 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoufiane Hayou
How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
Apr 07, 2024
The phenomenon of model collapse, introduced in (Shumailov et al., 2023), refers to the deterioration in performance that occurs when new models are trained on synthetic data generated from previously trained models. This recursive training loop makes the tails of the original distribution disappear, thereby making future-generation models forget about the initial (real) distribution. With the aim of rigorously understanding model collapse in language models, we consider in this paper a statistical model that allows us to characterize the impact of various recursive training scenarios. Specifically, we demonstrate that model collapse cannot be avoided when training solely on synthetic data. However, when mixing both real and synthetic data, we provide an estimate of a maximal amount of synthetic data below which model collapse can eventually be avoided. Our theoretical conclusions are further supported by empirical validations.
LoRA+: Efficient Low Rank Adaptation of Large Models
Feb 19, 2024In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $\%$ improvements) and finetuning speed (up to $\sim$ 2X SpeedUp), at the same computational cost as LoRA.
Tensor Programs VI: Feature Learning in Infinite-Depth Neural Networks
Oct 12, 2023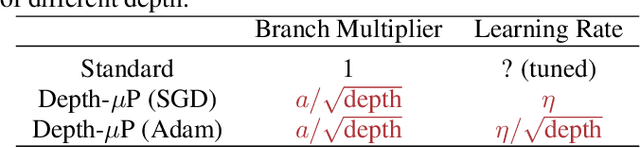
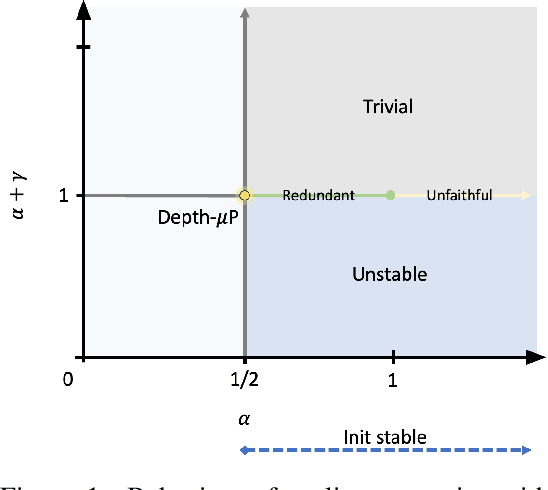
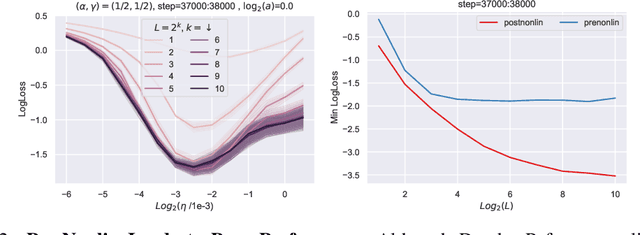
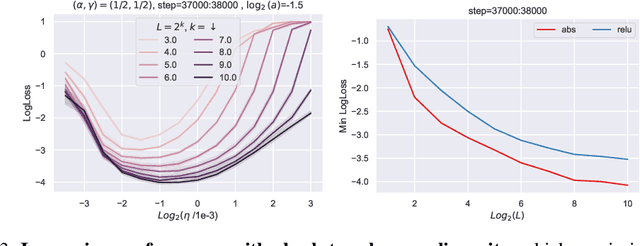
By classifying infinite-width neural networks and identifying the *optimal* limit, Tensor Programs IV and V demonstrated a universal way, called $\mu$P, for *widthwise hyperparameter transfer*, i.e., predicting optimal hyperparameters of wide neural networks from narrow ones. Here we investigate the analogous classification for *depthwise parametrizations* of deep residual networks (resnets). We classify depthwise parametrizations of block multiplier and learning rate by their infinite-width-then-depth limits. In resnets where each block has only one layer, we identify a unique optimal parametrization, called Depth-$\mu$P that extends $\mu$P and show empirically it admits depthwise hyperparameter transfer. We identify *feature diversity* as a crucial factor in deep networks, and Depth-$\mu$P can be characterized as maximizing both feature learning and feature diversity. Exploiting this, we find that absolute value, among all homogeneous nonlinearities, maximizes feature diversity and indeed empirically leads to significantly better performance. However, if each block is deeper (such as modern transformers), then we find fundamental limitations in all possible infinite-depth limits of such parametrizations, which we illustrate both theoretically and empirically on simple networks as well as Megatron transformer trained on Common Crawl.
Commutative Width and Depth Scaling in Deep Neural Networks
Oct 02, 2023This paper is the second in the series Commutative Scaling of Width and Depth (WD) about commutativity of infinite width and depth limits in deep neural networks. Our aim is to understand the behaviour of neural functions (functions that depend on a neural network model) as width and depth go to infinity (in some sense), and eventually identify settings under which commutativity holds, i.e. the neural function tends to the same limit no matter how width and depth limits are taken. In this paper, we formally introduce and define the commutativity framework, and discuss its implications on neural network design and scaling. We study commutativity for the neural covariance kernel which reflects how network layers separate data. Our findings extend previous results established in [55] by showing that taking the width and depth to infinity in a deep neural network with skip connections, when branches are suitably scaled to avoid exploding behaviour, result in the same covariance structure no matter how that limit is taken. This has a number of theoretical and practical implications that we discuss in the paper. The proof techniques in this paper are novel and rely on tools that are more accessible to readers who are not familiar with stochastic calculus (used in the proofs of WD(I))).
Leave-one-out Distinguishability in Machine Learning
Sep 29, 2023We introduce a new analytical framework to quantify the changes in a machine learning algorithm's output distribution following the inclusion of a few data points in its training set, a notion we define as leave-one-out distinguishability (LOOD). This problem is key to measuring data **memorization** and **information leakage** in machine learning, and the **influence** of training data points on model predictions. We illustrate how our method broadens and refines existing empirical measures of memorization and privacy risks associated with training data. We use Gaussian processes to model the randomness of machine learning algorithms, and validate LOOD with extensive empirical analysis of information leakage using membership inference attacks. Our theoretical framework enables us to investigate the causes of information leakage and where the leakage is high. For example, we analyze the influence of activation functions, on data memorization. Additionally, our method allows us to optimize queries that disclose the most significant information about the training data in the leave-one-out setting. We illustrate how optimal queries can be used for accurate **reconstruction** of training data.
On the Connection Between Riemann Hypothesis and a Special Class of Neural Networks
Sep 17, 2023The Riemann hypothesis (RH) is a long-standing open problem in mathematics. It conjectures that non-trivial zeros of the zeta function all have real part equal to 1/2. The extent of the consequences of RH is far-reaching and touches a wide spectrum of topics including the distribution of prime numbers, the growth of arithmetic functions, the growth of Euler totient, etc. In this note, we revisit and extend an old analytic criterion of the RH known as the Nyman-Beurling criterion which connects the RH to a minimization problem that involves a special class of neural networks. This note is intended for an audience unfamiliar with RH. A gentle introduction to RH is provided.
Data pruning and neural scaling laws: fundamental limitations of score-based algorithms
Feb 14, 2023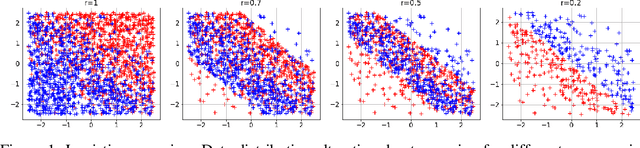
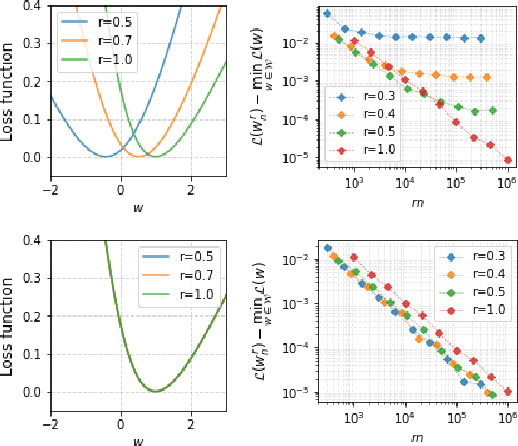
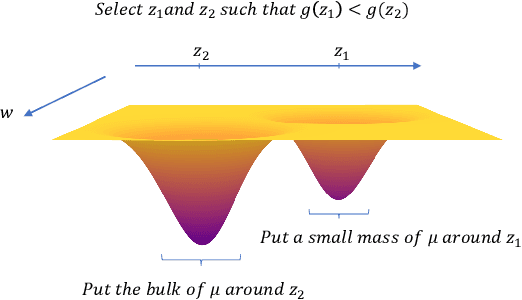
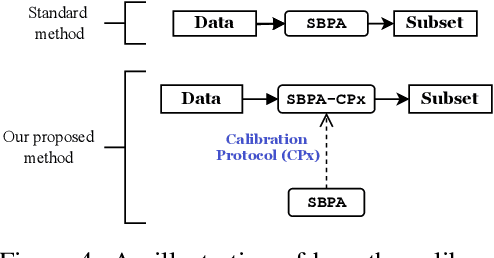
Data pruning algorithms are commonly used to reduce the memory and computational cost of the optimization process. Recent empirical results reveal that random data pruning remains a strong baseline and outperforms most existing data pruning methods in the high compression regime, i.e., where a fraction of $30\%$ or less of the data is kept. This regime has recently attracted a lot of interest as a result of the role of data pruning in improving the so-called neural scaling laws; in [Sorscher et al.], the authors showed the need for high-quality data pruning algorithms in order to beat the sample power law. In this work, we focus on score-based data pruning algorithms and show theoretically and empirically why such algorithms fail in the high compression regime. We demonstrate ``No Free Lunch" theorems for data pruning and present calibration protocols that enhance the performance of existing pruning algorithms in this high compression regime using randomization.
Width and Depth Limits Commute in Residual Networks
Feb 01, 2023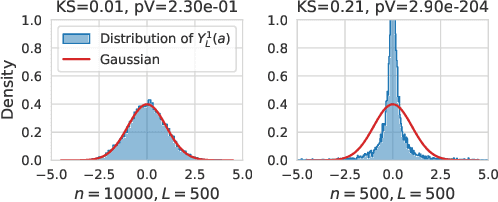
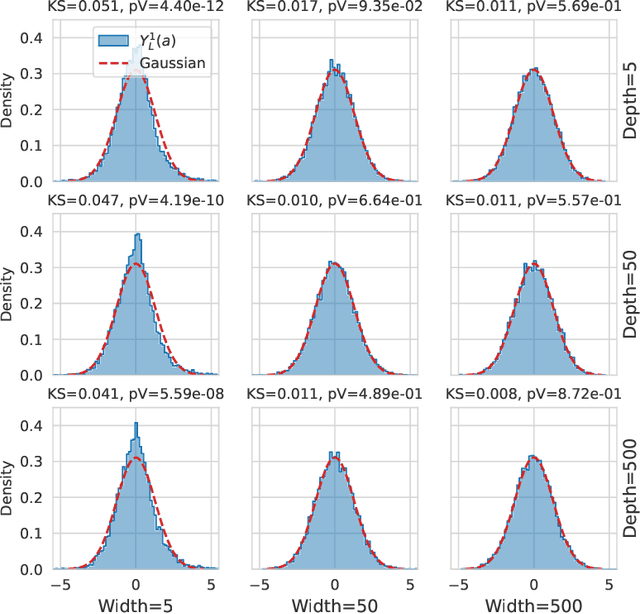
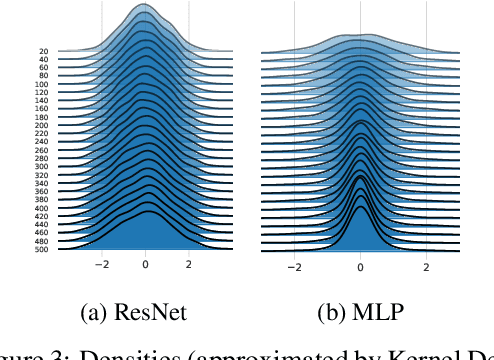
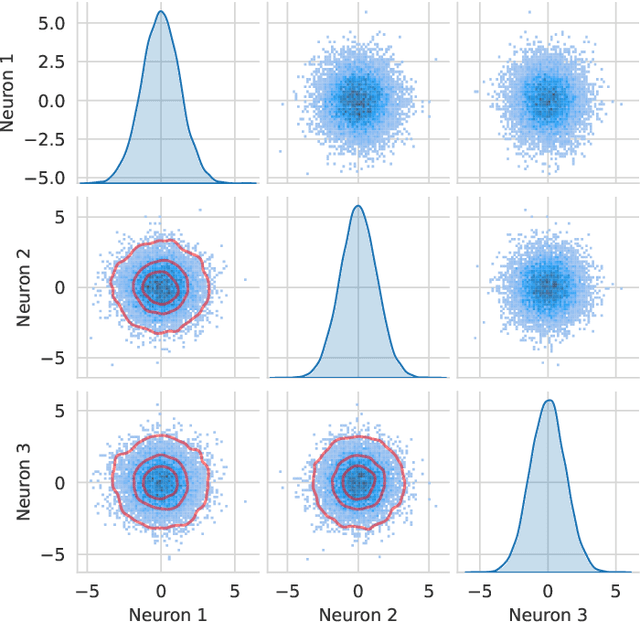
We show that taking the width and depth to infinity in a deep neural network with skip connections, when branches are scaled by $1/\sqrt{depth}$ (the only nontrivial scaling), result in the same covariance structure no matter how that limit is taken. This explains why the standard infinite-width-then-depth approach provides practical insights even for networks with depth of the same order as width. We also demonstrate that the pre-activations, in this case, have Gaussian distributions which has direct applications in Bayesian deep learning. We conduct extensive simulations that show an excellent match with our theoretical findings.
On the infinite-depth limit of finite-width neural networks
Oct 03, 2022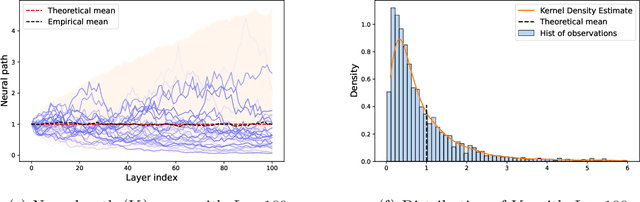
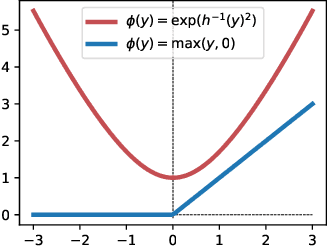
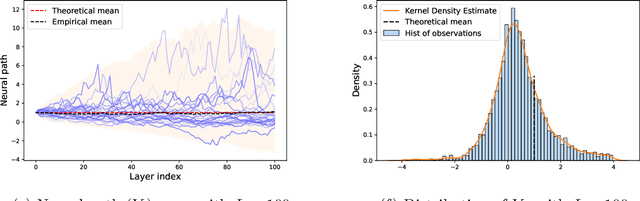
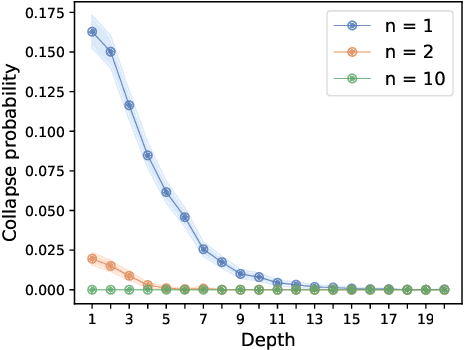
In this paper, we study the infinite-depth limit of finite-width residual neural networks with random Gaussian weights. With proper scaling, we show that by fixing the width and taking the depth to infinity, the vector of pre-activations converges in distribution to a zero-drift diffusion process. Unlike the infinite-width limit where the pre-activation converge weakly to a Gaussian random variable, we show that the infinite-depth limit yields different distributions depending on the choice of the activation function. We document two cases where these distributions have closed-form (different) expressions. We further show an intriguing phase-transition phenomenon of the post-activation norms when the width increases from 3 to 4. Lastly, we study the sequential limit infinite-depth-then-infinite-width, and show some key differences with the more commonly studied infinite-width-then-infinite-depth limit.