 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoachim M. Buhmann
Point-In-Context: Understanding Point Cloud via In-Context Learning
Apr 18, 2024
With the emergence of large-scale models trained on diverse datasets, in-context learning has emerged as a promising paradigm for multitasking, notably in natural language processing and image processing. However, its application in 3D point cloud tasks remains largely unexplored. In this work, we introduce Point-In-Context (PIC), a novel framework for 3D point cloud understanding via in-context learning. We address the technical challenge of effectively extending masked point modeling to 3D point clouds by introducing a Joint Sampling module and proposing a vanilla version of PIC called Point-In-Context-Generalist (PIC-G). PIC-G is designed as a generalist model for various 3D point cloud tasks, with inputs and outputs modeled as coordinates. In this paradigm, the challenging segmentation task is achieved by assigning label points with XYZ coordinates for each category; the final prediction is then chosen based on the label point closest to the predictions. To break the limitation by the fixed label-coordinate assignment, which has poor generalization upon novel classes, we propose two novel training strategies, In-Context Labeling and In-Context Enhancing, forming an extended version of PIC named Point-In-Context-Segmenter (PIC-S), targeting improving dynamic context labeling and model training. By utilizing dynamic in-context labels and extra in-context pairs, PIC-S achieves enhanced performance and generalization capability in and across part segmentation datasets. PIC is a general framework so that other tasks or datasets can be seamlessly introduced into our PIC through a unified data format. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks and segmenting multi-datasets. Our PIC-S is capable of generalizing unseen datasets and performing novel part segmentation by customizing prompts.
Non-linear Fusion in Federated Learning: A Hypernetwork Approach to Federated Domain Generalization
Feb 13, 2024Federated Learning (FL) has emerged as a promising paradigm in which multiple clients collaboratively train a shared global model while preserving data privacy. To create a robust and practicable FL framework, it is crucial to extend its ability to generalize well to unseen domains - a problem referred to as federated Domain Generalization (FDG), being still under-explored. We propose an innovative federated algorithm, termed hFedF for hypernetwork-based Federated Fusion, designed to bridge the performance gap between generalization and personalization, capable of addressing various degrees of domain shift. Essentially, the hypernetwork supports a non-linear fusion of client models enabling a comprehensive understanding of the underlying data distribution. We encompass an extensive discussion and provide novel insights into the tradeoff between personalization and generalization in FL. The proposed algorithm outperforms strong benchmarks on three widely-used data sets for DG in an exceeding number of cases.
Invariant Anomaly Detection under Distribution Shifts: A Causal Perspective
Dec 21, 2023Anomaly detection (AD) is the machine learning task of identifying highly discrepant abnormal samples by solely relying on the consistency of the normal training samples. Under the constraints of a distribution shift, the assumption that training samples and test samples are drawn from the same distribution breaks down. In this work, by leveraging tools from causal inference we attempt to increase the resilience of anomaly detection models to different kinds of distribution shifts. We begin by elucidating a simple yet necessary statistical property that ensures invariant representations, which is critical for robust AD under both domain and covariate shifts. From this property, we derive a regularization term which, when minimized, leads to partial distribution invariance across environments. Through extensive experimental evaluation on both synthetic and real-world tasks, covering a range of six different AD methods, we demonstrated significant improvements in out-of-distribution performance. Under both covariate and domain shift, models regularized with our proposed term showed marked increased robustness. Code is available at: https://github.com/JoaoCarv/invariant-anomaly-detection.
Regularizing Adversarial Imitation Learning Using Causal Invariance
Aug 17, 2023


Imitation learning methods are used to infer a policy in a Markov decision process from a dataset of expert demonstrations by minimizing a divergence measure between the empirical state occupancy measures of the expert and the policy. The guiding signal to the policy is provided by the discriminator used as part of an versarial optimization procedure. We observe that this model is prone to absorbing spurious correlations present in the expert data. To alleviate this issue, we propose to use causal invariance as a regularization principle for adversarial training of these models. The regularization objective is applicable in a straightforward manner to existing adversarial imitation frameworks. We demonstrate the efficacy of the regularized formulation in an illustrative two-dimensional setting as well as a number of high-dimensional robot locomotion benchmark tasks.
Improving Explainability of Disentangled Representations using Multipath-Attribution Mappings
Jun 15, 2023
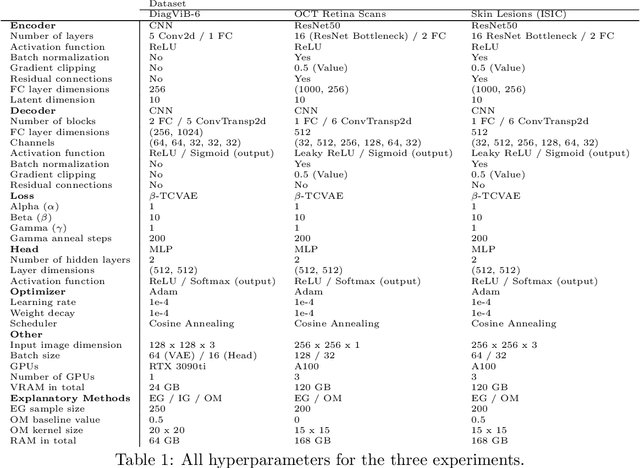

Explainable AI aims to render model behavior understandable by humans, which can be seen as an intermediate step in extracting causal relations from correlative patterns. Due to the high risk of possible fatal decisions in image-based clinical diagnostics, it is necessary to integrate explainable AI into these safety-critical systems. Current explanatory methods typically assign attribution scores to pixel regions in the input image, indicating their importance for a model's decision. However, they fall short when explaining why a visual feature is used. We propose a framework that utilizes interpretable disentangled representations for downstream-task prediction. Through visualizing the disentangled representations, we enable experts to investigate possible causation effects by leveraging their domain knowledge. Additionally, we deploy a multi-path attribution mapping for enriching and validating explanations. We demonstrate the effectiveness of our approach on a synthetic benchmark suite and two medical datasets. We show that the framework not only acts as a catalyst for causal relation extraction but also enhances model robustness by enabling shortcut detection without the need for testing under distribution shifts.
Explore In-Context Learning for 3D Point Cloud Understanding
Jun 14, 2023
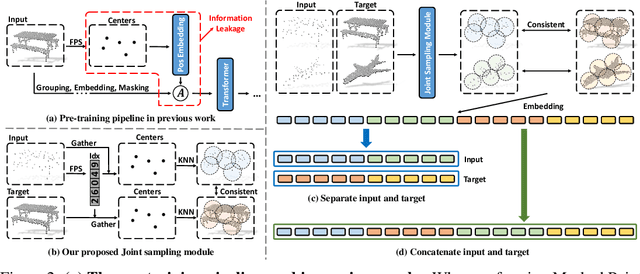
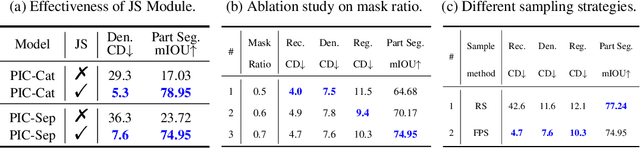
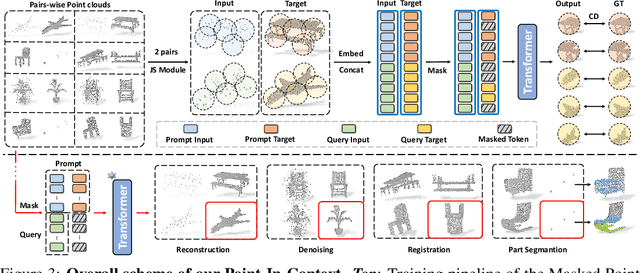
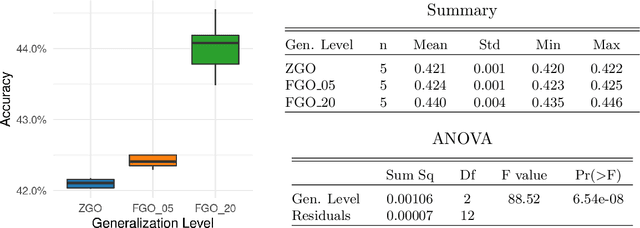
With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks. Meanwhile, in-context learning is still largely unexplored in the 3D point cloud domain. Although masked modeling has been successfully applied for in-context learning in 2D vision, directly extending it to 3D point clouds remains a formidable challenge. In the case of point clouds, the tokens themselves are the point cloud positions (coordinates) that are masked during inference. Moreover, position embedding in previous works may inadvertently introduce information leakage. To address these challenges, we introduce a novel framework, named Point-In-Context, designed especially for in-context learning in 3D point clouds, where both inputs and outputs are modeled as coordinates for each task. Additionally, we propose the Joint Sampling module, carefully designed to work in tandem with the general point sampling operator, effectively resolving the aforementioned technical issues. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks. Furthermore, with a more effective prompt selection strategy, our framework surpasses the results of individually trained models.
How to Enable Uncertainty Estimation in Proximal Policy Optimization
Oct 07, 2022
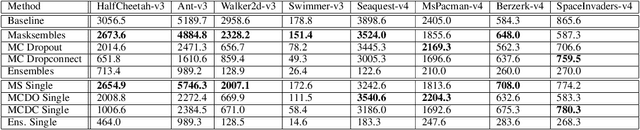

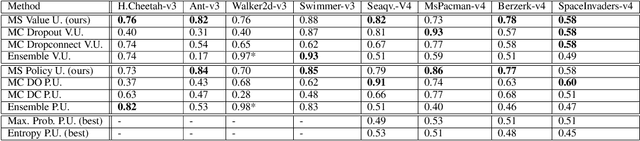
While deep reinforcement learning (RL) agents have showcased strong results across many domains, a major concern is their inherent opaqueness and the safety of such systems in real-world use cases. To overcome these issues, we need agents that can quantify their uncertainty and detect out-of-distribution (OOD) states. Existing uncertainty estimation techniques, like Monte-Carlo Dropout or Deep Ensembles, have not seen widespread adoption in on-policy deep RL. We posit that this is due to two reasons: concepts like uncertainty and OOD states are not well defined compared to supervised learning, especially for on-policy RL methods. Secondly, available implementations and comparative studies for uncertainty estimation methods in RL have been limited. To overcome the first gap, we propose definitions of uncertainty and OOD for Actor-Critic RL algorithms, namely, proximal policy optimization (PPO), and present possible applicable measures. In particular, we discuss the concepts of value and policy uncertainty. The second point is addressed by implementing different uncertainty estimation methods and comparing them across a number of environments. The OOD detection performance is evaluated via a custom evaluation benchmark of in-distribution (ID) and OOD states for various RL environments. We identify a trade-off between reward and OOD detection performance. To overcome this, we formulate a Pareto optimization problem in which we simultaneously optimize for reward and OOD detection performance. We show experimentally that the recently proposed method of Masksembles strikes a favourable balance among the survey methods, enabling high-quality uncertainty estimation and OOD detection while matching the performance of original RL agents.
Learning to Drop Out: An Adversarial Approach to Training Sequence VAEs
Sep 26, 2022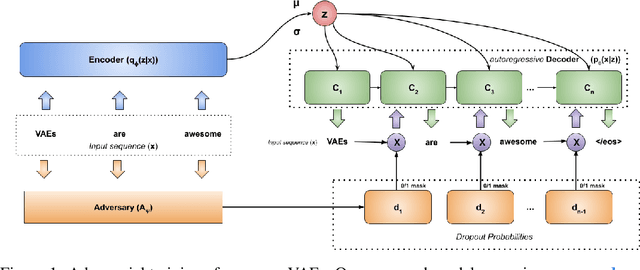
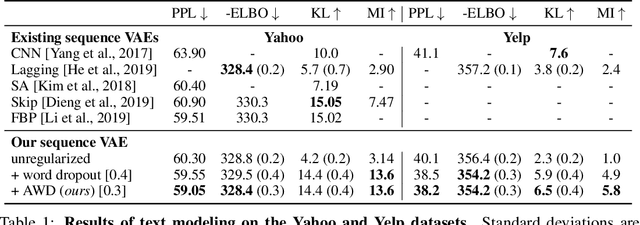
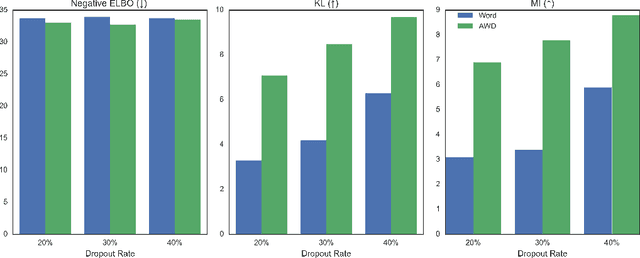

In principle, applying variational autoencoders (VAEs) to sequential data offers a method for controlled sequence generation, manipulation, and structured representation learning. However, training sequence VAEs is challenging: autoregressive decoders can often explain the data without utilizing the latent space, known as posterior collapse. To mitigate this, state-of-the-art models weaken the powerful decoder by applying uniformly random dropout to the decoder input. We show theoretically that this removes pointwise mutual information provided by the decoder input, which is compensated for by utilizing the latent space. We then propose an adversarial training strategy to achieve information-based stochastic dropout. Compared to uniform dropout on standard text benchmark datasets, our targeted approach increases both sequence modeling performance and the information captured in the latent space.
BARReL: Bottleneck Attention for Adversarial Robustness in Vision-Based Reinforcement Learning
Aug 22, 2022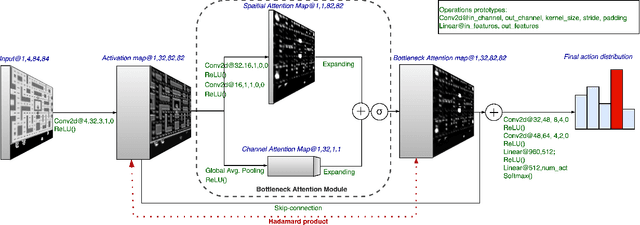



Robustness to adversarial perturbations has been explored in many areas of computer vision. This robustness is particularly relevant in vision-based reinforcement learning, as the actions of autonomous agents might be safety-critic or impactful in the real world. We investigate the susceptibility of vision-based reinforcement learning agents to gradient-based adversarial attacks and evaluate a potential defense. We observe that Bottleneck Attention Modules (BAM) included in CNN architectures can act as potential tools to increase robustness against adversarial attacks. We show how learned attention maps can be used to recover activations of a convolutional layer by restricting the spatial activations to salient regions. Across a number of RL environments, BAM-enhanced architectures show increased robustness during inference. Finally, we discuss potential future research directions.
Gated Domain Units for Multi-source Domain Generalization
Jun 24, 2022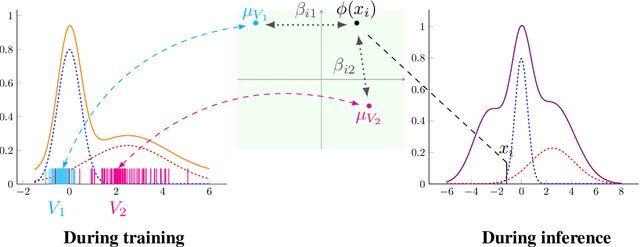

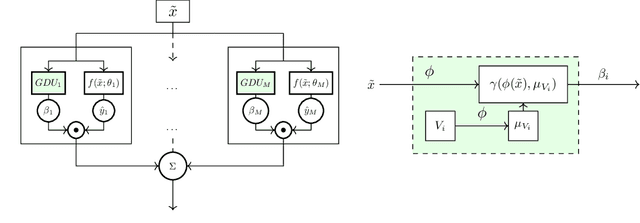
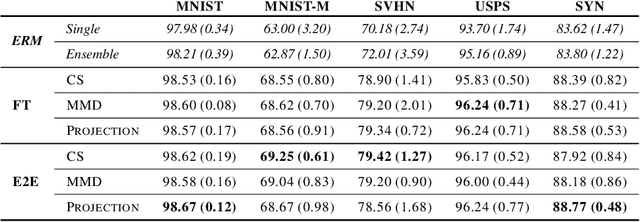
Distribution shift (DS) is a common problem that deteriorates the performance of learning machines. To overcome this problem, we postulate that real-world distributions are composed of elementary distributions that remain invariant across different domains. We call this an invariant elementary distribution (I.E.D.) assumption. This invariance thus enables knowledge transfer to unseen domains. To exploit this assumption in domain generalization (DG), we developed a modular neural network layer that consists of Gated Domain Units (GDUs). Each GDU learns an embedding of an individual elementary domain that allows us to encode the domain similarities during the training. During inference, the GDUs compute similarities between an observation and each of the corresponding elementary distributions which are then used to form a weighted ensemble of learning machines. Because our layer is trained with backpropagation, it can be easily integrated into existing deep learning frameworks. Our evaluation on Digits5, ECG, Camelyon17, iWildCam, and FMoW shows a significant improvement in the performance on out-of-training target domains without any access to data from the target domains. This finding supports the validity of the I.E.D. assumption in real-world data distributions.