 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBin Yu
Minimum-Norm Interpolation Under Covariate Shift
Mar 31, 2024
Transfer learning is a critical part of real-world machine learning deployments and has been extensively studied in experimental works with overparameterized neural networks. However, even in the simplest setting of linear regression a notable gap still exists in the theoretical understanding of transfer learning. In-distribution research on high-dimensional linear regression has led to the identification of a phenomenon known as \textit{benign overfitting}, in which linear interpolators overfit to noisy training labels and yet still generalize well. This behavior occurs under specific conditions on the source covariance matrix and input data dimension. Therefore, it is natural to wonder how such high-dimensional linear models behave under transfer learning. We prove the first non-asymptotic excess risk bounds for benignly-overfit linear interpolators in the transfer learning setting. From our analysis, we propose a taxonomy of \textit{beneficial} and \textit{malignant} covariate shifts based on the degree of overparameterization. We follow our analysis with empirical studies that show these beneficial and malignant covariate shifts for linear interpolators on real image data, and for fully-connected neural networks in settings where the input data dimension is larger than the training sample size.
A Signature Based Approach Towards Global Channel Charting with Ultra Low Complexity
Mar 29, 2024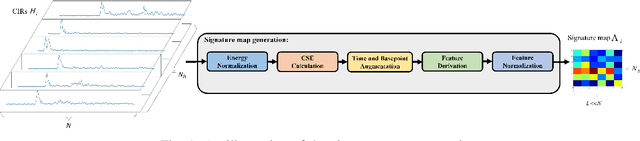
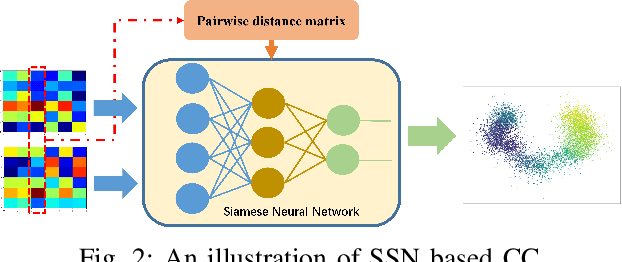
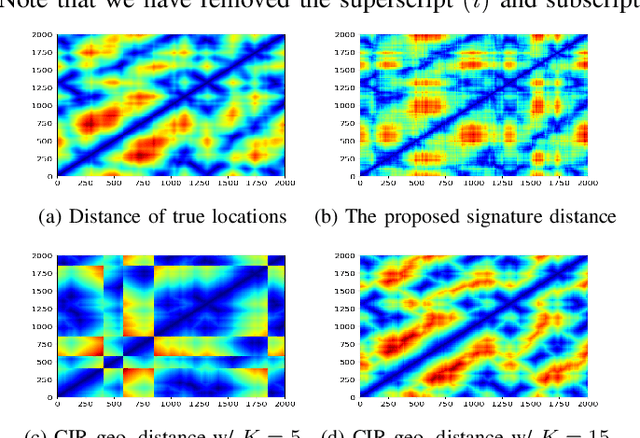
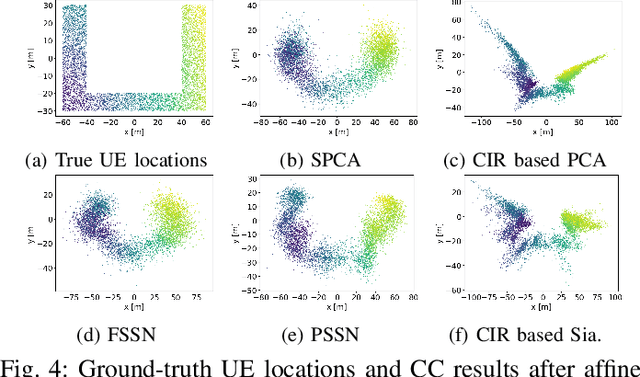
Channel charting, an unsupervised learning method that learns a low-dimensional representation from channel information to preserve geometrical property of physical space of user equipments (UEs), has drawn many attentions from both academic and industrial communities, because it can facilitate many downstream tasks, such as indoor localization, UE handover, beam management, and so on. However, many previous works mainly focus on charting that only preserves local geometry and use raw channel information to learn the chart, which do not consider the global geometry and are often computationally intensive and very time-consuming. Therefore, in this paper, a novel signature based approach for global channel charting with ultra low complexity is proposed. By using an iterated-integral based method called signature transform, a compact feature map and a novel distance metric are proposed, which enable channel charting with ultra low complexity and preserving both local and global geometry. We demonstrate the efficacy of our method using synthetic and open-source real-field datasets.
Large Stepsize Gradient Descent for Logistic Loss: Non-Monotonicity of the Loss Improves Optimization Efficiency
Feb 24, 2024We consider gradient descent (GD) with a constant stepsize applied to logistic regression with linearly separable data, where the constant stepsize $\eta$ is so large that the loss initially oscillates. We show that GD exits this initial oscillatory phase rapidly -- in $\mathcal{O}(\eta)$ steps -- and subsequently achieves an $\tilde{\mathcal{O}}(1 / (\eta t) )$ convergence rate after $t$ additional steps. Our results imply that, given a budget of $T$ steps, GD can achieve an accelerated loss of $\tilde{\mathcal{O}}(1/T^2)$ with an aggressive stepsize $\eta:= \Theta( T)$, without any use of momentum or variable stepsize schedulers. Our proof technique is versatile and also handles general classification loss functions (where exponential tails are needed for the $\tilde{\mathcal{O}}(1/T^2)$ acceleration), nonlinear predictors in the neural tangent kernel regime, and online stochastic gradient descent (SGD) with a large stepsize, under suitable separability conditions.
ED-Copilot: Reduce Emergency Department Wait Time with Language Model Diagnostic Assistance
Feb 21, 2024In the emergency department (ED), patients undergo triage and multiple laboratory tests before diagnosis. This process is time-consuming, and causes ED crowding which significantly impacts patient mortality, medical errors, staff burnout, etc. This work proposes (time) cost-effective diagnostic assistance that explores the potential of artificial intelligence (AI) systems in assisting ED clinicians to make time-efficient and accurate diagnoses. Using publicly available patient data, we collaborate with ED clinicians to curate MIMIC-ED-Assist, a benchmark that measures the ability of AI systems in suggesting laboratory tests that minimize ED wait times, while correctly predicting critical outcomes such as death. We develop ED-Copilot which sequentially suggests patient-specific laboratory tests and makes diagnostic predictions. ED-Copilot uses a pre-trained bio-medical language model to encode patient information and reinforcement learning to minimize ED wait time and maximize prediction accuracy of critical outcomes. On MIMIC-ED-Assist, ED-Copilot improves prediction accuracy over baselines while halving average wait time from four hours to two hours. Ablation studies demonstrate the importance of model scale and use of a bio-medical language model. Further analyses reveal the necessity of personalized laboratory test suggestions for diagnosing patients with severe cases, as well as the potential of ED-Copilot in providing ED clinicians with informative laboratory test recommendations. Our code is available at https://github.com/cxcscmu/ED-Copilot.
LoRA+: Efficient Low Rank Adaptation of Large Models
Feb 19, 2024In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $\%$ improvements) and finetuning speed (up to $\sim$ 2X SpeedUp), at the same computational cost as LoRA.
Towards Consistent Natural-Language Explanations via Explanation-Consistency Finetuning
Jan 25, 2024Large language models (LLMs) often generate convincing, fluent explanations. However, different from humans, they often generate inconsistent explanations on different inputs. For example, an LLM may generate the explanation "all birds can fly" when answering the question "Can sparrows fly?" but meanwhile answer "no" to the related question "Can penguins fly?". Explanations should be consistent across related examples so that they allow a human to simulate the LLM's decision process on multiple examples. We propose explanation-consistency finetuning (EC-finetuning), a method that adapts LLMs to generate more consistent natural-language explanations on related examples. EC-finetuning involves finetuning LLMs on synthetic data that is carefully constructed to contain consistent explanations. Across a variety of question-answering datasets in various domains, EC-finetuning yields a 10.0% relative explanation consistency improvement on four finetuning datasets, and generalizes to seven out-of-distribution datasets not seen during finetuning (+4.5% relative). Code is available at https://github.com/yandachen/explanation-consistency-finetuning .
Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs
Nov 03, 2023In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. These textual emphases are vital for the readers to grasp the conveyed information. When interacting with large language models (LLMs), we have a similar need - steering the model to pay closer attention to user-specified information, e.g., an instruction. Existing methods, however, are constrained to process plain text and do not support such a mechanism. This motivates us to introduce PASTA - Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks. To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters. Experiments demonstrate that PASTA can substantially enhance an LLM's ability to follow user instructions or integrate new knowledge from user inputs, leading to a significant performance improvement on a variety of tasks, e.g., an average accuracy improvement of 22% for LLAMA-7B. Our code is publicly available at https://github.com/QingruZhang/PASTA .
Using Experience Classification for Training Non-Markovian Tasks
Oct 18, 2023Unlike the standard Reinforcement Learning (RL) model, many real-world tasks are non-Markovian, whose rewards are predicated on state history rather than solely on the current state. Solving a non-Markovian task, frequently applied in practical applications such as autonomous driving, financial trading, and medical diagnosis, can be quite challenging. We propose a novel RL approach to achieve non-Markovian rewards expressed in temporal logic LTL$_f$ (Linear Temporal Logic over Finite Traces). To this end, an encoding of linear complexity from LTL$_f$ into MDPs (Markov Decision Processes) is introduced to take advantage of advanced RL algorithms. Then, a prioritized experience replay technique based on the automata structure (semantics equivalent to LTL$_f$ specification) is utilized to improve the training process. We empirically evaluate several benchmark problems augmented with non-Markovian tasks to demonstrate the feasibility and effectiveness of our approach.
Prominent Roles of Conditionally Invariant Components in Domain Adaptation: Theory and Algorithms
Sep 19, 2023Domain adaptation (DA) is a statistical learning problem that arises when the distribution of the source data used to train a model differs from that of the target data used to evaluate the model. While many DA algorithms have demonstrated considerable empirical success, blindly applying these algorithms can often lead to worse performance on new datasets. To address this, it is crucial to clarify the assumptions under which a DA algorithm has good target performance. In this work, we focus on the assumption of the presence of conditionally invariant components (CICs), which are relevant for prediction and remain conditionally invariant across the source and target data. We demonstrate that CICs, which can be estimated through conditional invariant penalty (CIP), play three prominent roles in providing target risk guarantees in DA. First, we propose a new algorithm based on CICs, importance-weighted conditional invariant penalty (IW-CIP), which has target risk guarantees beyond simple settings such as covariate shift and label shift. Second, we show that CICs help identify large discrepancies between source and target risks of other DA algorithms. Finally, we demonstrate that incorporating CICs into the domain invariant projection (DIP) algorithm can address its failure scenario caused by label-flipping features. We support our new algorithms and theoretical findings via numerical experiments on synthetic data, MNIST, CelebA, and Camelyon17 datasets.
TrafficGPT: Viewing, Processing and Interacting with Traffic Foundation Models
Sep 13, 2023With the promotion of chatgpt to the public, Large language models indeed showcase remarkable common sense, reasoning, and planning skills, frequently providing insightful guidance. These capabilities hold significant promise for their application in urban traffic management and control. However, LLMs struggle with addressing traffic issues, especially processing numerical data and interacting with simulations, limiting their potential in solving traffic-related challenges. In parallel, specialized traffic foundation models exist but are typically designed for specific tasks with limited input-output interactions. Combining these models with LLMs presents an opportunity to enhance their capacity for tackling complex traffic-related problems and providing insightful suggestions. To bridge this gap, we present TrafficGPT, a fusion of ChatGPT and traffic foundation models. This integration yields the following key enhancements: 1) empowering ChatGPT with the capacity to view, analyze, process traffic data, and provide insightful decision support for urban transportation system management; 2) facilitating the intelligent deconstruction of broad and complex tasks and sequential utilization of traffic foundation models for their gradual completion; 3) aiding human decision-making in traffic control through natural language dialogues; and 4) enabling interactive feedback and solicitation of revised outcomes. By seamlessly intertwining large language model and traffic expertise, TrafficGPT not only advances traffic management but also offers a novel approach to leveraging AI capabilities in this domain. The TrafficGPT demo can be found in https://github.com/lijlansg/TrafficGPT.git.