 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengyuan Liu
SATO: Stable Text-to-Motion Framework
May 02, 2024
Is the Text to Motion model robust? Recent advancements in Text to Motion models primarily stem from more accurate predictions of specific actions. However, the text modality typically relies solely on pre-trained Contrastive Language-Image Pretraining (CLIP) models. Our research has uncovered a significant issue with the text-to-motion model: its predictions often exhibit inconsistent outputs, resulting in vastly different or even incorrect poses when presented with semantically similar or identical text inputs. In this paper, we undertake an analysis to elucidate the underlying causes of this instability, establishing a clear link between the unpredictability of model outputs and the erratic attention patterns of the text encoder module. Consequently, we introduce a formal framework aimed at addressing this issue, which we term the Stable Text-to-Motion Framework (SATO). SATO consists of three modules, each dedicated to stable attention, stable prediction, and maintaining a balance between accuracy and robustness trade-off. We present a methodology for constructing an SATO that satisfies the stability of attention and prediction. To verify the stability of the model, we introduced a new textual synonym perturbation dataset based on HumanML3D and KIT-ML. Results show that SATO is significantly more stable against synonyms and other slight perturbations while keeping its high accuracy performance.
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Apr 30, 2024In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
HDBN: A Novel Hybrid Dual-branch Network for Robust Skeleton-based Action Recognition
Apr 25, 2024Skeleton-based action recognition has gained considerable traction thanks to its utilization of succinct and robust skeletal representations. Nonetheless, current methodologies often lean towards utilizing a solitary backbone to model skeleton modality, which can be limited by inherent flaws in the network backbone. To address this and fully leverage the complementary characteristics of various network architectures, we propose a novel Hybrid Dual-Branch Network (HDBN) for robust skeleton-based action recognition, which benefits from the graph convolutional network's proficiency in handling graph-structured data and the powerful modeling capabilities of Transformers for global information. In detail, our proposed HDBN is divided into two trunk branches: MixGCN and MixFormer. The two branches utilize GCNs and Transformers to model both 2D and 3D skeletal modalities respectively. Our proposed HDBN emerged as one of the top solutions in the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) of 2024 ICME Grand Challenge, achieving accuracies of 47.95% and 75.36% on two benchmarks of the UAV-Human dataset by outperforming most existing methods. Our code will be publicly available at: https://github.com/liujf69/ICMEW2024-Track10.
SFMViT: SlowFast Meet ViT in Chaotic World
Apr 25, 2024The task of spatiotemporal action localization in chaotic scenes is a challenging task toward advanced video understanding. Paving the way with high-quality video feature extraction and enhancing the precision of detector-predicted anchors can effectively improve model performance. To this end, we propose a high-performance dual-stream spatiotemporal feature extraction network SFMViT with an anchor pruning strategy. The backbone of our SFMViT is composed of ViT and SlowFast with prior knowledge of spatiotemporal action localization, which fully utilizes ViT's excellent global feature extraction capabilities and SlowFast's spatiotemporal sequence modeling capabilities. Secondly, we introduce the confidence maximum heap to prune the anchors detected in each frame of the picture to filter out the effective anchors. These designs enable our SFMViT to achieve a mAP of 26.62% in the Chaotic World dataset, far exceeding existing models. Code is available at https://github.com/jfightyr/SlowFast-Meet-ViT.
MLP: Motion Label Prior for Temporal Sentence Localization in Untrimmed 3D Human Motions
Apr 21, 2024In this paper, we address the unexplored question of temporal sentence localization in human motions (TSLM), aiming to locate a target moment from a 3D human motion that semantically corresponds to a text query. Considering that 3D human motions are captured using specialized motion capture devices, motions with only a few joints lack complex scene information like objects and lighting. Due to this character, motion data has low contextual richness and semantic ambiguity between frames, which limits the accuracy of predictions made by current video localization frameworks extended to TSLM to only a rough level. To refine this, we devise two novel label-prior-assisted training schemes: one embed prior knowledge of foreground and background to highlight the localization chances of target moments, and the other forces the originally rough predictions to overlap with the more accurate predictions obtained from the flipped start/end prior label sequences during recovery training. We show that injecting label-prior knowledge into the model is crucial for improving performance at high IoU. In our constructed TSLM benchmark, our model termed MLP achieves a recall of 44.13 at IoU@0.7 on the BABEL dataset and 71.17 on HumanML3D (Restore), outperforming prior works. Finally, we showcase the potential of our approach in corpus-level moment retrieval. Our source code is openly accessible at https://github.com/eanson023/mlp.
Point-In-Context: Understanding Point Cloud via In-Context Learning
Apr 18, 2024With the emergence of large-scale models trained on diverse datasets, in-context learning has emerged as a promising paradigm for multitasking, notably in natural language processing and image processing. However, its application in 3D point cloud tasks remains largely unexplored. In this work, we introduce Point-In-Context (PIC), a novel framework for 3D point cloud understanding via in-context learning. We address the technical challenge of effectively extending masked point modeling to 3D point clouds by introducing a Joint Sampling module and proposing a vanilla version of PIC called Point-In-Context-Generalist (PIC-G). PIC-G is designed as a generalist model for various 3D point cloud tasks, with inputs and outputs modeled as coordinates. In this paradigm, the challenging segmentation task is achieved by assigning label points with XYZ coordinates for each category; the final prediction is then chosen based on the label point closest to the predictions. To break the limitation by the fixed label-coordinate assignment, which has poor generalization upon novel classes, we propose two novel training strategies, In-Context Labeling and In-Context Enhancing, forming an extended version of PIC named Point-In-Context-Segmenter (PIC-S), targeting improving dynamic context labeling and model training. By utilizing dynamic in-context labels and extra in-context pairs, PIC-S achieves enhanced performance and generalization capability in and across part segmentation datasets. PIC is a general framework so that other tasks or datasets can be seamlessly introduced into our PIC through a unified data format. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks and segmenting multi-datasets. Our PIC-S is capable of generalizing unseen datasets and performing novel part segmentation by customizing prompts.
VG4D: Vision-Language Model Goes 4D Video Recognition
Apr 17, 2024Understanding the real world through point cloud video is a crucial aspect of robotics and autonomous driving systems. However, prevailing methods for 4D point cloud recognition have limitations due to sensor resolution, which leads to a lack of detailed information. Recent advances have shown that Vision-Language Models (VLM) pre-trained on web-scale text-image datasets can learn fine-grained visual concepts that can be transferred to various downstream tasks. However, effectively integrating VLM into the domain of 4D point clouds remains an unresolved problem. In this work, we propose the Vision-Language Models Goes 4D (VG4D) framework to transfer VLM knowledge from visual-text pre-trained models to a 4D point cloud network. Our approach involves aligning the 4D encoder's representation with a VLM to learn a shared visual and text space from training on large-scale image-text pairs. By transferring the knowledge of the VLM to the 4D encoder and combining the VLM, our VG4D achieves improved recognition performance. To enhance the 4D encoder, we modernize the classic dynamic point cloud backbone and propose an improved version of PSTNet, im-PSTNet, which can efficiently model point cloud videos. Experiments demonstrate that our method achieves state-of-the-art performance for action recognition on both the NTU RGB+D 60 dataset and the NTU RGB+D 120 dataset. Code is available at \url{https://github.com/Shark0-0/VG4D}.
Identity-aware Dual-constraint Network for Cloth-Changing Person Re-identification
Mar 13, 2024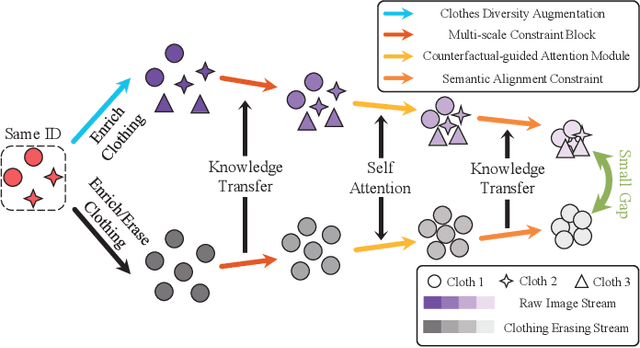

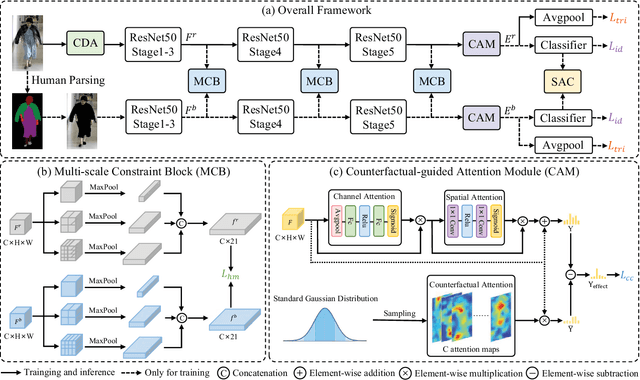
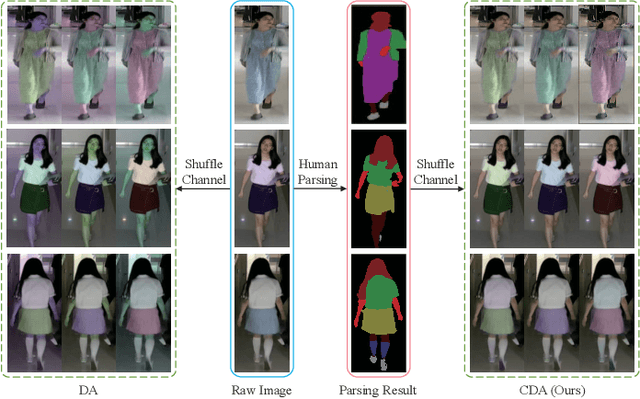
Cloth-Changing Person Re-Identification (CC-ReID) aims to accurately identify the target person in more realistic surveillance scenarios, where pedestrians usually change their clothing. Despite great progress, limited cloth-changing training samples in existing CC-ReID datasets still prevent the model from adequately learning cloth-irrelevant features. In addition, due to the absence of explicit supervision to keep the model constantly focused on cloth-irrelevant areas, existing methods are still hampered by the disruption of clothing variations. To solve the above issues, we propose an Identity-aware Dual-constraint Network (IDNet) for the CC-ReID task. Specifically, to help the model extract cloth-irrelevant clues, we propose a Clothes Diversity Augmentation (CDA), which generates more realistic cloth-changing samples by enriching the clothing color while preserving the texture. In addition, a Multi-scale Constraint Block (MCB) is designed, which extracts fine-grained identity-related features and effectively transfers cloth-irrelevant knowledge. Moreover, a Counterfactual-guided Attention Module (CAM) is presented, which learns cloth-irrelevant features from channel and space dimensions and utilizes the counterfactual intervention for supervising the attention map to highlight identity-related regions. Finally, a Semantic Alignment Constraint (SAC) is designed to facilitate high-level semantic feature interaction. Comprehensive experiments on four CC-ReID datasets indicate that our method outperforms prior state-of-the-art approaches.
Key-Graph Transformer for Image Restoration
Feb 04, 2024While it is crucial to capture global information for effective image restoration (IR), integrating such cues into transformer-based methods becomes computationally expensive, especially with high input resolution. Furthermore, the self-attention mechanism in transformers is prone to considering unnecessary global cues from unrelated objects or regions, introducing computational inefficiencies. In response to these challenges, we introduce the Key-Graph Transformer (KGT) in this paper. Specifically, KGT views patch features as graph nodes. The proposed Key-Graph Constructor efficiently forms a sparse yet representative Key-Graph by selectively connecting essential nodes instead of all the nodes. Then the proposed Key-Graph Attention is conducted under the guidance of the Key-Graph only among selected nodes with linear computational complexity within each window. Extensive experiments across 6 IR tasks confirm the proposed KGT's state-of-the-art performance, showcasing advancements both quantitatively and qualitatively.
Uncertainty-Aware Testing-Time Optimization for 3D Human Pose Estimation
Feb 04, 2024Although data-driven methods have achieved success in 3D human pose estimation, they often suffer from domain gaps and exhibit limited generalization. In contrast, optimization-based methods excel in fine-tuning for specific cases but are generally inferior to data-driven methods in overall performance. We observe that previous optimization-based methods commonly rely on projection constraint, which only ensures alignment in 2D space, potentially leading to the overfitting problem. To address this, we propose an Uncertainty-Aware testing-time Optimization (UAO) framework, which keeps the prior information of pre-trained model and alleviates the overfitting problem using the uncertainty of joints. Specifically, during the training phase, we design an effective 2D-to-3D network for estimating the corresponding 3D pose while quantifying the uncertainty of each 3D joint. For optimization during testing, the proposed optimization framework freezes the pre-trained model and optimizes only a latent state. Projection loss is then employed to ensure the generated poses are well aligned in 2D space for high-quality optimization. Furthermore, we utilize the uncertainty of each joint to determine how much each joint is allowed for optimization. The effectiveness and superiority of the proposed framework are validated through extensive experiments on two challenging datasets: Human3.6M and MPI-INF-3DHP. Notably, our approach outperforms the previous best result by a large margin of 4.5% on Human3.6M. Our source code will be open-sourced.