 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRita Cucchiara
AIGeN: An Adversarial Approach for Instruction Generation in VLN
Apr 15, 2024
In the last few years, the research interest in Vision-and-Language Navigation (VLN) has grown significantly. VLN is a challenging task that involves an agent following human instructions and navigating in a previously unknown environment to reach a specified goal. Recent work in literature focuses on different ways to augment the available datasets of instructions for improving navigation performance by exploiting synthetic training data. In this work, we propose AIGeN, a novel architecture inspired by Generative Adversarial Networks (GANs) that produces meaningful and well-formed synthetic instructions to improve navigation agents' performance. The model is composed of a Transformer decoder (GPT-2) and a Transformer encoder (BERT). During the training phase, the decoder generates sentences for a sequence of images describing the agent's path to a particular point while the encoder discriminates between real and fake instructions. Experimentally, we evaluate the quality of the generated instructions and perform extensive ablation studies. Additionally, we generate synthetic instructions for 217K trajectories using AIGeN on Habitat-Matterport 3D Dataset (HM3D) and show an improvement in the performance of an off-the-shelf VLN method. The validation analysis of our proposal is conducted on REVERIE and R2R and highlights the promising aspects of our proposal, achieving state-of-the-art performance.
Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation
Apr 09, 2024Open-vocabulary semantic segmentation aims at segmenting arbitrary categories expressed in textual form. Previous works have trained over large amounts of image-caption pairs to enforce pixel-level multimodal alignments. However, captions provide global information about the semantics of a given image but lack direct localization of individual concepts. Further, training on large-scale datasets inevitably brings significant computational costs. In this paper, we propose FreeDA, a training-free diffusion-augmented method for open-vocabulary semantic segmentation, which leverages the ability of diffusion models to visually localize generated concepts and local-global similarities to match class-agnostic regions with semantic classes. Our approach involves an offline stage in which textual-visual reference embeddings are collected, starting from a large set of captions and leveraging visual and semantic contexts. At test time, these are queried to support the visual matching process, which is carried out by jointly considering class-agnostic regions and global semantic similarities. Extensive analyses demonstrate that FreeDA achieves state-of-the-art performance on five datasets, surpassing previous methods by more than 7.0 average points in terms of mIoU and without requiring any training.
Multimodal-Conditioned Latent Diffusion Models for Fashion Image Editing
Mar 25, 2024Fashion illustration is a crucial medium for designers to convey their creative vision and transform design concepts into tangible representations that showcase the interplay between clothing and the human body. In the context of fashion design, computer vision techniques have the potential to enhance and streamline the design process. Departing from prior research primarily focused on virtual try-on, this paper tackles the task of multimodal-conditioned fashion image editing. Our approach aims to generate human-centric fashion images guided by multimodal prompts, including text, human body poses, garment sketches, and fabric textures. To address this problem, we propose extending latent diffusion models to incorporate these multiple modalities and modifying the structure of the denoising network, taking multimodal prompts as input. To condition the proposed architecture on fabric textures, we employ textual inversion techniques and let diverse cross-attention layers of the denoising network attend to textual and texture information, thus incorporating different granularity conditioning details. Given the lack of datasets for the task, we extend two existing fashion datasets, Dress Code and VITON-HD, with multimodal annotations. Experimental evaluations demonstrate the effectiveness of our proposed approach in terms of realism and coherence concerning the provided multimodal inputs.
Unveiling the Truth: Exploring Human Gaze Patterns in Fake Images
Mar 13, 2024
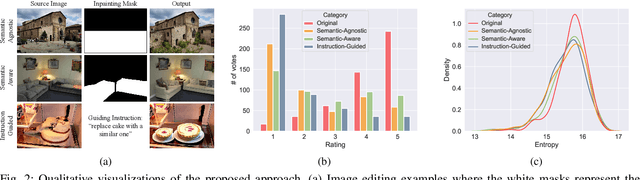
Creating high-quality and realistic images is now possible thanks to the impressive advancements in image generation. A description in natural language of your desired output is all you need to obtain breathtaking results. However, as the use of generative models grows, so do concerns about the propagation of malicious content and misinformation. Consequently, the research community is actively working on the development of novel fake detection techniques, primarily focusing on low-level features and possible fingerprints left by generative models during the image generation process. In a different vein, in our work, we leverage human semantic knowledge to investigate the possibility of being included in frameworks of fake image detection. To achieve this, we collect a novel dataset of partially manipulated images using diffusion models and conduct an eye-tracking experiment to record the eye movements of different observers while viewing real and fake stimuli. A preliminary statistical analysis is conducted to explore the distinctive patterns in how humans perceive genuine and altered images. Statistical findings reveal that, when perceiving counterfeit samples, humans tend to focus on more confined regions of the image, in contrast to the more dispersed observational pattern observed when viewing genuine images. Our dataset is publicly available at: https://github.com/aimagelab/unveiling-the-truth.
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Mar 11, 2024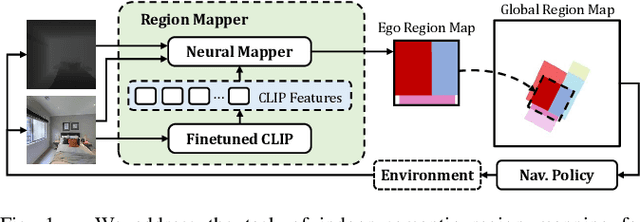

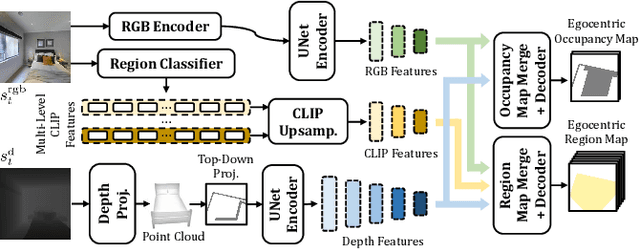
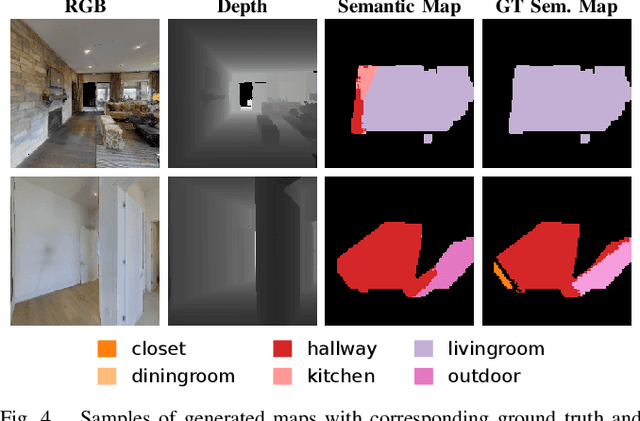
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
Trends, Applications, and Challenges in Human Attention Modelling
Feb 28, 2024Human attention modelling has proven, in recent years, to be particularly useful not only for understanding the cognitive processes underlying visual exploration, but also for providing support to artificial intelligence models that aim to solve problems in various domains, including image and video processing, vision-and-language applications, and language modelling. This survey offers a reasoned overview of recent efforts to integrate human attention mechanisms into contemporary deep learning models and discusses future research directions and challenges. For a comprehensive overview on the ongoing research refer to our dedicated repository available at https://github.com/aimagelab/awesome-human-visual-attention.
The (R)Evolution of Multimodal Large Language Models: A Survey
Feb 19, 2024Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, both as input and output, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
VATr++: Choose Your Words Wisely for Handwritten Text Generation
Feb 16, 2024Styled Handwritten Text Generation (HTG) has received significant attention in recent years, propelled by the success of learning-based solutions employing GANs, Transformers, and, preliminarily, Diffusion Models. Despite this surge in interest, there remains a critical yet understudied aspect - the impact of the input, both visual and textual, on the HTG model training and its subsequent influence on performance. This study delves deeper into a cutting-edge Styled-HTG approach, proposing strategies for input preparation and training regularization that allow the model to achieve better performance and generalize better. These aspects are validated through extensive analysis on several different settings and datasets. Moreover, in this work, we go beyond performance optimization and address a significant hurdle in HTG research - the lack of a standardized evaluation protocol. In particular, we propose a standardization of the evaluation protocol for HTG and conduct a comprehensive benchmarking of existing approaches. By doing so, we aim to establish a foundation for fair and meaningful comparisons between HTG strategies, fostering progress in the field.
Key-Graph Transformer for Image Restoration
Feb 04, 2024While it is crucial to capture global information for effective image restoration (IR), integrating such cues into transformer-based methods becomes computationally expensive, especially with high input resolution. Furthermore, the self-attention mechanism in transformers is prone to considering unnecessary global cues from unrelated objects or regions, introducing computational inefficiencies. In response to these challenges, we introduce the Key-Graph Transformer (KGT) in this paper. Specifically, KGT views patch features as graph nodes. The proposed Key-Graph Constructor efficiently forms a sparse yet representative Key-Graph by selectively connecting essential nodes instead of all the nodes. Then the proposed Key-Graph Attention is conducted under the guidance of the Key-Graph only among selected nodes with linear computational complexity within each window. Extensive experiments across 6 IR tasks confirm the proposed KGT's state-of-the-art performance, showcasing advancements both quantitatively and qualitatively.
DistFormer: Enhancing Local and Global Features for Monocular Per-Object Distance Estimation
Jan 06, 2024Accurate per-object distance estimation is crucial in safety-critical applications such as autonomous driving, surveillance, and robotics. Existing approaches rely on two scales: local information (i.e., the bounding box proportions) or global information, which encodes the semantics of the scene as well as the spatial relations with neighboring objects. However, these approaches may struggle with long-range objects and in the presence of strong occlusions or unusual visual patterns. In this respect, our work aims to strengthen both local and global cues. Our architecture -- named DistFormer -- builds upon three major components acting jointly: i) a robust context encoder extracting fine-grained per-object representations; ii) a masked encoder-decoder module exploiting self-supervision to promote the learning of useful per-object features; iii) a global refinement module that aggregates object representations and computes a joint, spatially-consistent estimation. To evaluate the effectiveness of DistFormer, we conduct experiments on the standard KITTI dataset and the large-scale NuScenes and MOTSynth datasets. Such datasets cover various indoor/outdoor environments, changing weather conditions, appearances, and camera viewpoints. Our comprehensive analysis shows that DistFormer outperforms existing methods. Moreover, we further delve into its generalization capabilities, showing its regularization benefits in zero-shot synth-to-real transfer.