) has witnessed great progress with various improvements in the self-training framework with pseudo labeling. The main challenge is how to distinguish high-quality pseudo labels against the confirmation bias. However, existing pseudo-label selection strategies are limited to pre-defined schemes or complex hand-crafted policies specially designed for classification, failing to achieve high-quality labels, fast convergence, and task versatility simultaneously. To these ends, we propose a Semi-supervised Reward framework (SemiReward) that predicts reward scores to evaluate and filter out high-quality pseudo labels, which is pluggable to mainstream SSL methods in wide task types and scenarios. To mitigate confirmation bias, SemiReward is trained online in two stages with a generator model and subsampling strategy. With classification and regression tasks on 13 standard SSL benchmarks of three modalities, extensive experiments verify that SemiReward achieves significant performance gains and faster convergence speeds upon Pseudo Label, FlexMatch, and Free/SoftMatch.
OpenSTL: A Comprehensive Benchmark of Spatio-Temporal Predictive Learning
Jun 20, 2023



Spatio-temporal predictive learning is a learning paradigm that enables models to learn spatial and temporal patterns by predicting future frames from given past frames in an unsupervised manner. Despite remarkable progress in recent years, a lack of systematic understanding persists due to the diverse settings, complex implementation, and difficult reproducibility. Without standardization, comparisons can be unfair and insights inconclusive. To address this dilemma, we propose OpenSTL, a comprehensive benchmark for spatio-temporal predictive learning that categorizes prevalent approaches into recurrent-based and recurrent-free models. OpenSTL provides a modular and extensible framework implementing various state-of-the-art methods. We conduct standard evaluations on datasets across various domains, including synthetic moving object trajectory, human motion, driving scenes, traffic flow and weather forecasting. Based on our observations, we provide a detailed analysis of how model architecture and dataset properties affect spatio-temporal predictive learning performance. Surprisingly, we find that recurrent-free models achieve a good balance between efficiency and performance than recurrent models. Thus, we further extend the common MetaFormers to boost recurrent-free spatial-temporal predictive learning. We open-source the code and models at https://github.com/chengtan9907/OpenSTL.
Efficient Multi-order Gated Aggregation Network
Nov 07, 2022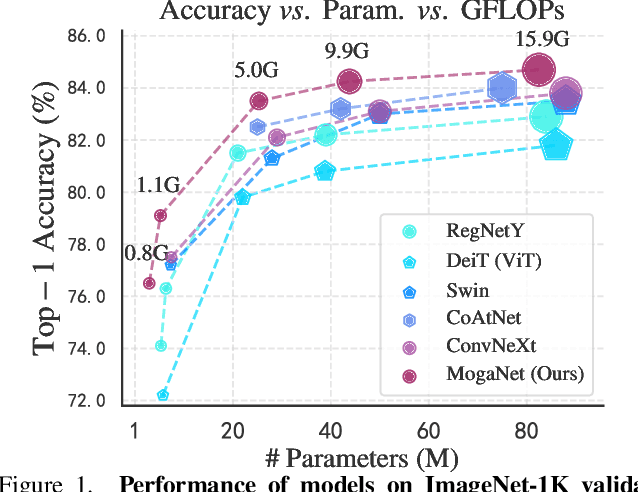

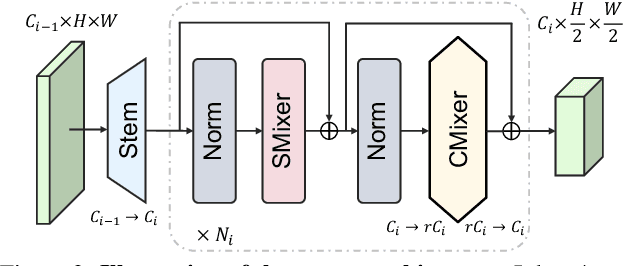

Since the recent success of Vision Transformers (ViTs), explorations toward transformer-style architectures have triggered the resurgence of modern ConvNets. In this work, we explore the representation ability of DNNs through the lens of interaction complexities. We empirically show that interaction complexity is an overlooked but essential indicator for visual recognition. Accordingly, a new family of efficient ConvNets, named MogaNet, is presented to pursue informative context mining in pure ConvNet-based models, with preferable complexity-performance trade-offs. In MogaNet, interactions across multiple complexities are facilitated and contextualized by leveraging two specially designed aggregation blocks in both spatial and channel interaction spaces. Extensive studies are conducted on ImageNet classification, COCO object detection, and ADE20K semantic segmentation tasks. The results demonstrate that our MogaNet establishes new state-of-the-art over other popular methods in mainstream scenarios and all model scales. Typically, the lightweight MogaNet-T achieves 80.0\% top-1 accuracy with only 1.44G FLOPs using a refined training setup on ImageNet-1K, surpassing ParC-Net-S by 1.4\% accuracy but saving 59\% (2.04G) FLOPs.
OpenMixup: Open Mixup Toolbox and Benchmark for Visual Representation Learning
Sep 11, 2022



With the remarkable progress of deep neural networks in computer vision, data mixing augmentation techniques are widely studied to alleviate problems of degraded generalization when the amount of training data is limited. However, mixup strategies have not been well assembled in current vision toolboxes. In this paper, we propose \texttt{OpenMixup}, an open-source all-in-one toolbox for supervised, semi-, and self-supervised visual representation learning with mixup. It offers an integrated model design and training platform, comprising a rich set of prevailing network architectures and modules, a collection of data mixing augmentation methods as well as practical model analysis tools. In addition, we also provide standard mixup image classification benchmarks on various datasets, which expedites practitioners to make fair comparisons among state-of-the-art methods under the same settings. The source code and user documents are available at \url{https://github.com/Westlake-AI/openmixup}.