 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpencer Frei
Minimum-Norm Interpolation Under Covariate Shift
Mar 31, 2024
Transfer learning is a critical part of real-world machine learning deployments and has been extensively studied in experimental works with overparameterized neural networks. However, even in the simplest setting of linear regression a notable gap still exists in the theoretical understanding of transfer learning. In-distribution research on high-dimensional linear regression has led to the identification of a phenomenon known as \textit{benign overfitting}, in which linear interpolators overfit to noisy training labels and yet still generalize well. This behavior occurs under specific conditions on the source covariance matrix and input data dimension. Therefore, it is natural to wonder how such high-dimensional linear models behave under transfer learning. We prove the first non-asymptotic excess risk bounds for benignly-overfit linear interpolators in the transfer learning setting. From our analysis, we propose a taxonomy of \textit{beneficial} and \textit{malignant} covariate shifts based on the degree of overparameterization. We follow our analysis with empirical studies that show these beneficial and malignant covariate shifts for linear interpolators on real image data, and for fully-connected neural networks in settings where the input data dimension is larger than the training sample size.
Benign Overfitting and Grokking in ReLU Networks for XOR Cluster Data
Oct 04, 2023Neural networks trained by gradient descent (GD) have exhibited a number of surprising generalization behaviors. First, they can achieve a perfect fit to noisy training data and still generalize near-optimally, showing that overfitting can sometimes be benign. Second, they can undergo a period of classical, harmful overfitting -- achieving a perfect fit to training data with near-random performance on test data -- before transitioning ("grokking") to near-optimal generalization later in training. In this work, we show that both of these phenomena provably occur in two-layer ReLU networks trained by GD on XOR cluster data where a constant fraction of the training labels are flipped. In this setting, we show that after the first step of GD, the network achieves 100% training accuracy, perfectly fitting the noisy labels in the training data, but achieves near-random test accuracy. At a later training step, the network achieves near-optimal test accuracy while still fitting the random labels in the training data, exhibiting a "grokking" phenomenon. This provides the first theoretical result of benign overfitting in neural network classification when the data distribution is not linearly separable. Our proofs rely on analyzing the feature learning process under GD, which reveals that the network implements a non-generalizable linear classifier after one step and gradually learns generalizable features in later steps.
The Effect of SGD Batch Size on Autoencoder Learning: Sparsity, Sharpness, and Feature Learning
Aug 06, 2023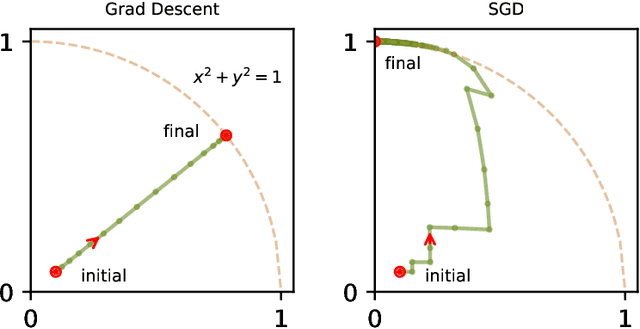
In this work, we investigate the dynamics of stochastic gradient descent (SGD) when training a single-neuron autoencoder with linear or ReLU activation on orthogonal data. We show that for this non-convex problem, randomly initialized SGD with a constant step size successfully finds a global minimum for any batch size choice. However, the particular global minimum found depends upon the batch size. In the full-batch setting, we show that the solution is dense (i.e., not sparse) and is highly aligned with its initialized direction, showing that relatively little feature learning occurs. On the other hand, for any batch size strictly smaller than the number of samples, SGD finds a global minimum which is sparse and nearly orthogonal to its initialization, showing that the randomness of stochastic gradients induces a qualitatively different type of "feature selection" in this setting. Moreover, if we measure the sharpness of the minimum by the trace of the Hessian, the minima found with full batch gradient descent are flatter than those found with strictly smaller batch sizes, in contrast to previous works which suggest that large batches lead to sharper minima. To prove convergence of SGD with a constant step size, we introduce a powerful tool from the theory of non-homogeneous random walks which may be of independent interest.
Trained Transformers Learn Linear Models In-Context
Jun 16, 2023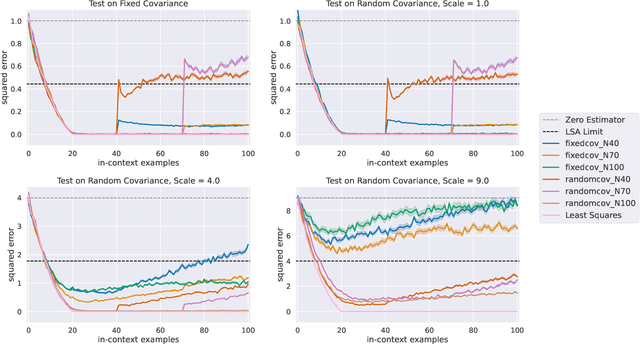
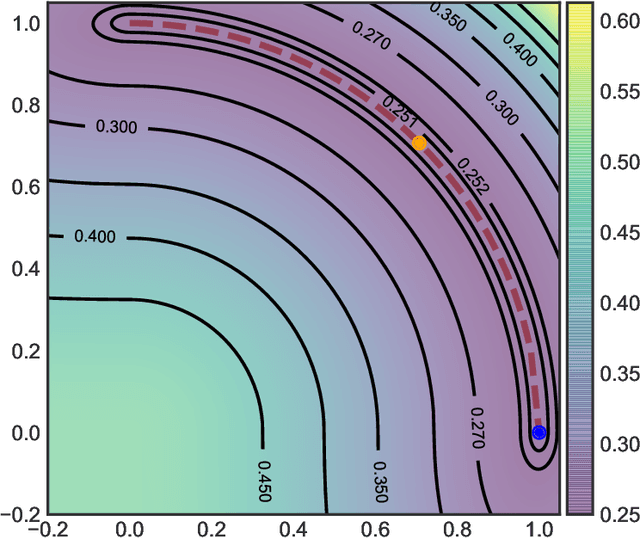
Attention-based neural networks such as transformers have demonstrated a remarkable ability to exhibit in-context learning (ICL): Given a short prompt sequence of tokens from an unseen task, they can formulate relevant per-token and next-token predictions without any parameter updates. By embedding a sequence of labeled training data and unlabeled test data as a prompt, this allows for transformers to behave like supervised learning algorithms. Indeed, recent work has shown that when training transformer architectures over random instances of linear regression problems, these models' predictions mimic those of ordinary least squares. Towards understanding the mechanisms underlying this phenomenon, we investigate the dynamics of ICL in transformers with a single linear self-attention layer trained by gradient flow on linear regression tasks. We show that despite non-convexity, gradient flow with a suitable random initialization finds a global minimum of the objective function. At this global minimum, when given a test prompt of labeled examples from a new prediction task, the transformer achieves prediction error competitive with the best linear predictor over the test prompt distribution. We additionally characterize the robustness of the trained transformer to a variety of distribution shifts and show that although a number of shifts are tolerated, shifts in the covariate distribution of the prompts are not. Motivated by this, we consider a generalized ICL setting where the covariate distributions can vary across prompts. We show that although gradient flow succeeds at finding a global minimum in this setting, the trained transformer is still brittle under mild covariate shifts.
Benign Overfitting in Linear Classifiers and Leaky ReLU Networks from KKT Conditions for Margin Maximization
Mar 02, 2023Linear classifiers and leaky ReLU networks trained by gradient flow on the logistic loss have an implicit bias towards solutions which satisfy the Karush--Kuhn--Tucker (KKT) conditions for margin maximization. In this work we establish a number of settings where the satisfaction of these KKT conditions implies benign overfitting in linear classifiers and in two-layer leaky ReLU networks: the estimators interpolate noisy training data and simultaneously generalize well to test data. The settings include variants of the noisy class-conditional Gaussians considered in previous work as well as new distributional settings where benign overfitting has not been previously observed. The key ingredient to our proof is the observation that when the training data is nearly-orthogonal, both linear classifiers and leaky ReLU networks satisfying the KKT conditions for their respective margin maximization problems behave like a nearly uniform average of the training examples.
The Double-Edged Sword of Implicit Bias: Generalization vs. Robustness in ReLU Networks
Mar 02, 2023In this work, we study the implications of the implicit bias of gradient flow on generalization and adversarial robustness in ReLU networks. We focus on a setting where the data consists of clusters and the correlations between cluster means are small, and show that in two-layer ReLU networks gradient flow is biased towards solutions that generalize well, but are highly vulnerable to adversarial examples. Our results hold even in cases where the network has many more parameters than training examples. Despite the potential for harmful overfitting in such overparameterized settings, we prove that the implicit bias of gradient flow prevents it. However, the implicit bias also leads to non-robust solutions (susceptible to small adversarial $\ell_2$-perturbations), even though robust networks that fit the data exist.
Implicit Bias in Leaky ReLU Networks Trained on High-Dimensional Data
Oct 13, 2022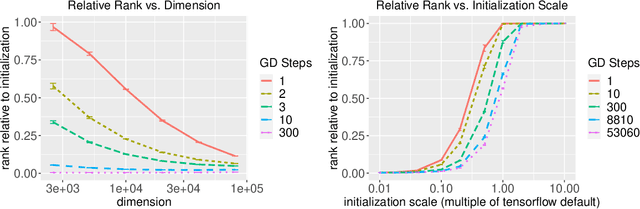
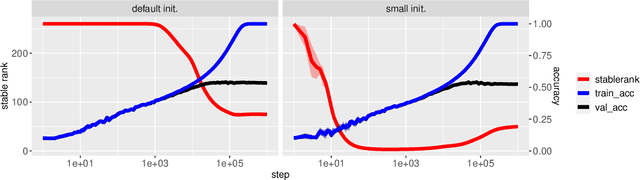
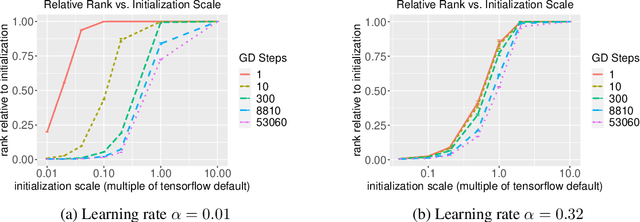
The implicit biases of gradient-based optimization algorithms are conjectured to be a major factor in the success of modern deep learning. In this work, we investigate the implicit bias of gradient flow and gradient descent in two-layer fully-connected neural networks with leaky ReLU activations when the training data are nearly-orthogonal, a common property of high-dimensional data. For gradient flow, we leverage recent work on the implicit bias for homogeneous neural networks to show that asymptotically, gradient flow produces a neural network with rank at most two. Moreover, this network is an $\ell_2$-max-margin solution (in parameter space), and has a linear decision boundary that corresponds to an approximate-max-margin linear predictor. For gradient descent, provided the random initialization variance is small enough, we show that a single step of gradient descent suffices to drastically reduce the rank of the network, and that the rank remains small throughout training. We provide experiments which suggest that a small initialization scale is important for finding low-rank neural networks with gradient descent.
Random Feature Amplification: Feature Learning and Generalization in Neural Networks
Feb 15, 2022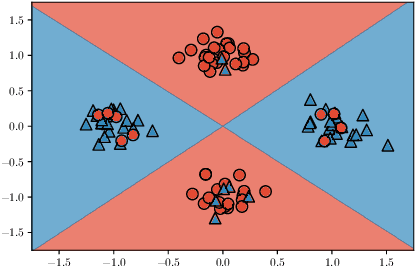
In this work, we provide a characterization of the feature-learning process in two-layer ReLU networks trained by gradient descent on the logistic loss following random initialization. We consider data with binary labels that are generated by an XOR-like function of the input features. We permit a constant fraction of the training labels to be corrupted by an adversary. We show that, although linear classifiers are no better than random guessing for the distribution we consider, two-layer ReLU networks trained by gradient descent achieve generalization error close to the label noise rate, refuting the conjecture of Malach and Shalev-Shwartz that 'deeper is better only when shallow is good'. We develop a novel proof technique that shows that at initialization, the vast majority of neurons function as random features that are only weakly correlated with useful features, and the gradient descent dynamics 'amplify' these weak, random features to strong, useful features.
Benign Overfitting without Linearity: Neural Network Classifiers Trained by Gradient Descent for Noisy Linear Data
Feb 11, 2022Benign overfitting, the phenomenon where interpolating models generalize well in the presence of noisy data, was first observed in neural network models trained with gradient descent. To better understand this empirical observation, we consider the generalization error of two-layer neural networks trained to interpolation by gradient descent on the logistic loss following random initialization. We assume the data comes from well-separated class-conditional log-concave distributions and allow for a constant fraction of the training labels to be corrupted by an adversary. We show that in this setting, neural networks exhibit benign overfitting: they can be driven to zero training error, perfectly fitting any noisy training labels, and simultaneously achieve test error close to the Bayes-optimal error. In contrast to previous work on benign overfitting that require linear or kernel-based predictors, our analysis holds in a setting where both the model and learning dynamics are fundamentally nonlinear.
Proxy Convexity: A Unified Framework for the Analysis of Neural Networks Trained by Gradient Descent
Jul 20, 2021Although the optimization objectives for learning neural networks are highly non-convex, gradient-based methods have been wildly successful at learning neural networks in practice. This juxtaposition has led to a number of recent studies on provable guarantees for neural networks trained by gradient descent. Unfortunately, the techniques in these works are often highly specific to the problem studied in each setting, relying on different assumptions on the distribution, optimization parameters, and network architectures, making it difficult to generalize across different settings. In this work, we propose a unified non-convex optimization framework for the analysis of neural network training. We introduce the notions of proxy convexity and proxy Polyak-Lojasiewicz (PL) inequalities, which are satisfied if the original objective function induces a proxy objective function that is implicitly minimized when using gradient methods. We show that stochastic gradient descent (SGD) on objectives satisfying proxy convexity or the proxy PL inequality leads to efficient guarantees for proxy objective functions. We further show that many existing guarantees for neural networks trained by gradient descent can be unified through proxy convexity and proxy PL inequalities.