 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinqiu Sun
The Third Monocular Depth Estimation Challenge
Apr 27, 2024
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
GoMVS: Geometrically Consistent Cost Aggregation for Multi-View Stereo
Apr 11, 2024Matching cost aggregation plays a fundamental role in learning-based multi-view stereo networks. However, directly aggregating adjacent costs can lead to suboptimal results due to local geometric inconsistency. Related methods either seek selective aggregation or improve aggregated depth in the 2D space, both are unable to handle geometric inconsistency in the cost volume effectively. In this paper, we propose GoMVS to aggregate geometrically consistent costs, yielding better utilization of adjacent geometries. More specifically, we correspond and propagate adjacent costs to the reference pixel by leveraging the local geometric smoothness in conjunction with surface normals. We achieve this by the geometric consistent propagation (GCP) module. It computes the correspondence from the adjacent depth hypothesis space to the reference depth space using surface normals, then uses the correspondence to propagate adjacent costs to the reference geometry, followed by a convolution for aggregation. Our method achieves new state-of-the-art performance on DTU, Tanks & Temple, and ETH3D datasets. Notably, our method ranks 1st on the Tanks & Temple Advanced benchmark.
Boosting Multi-view Stereo with Late Cost Aggregation
Jan 24, 2024Pairwise matching cost aggregation is a crucial step for modern learning-based Multi-view Stereo (MVS). Prior works adopt an early aggregation scheme, which adds up pairwise costs into an intermediate cost. However, we analyze that this process can degrade informative pairwise matchings, thereby blocking the depth network from fully utilizing the original geometric matching cues. To address this challenge, we present a late aggregation approach that allows for aggregating pairwise costs throughout the network feed-forward process, achieving accurate estimations with only minor changes of the plain CasMVSNet. Instead of building an intermediate cost by weighted sum, late aggregation preserves all pairwise costs along a distinct view channel. This enables the succeeding depth network to fully utilize the crucial geometric cues without loss of cost fidelity. Grounded in the new aggregation scheme, we propose further techniques addressing view order dependence inside the preserved cost, handling flexible testing views, and improving the depth filtering process. Despite its technical simplicity, our method improves significantly upon the baseline cascade-based approach, achieving comparable results with state-of-the-art methods with favorable computation overhead.
DifAugGAN: A Practical Diffusion-style Data Augmentation for GAN-based Single Image Super-resolution
Nov 30, 2023
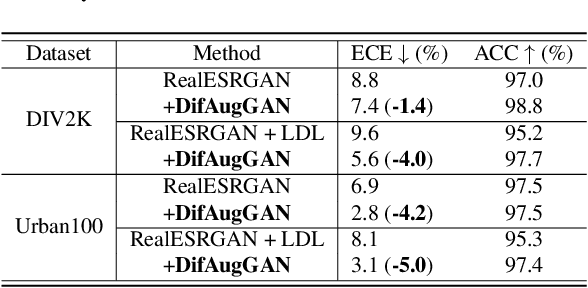
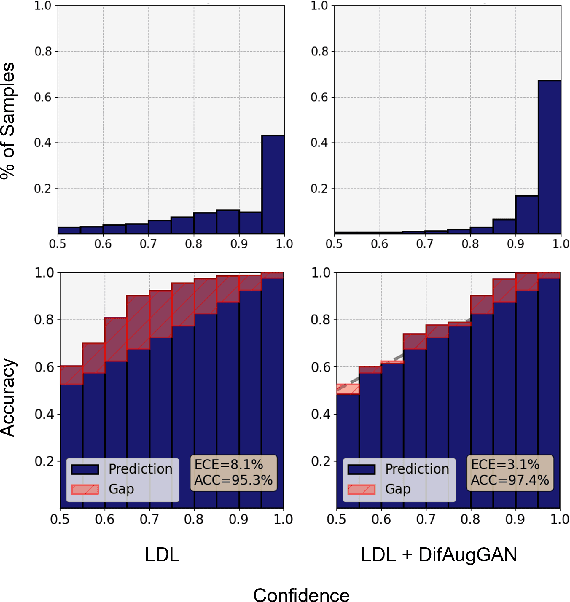
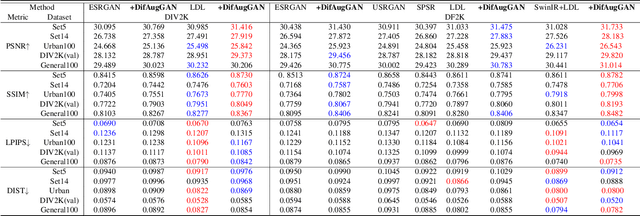
It is well known the adversarial optimization of GAN-based image super-resolution (SR) methods makes the preceding SR model generate unpleasant and undesirable artifacts, leading to large distortion. We attribute the cause of such distortions to the poor calibration of the discriminator, which hampers its ability to provide meaningful feedback to the generator for learning high-quality images. To address this problem, we propose a simple but non-travel diffusion-style data augmentation scheme for current GAN-based SR methods, known as DifAugGAN. It involves adapting the diffusion process in generative diffusion models for improving the calibration of the discriminator during training motivated by the successes of data augmentation schemes in the field to achieve good calibration. Our DifAugGAN can be a Plug-and-Play strategy for current GAN-based SISR methods to improve the calibration of the discriminator and thus improve SR performance. Extensive experimental evaluations demonstrate the superiority of DifAugGAN over state-of-the-art GAN-based SISR methods across both synthetic and real-world datasets, showcasing notable advancements in both qualitative and quantitative results.
Multiple Object Tracking based on Occlusion-Aware Embedding Consistency Learning
Nov 05, 2023The Joint Detection and Embedding (JDE) framework has achieved remarkable progress for multiple object tracking. Existing methods often employ extracted embeddings to re-establish associations between new detections and previously disrupted tracks. However, the reliability of embeddings diminishes when the region of the occluded object frequently contains adjacent objects or clutters, especially in scenarios with severe occlusion. To alleviate this problem, we propose a novel multiple object tracking method based on visual embedding consistency, mainly including: 1) Occlusion Prediction Module (OPM) and 2) Occlusion-Aware Association Module (OAAM). The OPM predicts occlusion information for each true detection, facilitating the selection of valid samples for consistency learning of the track's visual embedding. The OAAM leverages occlusion cues and visual embeddings to generate two separate embeddings for each track, guaranteeing consistency in both unoccluded and occluded detections. By integrating these two modules, our method is capable of addressing track interruptions caused by occlusion in online tracking scenarios. Extensive experimental results demonstrate that our approach achieves promising performance levels in both unoccluded and occluded tracking scenarios.
All-in-one Multi-degradation Image Restoration Network via Hierarchical Degradation Representation
Aug 06, 2023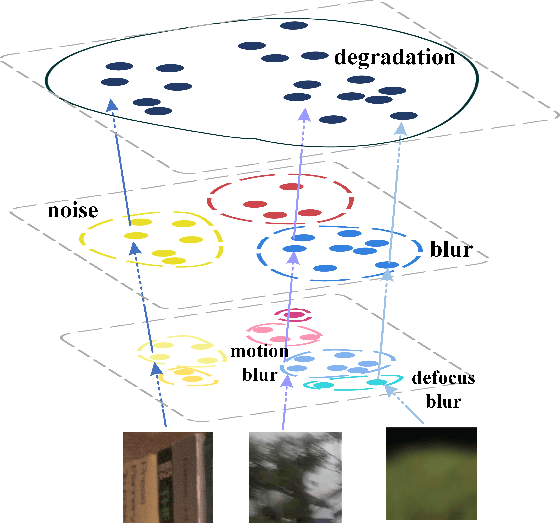

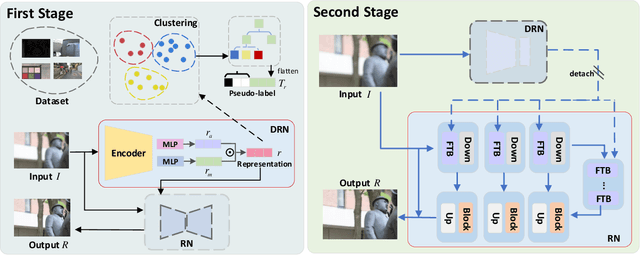
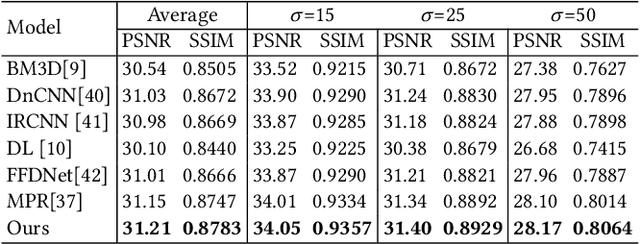
The aim of image restoration is to recover high-quality images from distorted ones. However, current methods usually focus on a single task (\emph{e.g.}, denoising, deblurring or super-resolution) which cannot address the needs of real-world multi-task processing, especially on mobile devices. Thus, developing an all-in-one method that can restore images from various unknown distortions is a significant challenge. Previous works have employed contrastive learning to learn the degradation representation from observed images, but this often leads to representation drift caused by deficient positive and negative pairs. To address this issue, we propose a novel All-in-one Multi-degradation Image Restoration Network (AMIRNet) that can effectively capture and utilize accurate degradation representation for image restoration. AMIRNet learns a degradation representation for unknown degraded images by progressively constructing a tree structure through clustering, without any prior knowledge of degradation information. This tree-structured representation explicitly reflects the consistency and discrepancy of various distortions, providing a specific clue for image restoration. To further enhance the performance of the image restoration network and overcome domain gaps caused by unknown distortions, we design a feature transform block (FTB) that aligns domains and refines features with the guidance of the degradation representation. We conduct extensive experiments on multiple distorted datasets, demonstrating the effectiveness of our method and its advantages over state-of-the-art restoration methods both qualitatively and quantitatively.
ACDMSR: Accelerated Conditional Diffusion Models for Single Image Super-Resolution
Jul 03, 2023



Diffusion models have gained significant popularity in the field of image-to-image translation. Previous efforts applying diffusion models to image super-resolution (SR) have demonstrated that iteratively refining pure Gaussian noise using a U-Net architecture trained on denoising at various noise levels can yield satisfactory high-resolution images from low-resolution inputs. However, this iterative refinement process comes with the drawback of low inference speed, which strongly limits its applications. To speed up inference and further enhance the performance, our research revisits diffusion models in image super-resolution and proposes a straightforward yet significant diffusion model-based super-resolution method called ACDMSR (accelerated conditional diffusion model for image super-resolution). Specifically, our method adapts the standard diffusion model to perform super-resolution through a deterministic iterative denoising process. Our study also highlights the effectiveness of using a pre-trained SR model to provide the conditional image of the given low-resolution (LR) image to achieve superior high-resolution results. We demonstrate that our method surpasses previous attempts in qualitative and quantitative results through extensive experiments conducted on benchmark datasets such as Set5, Set14, Urban100, BSD100, and Manga109. Moreover, our approach generates more visually realistic counterparts for low-resolution images, emphasizing its effectiveness in practical scenarios.
Learning from Multi-Perception Features for Real-Word Image Super-resolution
May 26, 2023



Currently, there are two popular approaches for addressing real-world image super-resolution problems: degradation-estimation-based and blind-based methods. However, degradation-estimation-based methods may be inaccurate in estimating the degradation, making them less applicable to real-world LR images. On the other hand, blind-based methods are often limited by their fixed single perception information, which hinders their ability to handle diverse perceptual characteristics. To overcome this limitation, we propose a novel SR method called MPF-Net that leverages multiple perceptual features of input images. Our method incorporates a Multi-Perception Feature Extraction (MPFE) module to extract diverse perceptual information and a series of newly-designed Cross-Perception Blocks (CPB) to combine this information for effective super-resolution reconstruction. Additionally, we introduce a contrastive regularization term (CR) that improves the model's learning capability by using newly generated HR and LR images as positive and negative samples for ground truth HR. Experimental results on challenging real-world SR datasets demonstrate that our approach significantly outperforms existing state-of-the-art methods in both qualitative and quantitative measures.
Learning to Fuse Monocular and Multi-view Cues for Multi-frame Depth Estimation in Dynamic Scenes
Apr 18, 2023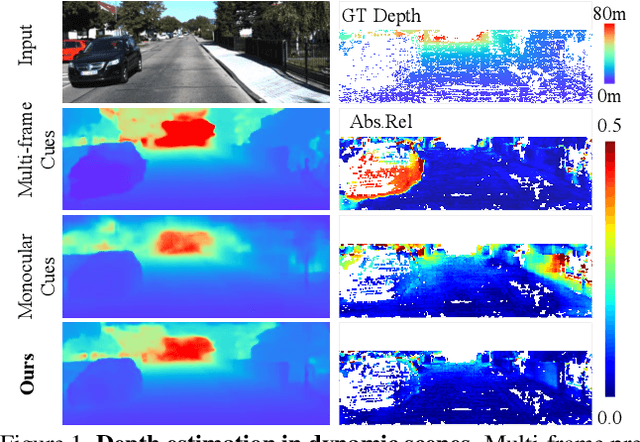
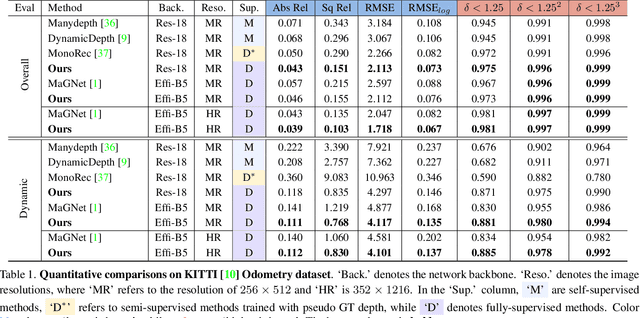


Multi-frame depth estimation generally achieves high accuracy relying on the multi-view geometric consistency. When applied in dynamic scenes, e.g., autonomous driving, this consistency is usually violated in the dynamic areas, leading to corrupted estimations. Many multi-frame methods handle dynamic areas by identifying them with explicit masks and compensating the multi-view cues with monocular cues represented as local monocular depth or features. The improvements are limited due to the uncontrolled quality of the masks and the underutilized benefits of the fusion of the two types of cues. In this paper, we propose a novel method to learn to fuse the multi-view and monocular cues encoded as volumes without needing the heuristically crafted masks. As unveiled in our analyses, the multi-view cues capture more accurate geometric information in static areas, and the monocular cues capture more useful contexts in dynamic areas. To let the geometric perception learned from multi-view cues in static areas propagate to the monocular representation in dynamic areas and let monocular cues enhance the representation of multi-view cost volume, we propose a cross-cue fusion (CCF) module, which includes the cross-cue attention (CCA) to encode the spatially non-local relative intra-relations from each source to enhance the representation of the other. Experiments on real-world datasets prove the significant effectiveness and generalization ability of the proposed method.